零售商的供應鏈包括從供應商處采購原材料或成品;將其儲存在倉庫或配送中心;并將其運送至商店或顧客;管理銷售。他們還收集、存儲和分析數據,以優化供應鏈性能。
零售商有團隊負責管理供應鏈的每個階段,包括供應商管理、物流、庫存管理、銷售和數據分析。所有這些團隊和流程協同工作,以確保在正確的時間以正確的價格向客戶提供正確的產品。
通過收集、分析和解釋來自各種來源的數據,如銷售點( POS )系統、客戶數據庫和市場調查,對零售銷售和運營做出明智的決策是很重要的。
大數據處理是零售分析的一個關鍵組成部分,因為它使零售商能夠以低延遲處理和分析來自各種來源的大量數據。零售商可以獲得對客戶行為、市場趨勢和運營效率的寶貴見解。
這篇文章概述了可以從 Spark 加速的 Apache GPU 工作負載中受益的零售應用程序。我們通過一個示例零售用例提供了詳細的分步說明,說明如何在 Dataproc 上的 Spark 工作負載上開始使用 GPU 加速。該示例向您展示了如何加快零售商的數據處理管道。我們重點介紹了 Dataproc 的新 RAPIDS 加速器用戶工具,這些工具可以幫助您設置應用程序調優,還可以深入了解 GPU 的運行細節。
要繼續閱讀本文,請訪問 NVIDIA/spark-rapids-examples GitHub 存儲庫上的筆記本。

零售應用程序的數據分析類型
根據您的業務問題和目標,可以對零售數據執行幾種類型的復雜分析:
- Inventory forecasting: 分析銷售趨勢、需求和庫存數量,以預測未來的庫存需求。
- Demand forecasting: 預測未來客戶對產品的需求,以優化庫存水平、定價和促銷活動,從而滿足該需求。
- Price optimization: 分析競爭對手的價格、貨物成本和運輸成本,以確定每種產品的最佳價格。
- 銷售業績分析: 分析個人客戶的銷售狀態和購買歷史,以確定模式和目標營銷努力。
- Supply chain analysis: 分析供應商 ID 、運輸成本和倉庫成本,以確定節約成本和提高效率的機會。
- Customer segmentation: 分析客戶人口統計、購買歷史和聯系信息,以細分客戶和目標營銷工作。
- Product analysis: 分析不同產品的銷售情況,確定最暢銷的產品和潛在的新產品。
- Location analysis: 分析銷售地點,并確定可擴展到的潛在新地點。
- 零售降價優化: 分析大量數據,以取代手動降低產品價格的過程。
例如,您可以通過處理來自不同來源的最新產品銷售數據來優化店內或在線庫存水平。
零售數據源
零售數據可以來自多種來源:
- Sales data: 正在銷售的產品的數據,如產品名稱、價格、銷售數量和銷售日期。這些數據可以來自 POS 系統、在線銷售平臺或記錄銷售交易的其他系統。
- Stock data: 當前庫存產品的數據,如產品名稱、庫存數量、庫存位置和收到日期。這些數據可以來自庫存管理系統、倉庫管理系統或其他記錄庫存的系統。
- Supplier data: 從供應商處訂購的產品數據,如產品名稱、訂購數量、價格和下訂單日期。這些數據可以來自采購訂單系統、供應鏈管理系統或記錄供應商訂單的其他系統。
- Customer data: 客戶數據,如人口統計、購買歷史和聯系信息。這些數據可以來自客戶關系管理( CRM )系統、電子商務平臺或記錄客戶信息的其他系統。
- Market data: 關于市場狀況、競爭對手的價格、銷售趨勢和需求預測的數據。這些數據可以來自外部來源,如市場研究公司、政府機構或其他數據提供商。
- Logistic data: 航運、運輸和倉庫管理等物流數據。這些數據可以來自物流管理系統、運輸公司或其他記錄物流信息的系統。
來自這些來源的數據可能有不同的格式( CSV 、 JSON 、 Parquet 等)。
在本文中,您將使用合成數據生成器代碼來模擬前面解釋的數據源和格式。下面的 Python 代碼示例可以生成大量不同格式的合成銷售數據、庫存數據、供應商數據、客戶數據、市場數據和物流數據。有一些數據質量問題可以作為模擬目的的示例。
# generate sales data
# Define the generate_data function which takes an integer i as input and generates sales data using random numbers. The generated data includes sales ID, product name, price, quantity sold, date of sale, and customer ID. The function returns a tuple of the generated data. The multiprocessing library is used to generate the data in parallel
def generate_data(i):
