?
在生產中部署 AI 模型以滿足 AI 驅動應用程序的性能和可擴展性要求,同時保持低基礎設施成本是一項艱巨的任務。
這篇文章為您提供了在生產中部署模型時常見的 AI 推理挑戰的高層次概述,以及目前如何跨行業使用 NVIDIA Triton 推理服務器 來解決這些問題。
我們還研究了 Triton 中最近添加的一些功能、工具和服務,它們簡化了生產中 AI 模型的部署,具有最佳性能和成本效益。
部署人工智能推理時需要考慮的挑戰
人工智能推理是運行人工智能模型進行預測的生產階段。推斷很復雜,但了解影響應用程序速度和性能的因素將有助于您在生產中交付快速、可擴展的 AI 。
開發人員和 ML 工程師面臨的挑戰
- 多種型號: 具有不同體系結構和不同規模的人工智能、機器學習和深度學習(基于神經網絡)模型。
- 不同的推理查詢類型: 實時、離線批處理、流式視頻和音頻以及模型管道使滿足應用程序服務級別協議變得非常困難。
- 不斷發展的模型: 生產中的模型必須根據新數據和算法不斷更新,而不會中斷業務。
MLOps 、 IT 和 DevOps 從業人員面臨的挑戰
- 多模型框架: 有不同的訓練和推理框架,比如 TensorFlow 、 PyTorch 、 XGBoost 、 TensorRT 、 ONNX ,或者只是普通的 Python 。在生產環境中為應用程序部署和維護這些框架的成本可能很高。
- 多元化處理器: 這些模型可以在 CPU 或 GPU 上執行。每個處理器平臺都有單獨的軟件堆棧,這會導致不必要的操作復雜性。
- 多元化部署平臺: 模型部署在公共云、本地數據中心、邊緣以及裸機、虛擬化或第三方 ML 平臺上的嵌入式設備上。不同的解決方案或不太適合給定平臺的最佳解決方案導致投資回報率低。這可能包括推出較慢、應用程序性能差或使用更多資源。
這些因素的結合使得在生產中部署 AI 推理具有一定的挑戰性,以獲得理想的性能和成本效率。
使用 NVIDIA Triton ?聲波風廓線儀的新 AI 推理用例
NVIDIA Triton 推理服務器?( Triton )是一種開源推理服務軟件,支持所有主要模型框架( TensorFlow 、 PyTorch 、 TensorRT 、 XGBoost 、 ONNX 、 OpenVINO 、 Python 等)。 Triton 可用于在 x86 和 Arm CPU 、 NVIDIA GPU 和 AWS Inferentia 上運行模型。它通過標準功能解決了前面討論的復雜性。
Triton 被全世界各行各業數以千計的組織使用。以下是 Triton 如何幫助一些客戶解決 AI 推理難題。
NIO 自動駕駛
NIO 使用 Triton 在云和數據中心運行其在線服務模型。這些模型處理來自自動駕駛車輛的數據。 NIO 使用 Triton 模型集成功能將其預處理和后處理功能從客戶端應用程序移動到 Triton 推斷服務器。預處理速度加快了 5 倍,提高了他們的整體推理吞吐量,使他們能夠經濟高效地處理來自車輛的更多數據。
GE Healthcare
GE Healthcare 在其愛迪生平臺中使用 Triton 來標準化內部模型跨不同框架( TensorFlow 、 PyTorch 、 ONNX 和 TensorRT )的推理服務。這些模型部署在各種硬件系統上,從嵌入式(例如, x 光系統)到本地服務器。
Wealthsimple
在線投資管理公司使用 CPU 上的 Triton 運行其欺詐檢測和其他金融科技模型。 Triton 幫助他們將跨應用程序的不同服務軟件整合到多個框架的單一標準中。
騰訊
騰訊在其集中式 ML 平臺中使用 Triton 對多個業務應用程序進行統一推理。總的來說, Triton 幫助他們每天處理 150 萬個查詢。騰訊通過 Triton 動態批處理和并發模型執行功能實現了低成本的推理。
阿里巴巴智能互聯
阿里巴巴智能連接公司正在為其智能揚聲器應用開發人工智能系統。他們在數據中心使用 Triton 運行模型,為智能揚聲器生成流式文本到語音轉換。 Triton 提供了良好音頻體驗所需的最低首包延遲。
雅虎日本
Yahoo Japan 在數據中心使用 CPU 上的 Triton 運行模型,為 Yahoo Browser 應用程序中的“點搜索”功能找到類似的位置。 Triton 用于運行完整的圖像搜索管道,還集成到其集中式 ML 平臺中,以支持 CPU 和 GPU 上的多個框架。
Airtel?
