一個常見的技術誤區是,性能和復雜性直接相關。也就是說,高性能的實現也是實現和管理最具挑戰性的。但是,在考慮數據中心網絡時,情況并非如此。
與以太網相比,InfiniBand 可能聽起來令人生畏且新奇,但它實際上是更易于部署和維護的,因為它從一開始就是為了實現最高性能而設計的。當您考慮 AI 基礎設施的連接時,InfiniBand 集群操作和維護指南可以幫助您盡可能簡化全棧 InfiniBand 網絡的設置和操作。
本指南全面介紹了簡化網絡運營的基本步驟,特別詳細介紹了如何使用 NVIDIA Unified Fabric Manager(UFM)來協助初始配置和持續維護計劃,適用于第 0 天、第 1 天和第 2 天的網絡運營。
UFM 是一個功能強大的工具集,具有廣泛的遙測和分析功能。但是,開始使用 UFM 了解集群監控和管理的基礎知識不需要任何高級前提條件或專業知識。
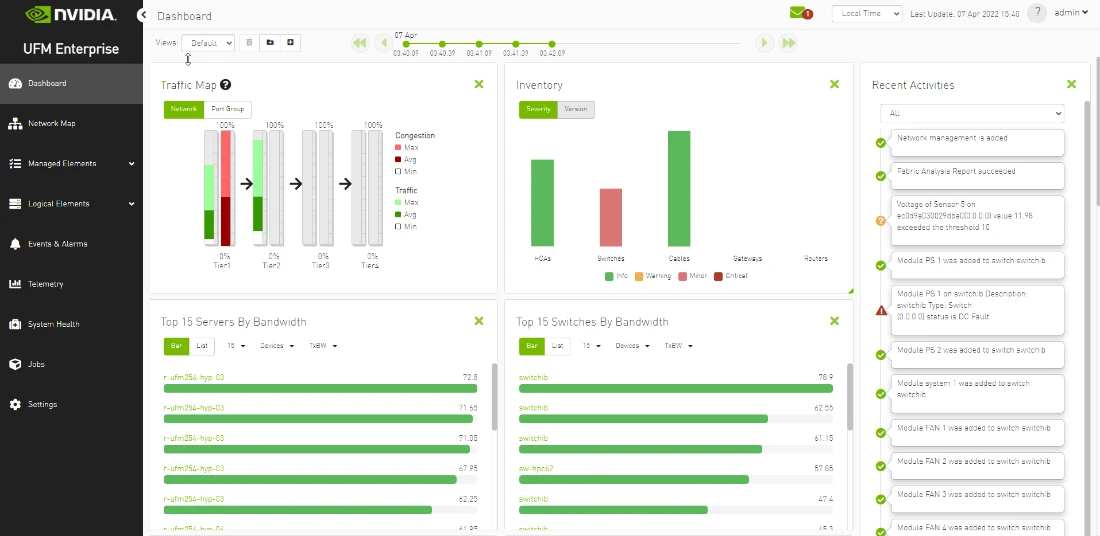
集群構建和操作
本指南將為您介紹啟動設置:
- 驗證 UFM 運行狀態
- 生成網絡運行狀況報告和拓撲驗證
- 驗證集群性能
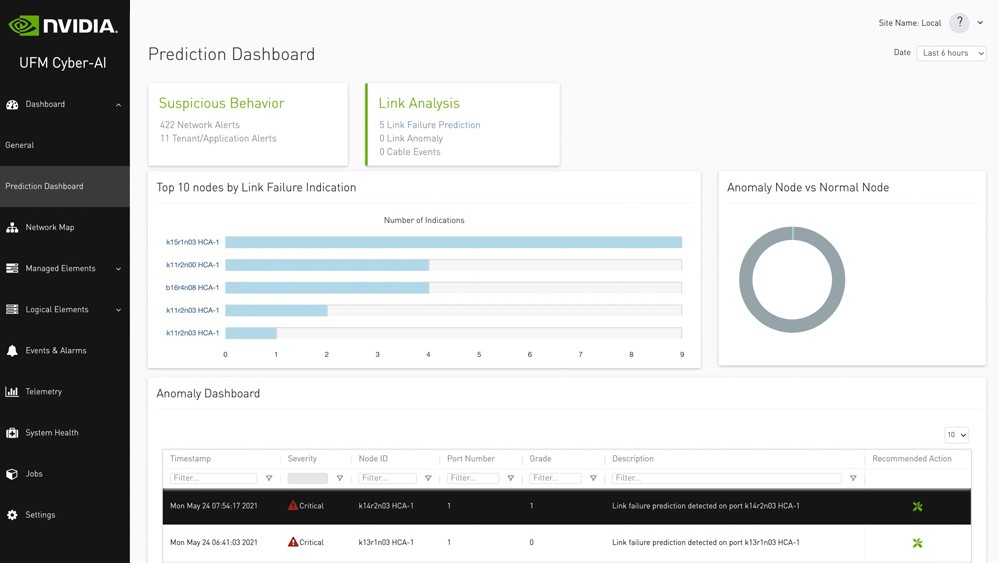
該指南還介紹了使用 UFM Telemetry 進行擁塞分析。UFM 遙測和監控功能非常強大。Grafana、Fluentd、Slurm 和 Zabbix 等工具的第三方插件使您能夠捕獲重要的網絡指標,并將其用于您選擇的平臺。
當管理員知道集群處于正常初始狀態時,本指南會建議集群維護機制,并提供定期維護檢查列表。
一分鐘/持續維護:
- 檢查故障排除列表中的場景,并按照說明進行解決。
每周維護:
- 監控鏈路監控關鍵指標的趨勢(可在 UFM 用戶界面中獲取)。
- 運行集群拓撲驗證檢查和網絡運行狀況驗證測試。
- 使用 ClusterKit (包含在 HPC-X 中)驗證性能 KPI 軟件包)。
- 檢查 UFM 中捕獲的溫差,確保您的冷卻系統正常工作。
季度/年度維護:
- 查看最新的固件和軟件版本說明,以及經過驗證的配置,并在可能的情況下進行升級。請訪問此鏈接獲取更多信息。
- 通過聯系 NVIDIA 網絡支持人員或您指定的 NVIDIA 聯系人,對 NVIDIA 網絡運行狀況進行年度審查
其中許多檢查都可以通過 API 實現自動化和配置。本指南提供了指向適當檢查的鏈接,UFM API 文檔 使這種設置變得簡單、無縫。
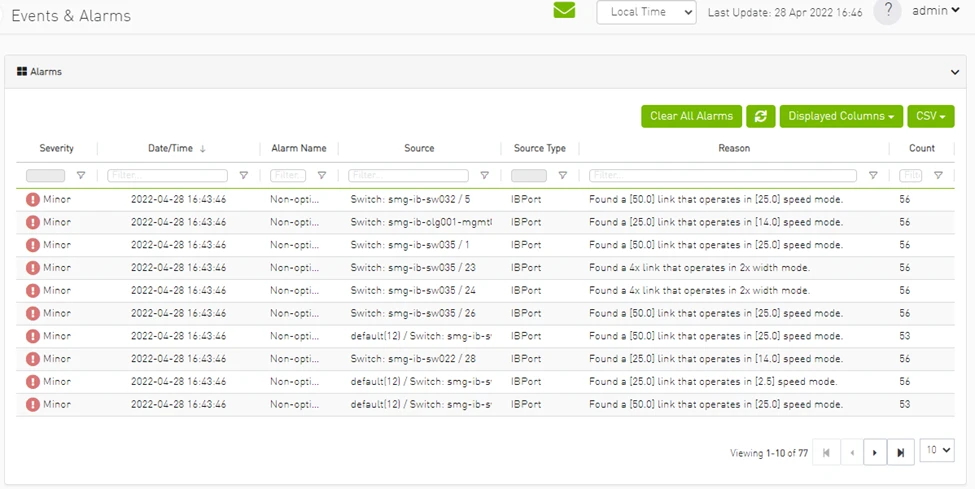
問題解決
當然,沒有完美的系統。即使是運行良好的機器(如 InfiniBand 集群),也經常會遇到意想不到的問題。
但是,作為管理員,集群維護指南是您的一站式商店。它包括一個章節,描述了最常見的場景,以及如何解決這些場景。本節包括場景以及如何檢測它(使用相應的 UFM 警報事件 ID),然后是達成解決方案的一系列步驟。它涵蓋了簡單和常見的錯誤,如端口錯誤、拍擊鏈路和線纜連接問題,以及性能降低或帶寬低等更復雜的挑戰。
總結
在構建網絡時,性能是一個關鍵的考慮因素,但不必將性能和易用性視為權衡。
InfiniBand 易于為 AI 采用、部署和操作。利用 UFM 的強大功能,集群操作和維護指南包含網絡管理員需要了解的所有內容。它比打開網絡認證課本簡單得多,因為集群指南不到 40 頁。
考慮為您的 AI 基礎架構選擇簡單易用的 NVIDIA Quantum InfiniBand.
?