sales_id = "s_{}".format(i)
product_name = "Product_{}".format(i)
price = random.uniform(1,100)
quantity_sold = random.randint(1,100)
date_of_sale = "2022-{}-{}".format(random.randint(1,12), random.randint(1,28))
customer_id = "c_{}".format(random.randint(1,1000000))
return (sales_id, product_name, price, quantity_sold, date_of_sale, customer_id)
with mp.Pool(mp.cpu_count()) as p:
sales_data = p.map(generate_data, range(100000000))
sales_data = list(sales_data)
print("write to gcs started")
sales_df = pd.DataFrame(sales_data, columns=["sales_id", "product_name", "price", "quantity_sold", "date_of_sale", "customer_id"])
sales_df.to_csv(dataRoot+"sales/data.csv", index=False, header=True)
print("Write to gcs completed")
訪問 spark-rapids-examples GitHub 存儲庫上的完整筆記本。
數據清理、轉換和集成
在將原始數據用于分析之前,可能必須對其進行清理、轉換和集成。這就是 Apache Spark SQL 和 DataFrame API 的用武之地,因為它們為處理結構化數據提供了一套強大的工具。他們可以處理來自不同來源的大量數據,以處理和提取有用的見解和信息。
首先,提取數據,這些數據可以是不同的格式,例如 CSV 、 JSON 或 Parquet 。然后,使用 DataFrame API 將數據加載到 Spark 中。 Spark SQL 用于執行數據清理和預處理任務:
- 刪除缺失的值。
- 處理異常值。
- 將數據轉換為合適的格式進行分析。
數據清理和預處理后,使用 Spark SQL 和 DataFrame API 進行各種類型的分析,以進行庫存優化。
例如,您可以使用 SQL 查詢分析銷售數據,以確定最暢銷和表現不佳的產品。要執行高級分析,如時間序列分析,請使用 DataFrame API 預測未來需求和優化算法,或分析數據集中的購買模式。
最后,應用分析結果來做出決策,例如庫存中要持有多少庫存,從供應商那里訂購多少,以及何時這樣做。使用 Spark 的 Dataframe API 或與其他系統集成來自動更新庫存水平。
此外,使用 Spark SQL 和 DataFrame API 處理來自不同來源的大量數據,如銷售、庫存和供應商數據,可以實現更高效、更準確的庫存管理系統。
您可以通過在 GPU 支持的 GoogleDataproc 集群上運行數據管道來加速這一過程并節省計算成本。本文的其余部分是關于創建 GPU 供電集群和使用 RAPIDS 加速器運行加速數據處理管道的過程的分步指南。
創建 RAPIDS 加速器 GPU 啟用的 Dataproc 集群
零售商的各種數據源將其原始數據推送到 Google Cloud Storage ,后者作為在啟用 GPU 的 Dataproc 集群上處理數據的源。在 Dataproc 集群中,您可以啟用 Jupyter 實驗室組件網關來運行筆記本電腦,該筆記本電腦在合并的數據上執行數據清理、合并和分析。
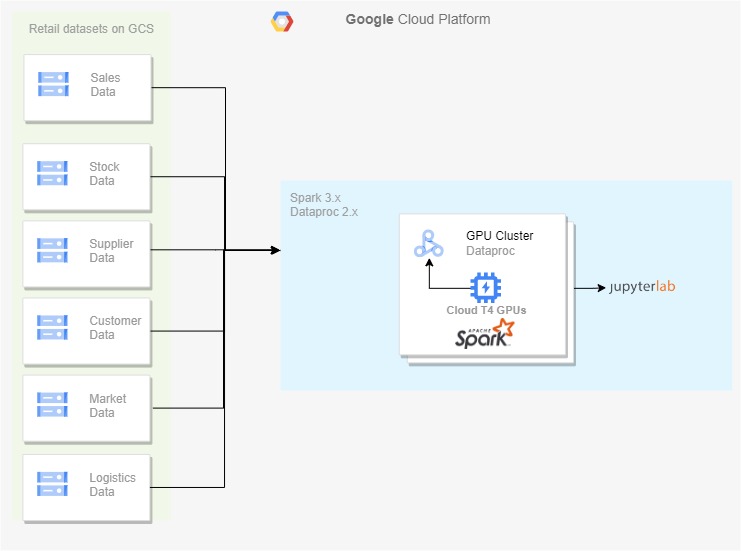
在圖 1 中,我將生成的零售源數據集保存在云存儲上,并使用 Dataproc 2.x 集群來處理數據。 RAPIDS 加速器的 GPU 啟用可以基于該過程進行。
要創建啟用 GPU 的 Dataproc 集群,請使用 Cloud shell 運行 shell 命令。要做到這一點,首先啟用 Compute 和 Dataproc API 以獲得對 Dataproc 的訪問權限。此外,當您需要一個谷歌云存儲桶來存儲數據時,請啟用存儲 API 。此過程可能需要幾分鐘才能完成。