作為印度第二大無線供應商, Airtel 使用 Triton 為呼叫中心應用程序提供自動語音識別( ASR )模型,以改善客戶體驗。 Triton 幫助他們升級到更精確的 ASR 模型,與以前的服務解決方案相比, GPU 的吞吐量仍增加了 2 倍。
Triton 推理服務器如何應對 AI 推理挑戰
從金融科技到自動駕駛,所有應用程序都可以從開箱即用的功能中受益,從而輕松地將模型部署到生產中。
本節討論了 Triton 提供的一些開箱即用的關鍵新特性、工具和服務,可應用于生產中的模型部署、運行和擴展。
使用新管理服務建立業務流程模型
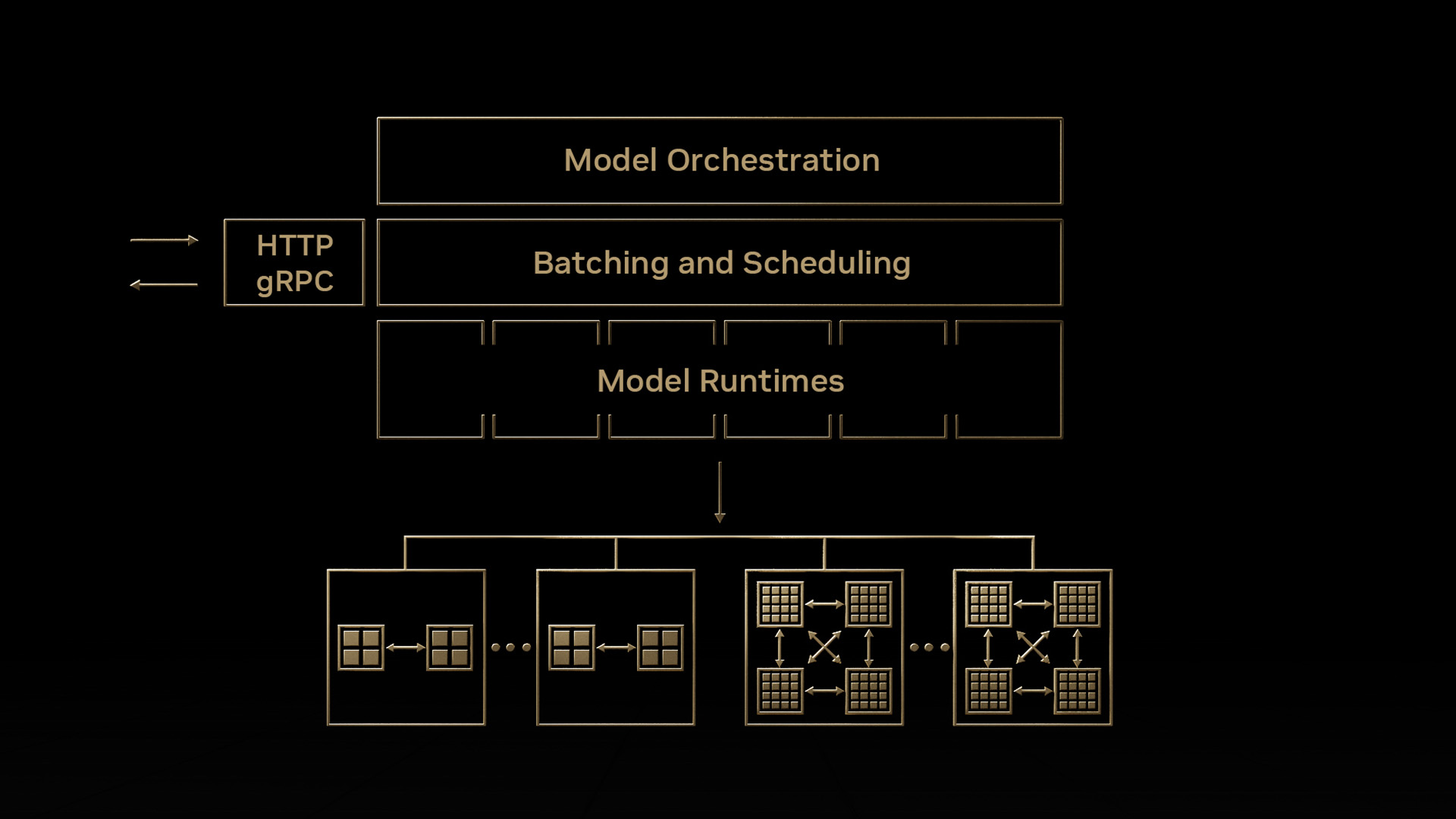
Triton 為高效的多模型推理帶來了一種新的模型編排服務。該軟件應用程序目前處于早期使用階段,有助于以資源高效的方式簡化 Kubernetes 中 Triton 實例的部署,其中包含許多模型。此服務的一些關鍵功能包括:
- 按需加載模型,不使用時卸載模型。
- 盡可能在單個 GPU 服務器上放置多個模型,從而有效地分配 GPU 資源
- 管理單個模型和模型組的自定義資源需求
有關此服務的簡短演示,請參閱 Take Your AI Inference to the Next Level 。模型編排功能位于 私人搶先體驗?( EA )中。如果您有興趣嘗試一下,請立即 注冊?。
大型語言模型推理
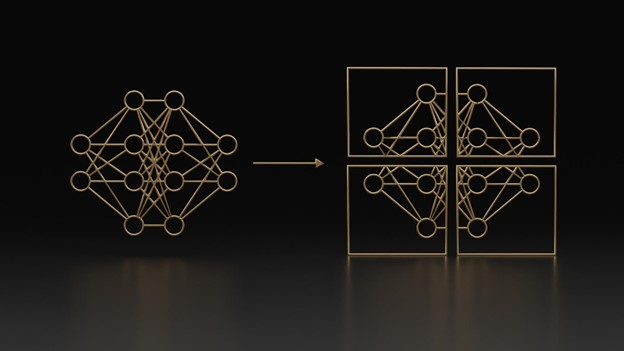
在自然語言處理( NLP )領域,模型的規模呈指數級增長(圖 1 )。具有數千億個參數的大型 transformer-based models 可以解決許多 NLP 任務,例如文本摘要、代碼生成、翻譯或 PR 標題和廣告生成。
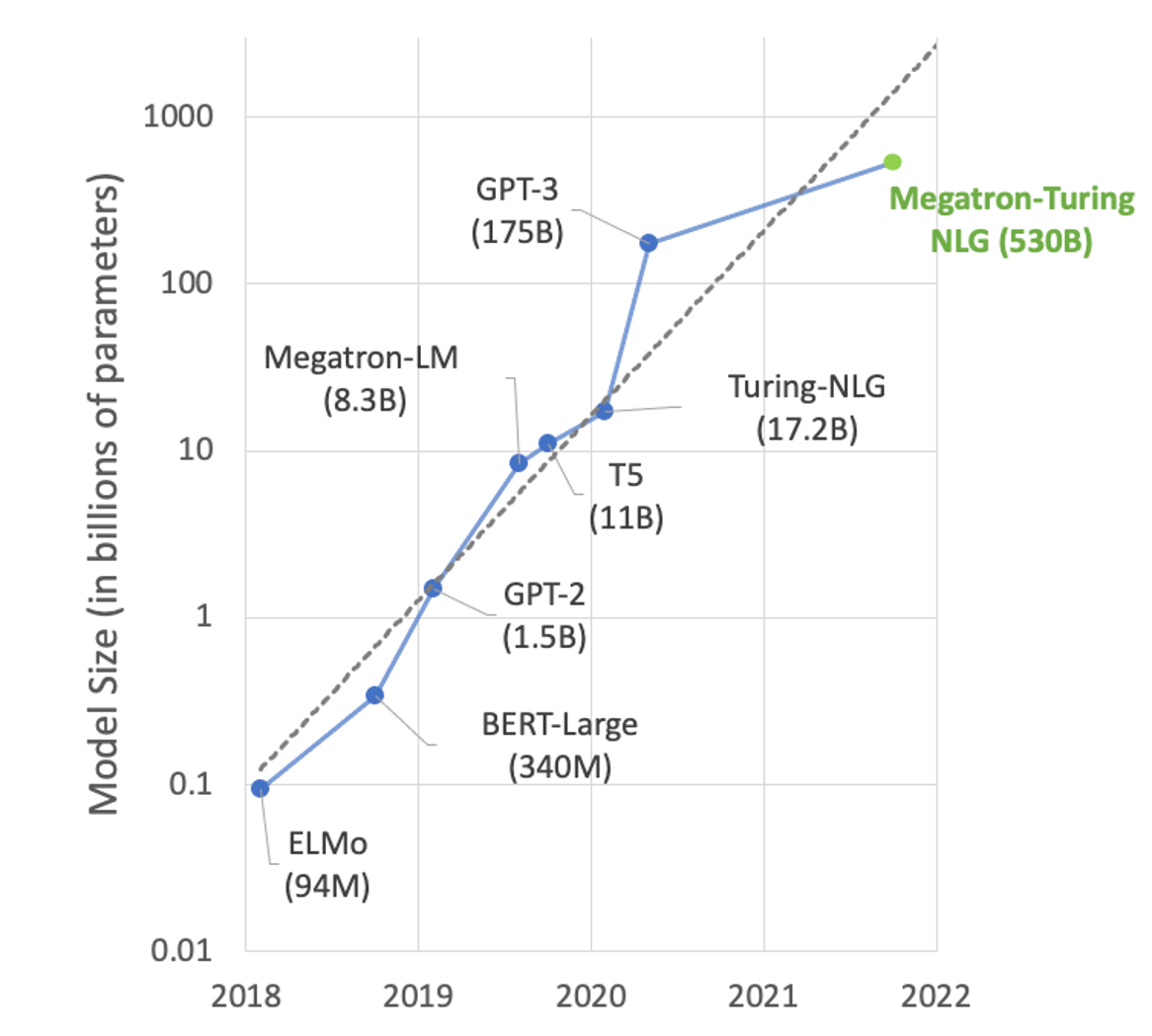
但這些型號太大了,無法安裝在單個 GPU 中。例如,具有 17.2B 參數的圖靈 NLG 需要至少 34 GB 內存來存儲 FP16 中的權重和偏差,而具有 175B 參數的 GPT-3 需要至少 350 GB 內存。要使用它們進行推理,您需要多 GPU 和越來越多的多節點執行來為模型服務。
Triton 推理服務器有一個稱為 Faster transformer 的后端,它為大型 transformer 模型(如 GPT 、 T5 等)帶來了多 GPU 多節點推理。大型語言模型通過優化和分布式推理功能轉換為更快的 transformer 格式,然后使用 Triton 推理服務器跨 GPU 和節點運行。
圖 2 顯示了使用 Triton 在 CPU 或一個和兩個 A100 GPU 上運行 GPT-J ( 6B )模型時觀察到的加速。