gcloud services enable compute.googleapis.com gcloud services enable dataproc.googleapis.com gcloud services enable storage-api.googleapis.com
以下示例配置可幫助您在 GCP 上運行 GPU 啟用的工作負載。根據您的需要調整 GPU 的大小和數量。
要使用 RAPIDS 加速器啟動啟用 GPU 的群集,請在 CLI 中運行以下命令:
gcloud dataproc clusters create sparkrapidsnew \ --region us-central1 \ --subnet default \ --zone us-central1-c \ --master-machine-type n1-standard-8 \ --master-boot-disk-size 500 \ --num-workers 4 \ --worker-machine-type n1-standard-8 \ --worker-boot-disk-size 1000 \ --worker-accelerator type=nvidia-tesla-t4,count=2 \ --image-version 2.0-debian10 \ --properties spark:spark.eventLog.enabled=true,spark:spark.ui.enabled=true \ --optional-components HIVE_WEBHCAT,JUPYTER,ZEPPELIN,ZOOKEEPER \ --project PROJECT_NAME \ --initialization-actions=gs://goog-dataproc-initialization-actions-us-central1/spark-rapids/spark-rapids.sh --metadata gpu-driver-provider="NVIDIA" \ --enable-component-gateway
圖 2 顯示了創建一個 GPU 集群,每個集群在工作節點上有一個 T4 GPU 。初始化操作中的腳本在集群中安裝最新版本的 RAPIDS 加速器庫。

您還可以構建一個自定義的 dataproc 映像來加速集群初始化時間。有關更多信息,請參閱 Getting started with RAPIDS Accelerator on GCP Dataproc 快速入門頁。
在 Jupyter 實驗室運行 Py Spark
要將筆記本電腦與 Dataproc 群集一起使用,請選擇 Dataproc 集群下的群集,然后選擇 Web Interfaces, Jupyter Lab 。
數據清理
運行以下命令以完成這些任務:
- 讀取 JSON 和 CSV 等不同格式的所有數據。
- 執行數據清理任務,例如刪除缺失值和處理異常值。
- 執行數據轉換任務,例如將日期列轉換為日期類型和更改字符串的大小寫。
# remove missing values
sales_df = sales_df.dropDuplicates()
# remove duplicate data
sales_df = salesdf.dropna()
# convert date columns to date type
sales_df = sales_df.withColumn("date_of_sale", to_date(col("date_of_sale")))
# standardize case of string columns
sales_df = sales_df.withColumn("product_name", upper(col("product_name")))
# remove leading and trailing whitespaces
sales_df = sales_df.withColumn("product_name", trim(col("product_name")))
# check for invalid values
sales_df = sales_df.filter(col("product_name").isNotNull())
清理完數據后,將所有數據連接到一個公共列(product_name或customer_name)上,并將清理和轉換后的數據寫入 Parquet 文件格式。
這是 Py Spark 如何用于在大型數據集上執行數據清理和預處理任務的示例。但是,請記住,具體的清潔和預處理步驟因數據的性質和分析要求而異。
零售數據分析
您可以使用 Py Spark 執行各種零售數據分析。在演示筆記本中, Py Spark 正在讀取 Apache Parquet 格式的清理數據,根據某些條件創建新列,計算每個產品的滾動平均銷售額,并使用窗口函數進行預測。