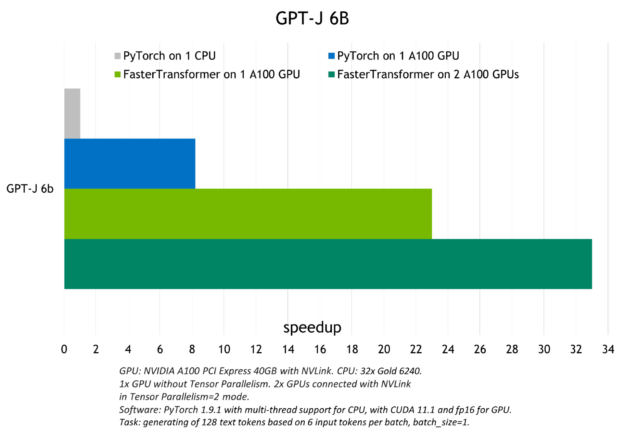
有關使用 Triton Faster transformer 后端進行大型語言模型推斷的更多信息,請參閱 Accelerated Inference for Large Transformer Models Using NVIDIA Triton Inference Server 和 Deploying GPT-J and T5 with NVIDIA Triton Inference Server 。
基于樹的模型推斷
Triton 可用于在 CPU 和 GPU 上部署和運行 XGBoost 、 LightGBM 和 scikit learn RandomForest 等框架中基于樹的模型,并使用 SHAP 值進行解釋。它使用去年推出的 Forest Inference Library ( FIL )后端實現了這一點。
使用 Triton 進行基于樹的模型推理的優點是在機器學習和深度學習模型之間的推理具有更好的性能和標準化。它特別適用于實時應用程序,如欺詐檢測,其中可以輕松使用較大的模型以獲得更好的準確性。