然后,它執行各種聚合和 group-by 語句以獲得以下內容:
- 總銷售額
- 按產品和地點劃分的銷售量
- 供應商的庫存總量和總銷售額
- 每個地點易腐產品與非易腐產品的對比數量
- 每個地點的良好銷售狀態與不良銷售狀態的對比數量
- 包含 10% 折扣促銷的銷售額計數
聚合的結果然后以 Apache Parquet 格式保存到磁盤。代碼的執行時間也在測量和打印中。
具有優化設置的引導 GPU 集群
引導工具在 Dataproc 的 GPU 集群上的 Apache Spark 上應用 RAPIDS 加速器的優化設置。該工具獲取集群的特征,包括工作者數量、工作者核心、工作者內存以及 GPU 加速器類型和計數。然后,t使用集群財產來確定運行 GPU 加速 Spark 應用程序的最佳設置。
Usage: spark_rapids_dataproc bootstrap --cluster <cluster-name> --region <region>
該工具生成以下示例輸出:
##### BEGIN : RAPIDS bootstrap settings for sparkrapidsnew spark.executor.cores=4 spark.executor.memory=8192m spark.executor.memoryOverhead=4915m spark.rapids.sql.concurrentGpuTasks=2 spark.rapids.memory.pinnedPool.size=4096m spark.sql.files.maxPartitionBytes=512m spark.task.resource.gpu.amount=0.25 ##### END : RAPIDS bootstrap settings for sparkrapidsnew
調整 GPU 集群上的應用程序
Spark 應用程序在 GPU 集群上運行后,運行 profiling tool 分析應用程序的事件日志,以確定是否應配置更優化的設置。該工具輸出每個應用程序的一組配置設置,以進行調整以增強性能。
Usage: spark_rapids_dataproc profiling --cluster <cluster-name> --region <region>
該工具生成以下示例輸出:

通過優化設置,您可以運行數據清理和處理代碼,并將其與 CPU 對應代碼進行比較。您還可以分析 profiling tool output results ,并根據各自的見解進一步調整作業。
|
Pipeline step |
Data cleaning (CPU) |
Data analysis (CPU) |
Data cleaning (GPU) |
Data analysis (GPU) |
|
Dataproc cluster |
Five nodes n1-standard-8 |
Five nodes n1-standard-8 |
Five node n1-standard-4 +2 T4 / worker |
Five node n1-standard-2 +2 T4 / worker |
|
Time taken (secs) |
239 |
178 |
123 |
48 |
|
Cost ($) |
0.34 |
0.27 |
||
|
Yearly cost |
$2,978 |
$2,365 |
||
|
Yearly cost saving/workload |
? |
$613 |
||
|
Cost savings % |
? |
20% |
||
|
Speed-up |
? |
2.45x |
||
表 1 。零售渠道 GPU Dataproc 上的加速和成本節約計算
首先,該管道僅在帶有 CPU 的 Dataproc 集群上運行。然后,它在使用 T4 GPU s 啟用的 Dataproc 集群的不同配置上運行。
表 1 顯示,在 GPU 集群上運行管道的速度是等效的 CPU 集群的 2.45 倍,在遷移到 GPU 集群時可節省 20% 的成本。
接下來的步驟
將作業從 CPU 集群移動到 GPU 集群可能有不同的動機,例如提高性能、節省成本、滿足 SLA 要求,或解決長期運行作業的任何資源爭用問題。
此示例場景探討了如何通過相應地配置集群大小來節省數據處理成本。您可以嘗試 GPU 和虛擬機的不同組合來實現您的目標。
如果您希望加快數據處理、機器學習模型訓練和推理,請加入我們的 GTC 2023 ,參加我們即將舉行的 Accelerate Spark with RAPIDS For Cost Savings 會議,在會上我們討論了顯示利用 GPU 進行 Spark ETL 處理的性能和成本效益的基準。
?