有關使用 Triton ?聲波風廓線儀部署基于樹的模型的更多信息,請參閱 Real-time Serving for XGBoost, Scikit-Learn RandomForest, LightGBM, and More 。該帖子包括一個欺詐檢測筆記本。
試試這個 NVIDIA Launchpad lab to deploy an XGBoost fraud detection model with Triton 。
使用模型分析器優化模型配置
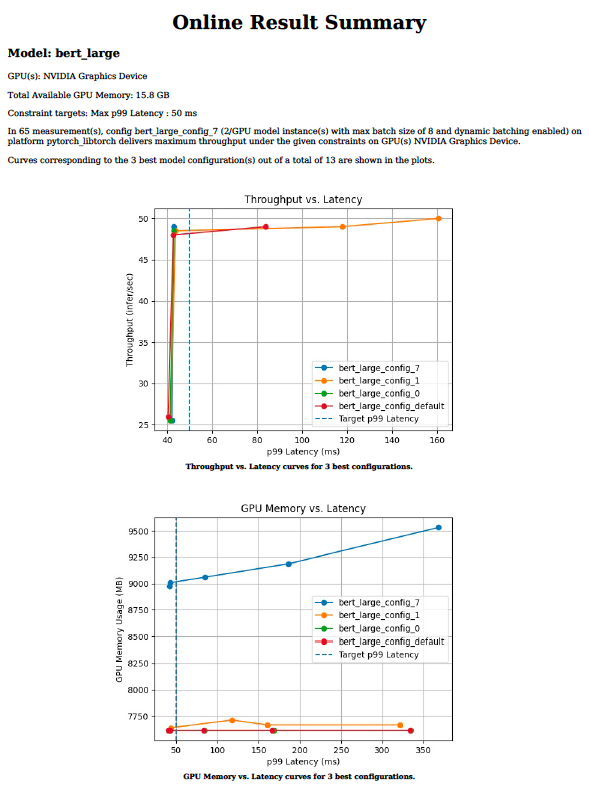
高效的推理服務需要為參數選擇最佳值,例如批大小、模型并發性或給定目標處理器的精度。這些值指示吞吐量、延遲和內存需求。在每個參數的值范圍內手動嘗試數百種組合可能需要數周時間。
Triton 模型分析器工具將找到最佳配置參數所需的時間從幾周減少到幾天甚至幾小時。它通過對給定的目標處理器脫機運行數百個具有不同批大小值和模型并發性的推理模擬來實現這一點。最后,它提供了如圖 3 所示的圖表,可以方便地選擇最佳部署配置。有關模型分析器工具以及如何將其用于推理部署的更多信息,請參見 Identifying the Best AI Model Serving Configurations at Scale with NVIDIA Triton Model Analyzer 。
使用業務邏輯腳本為管道建模
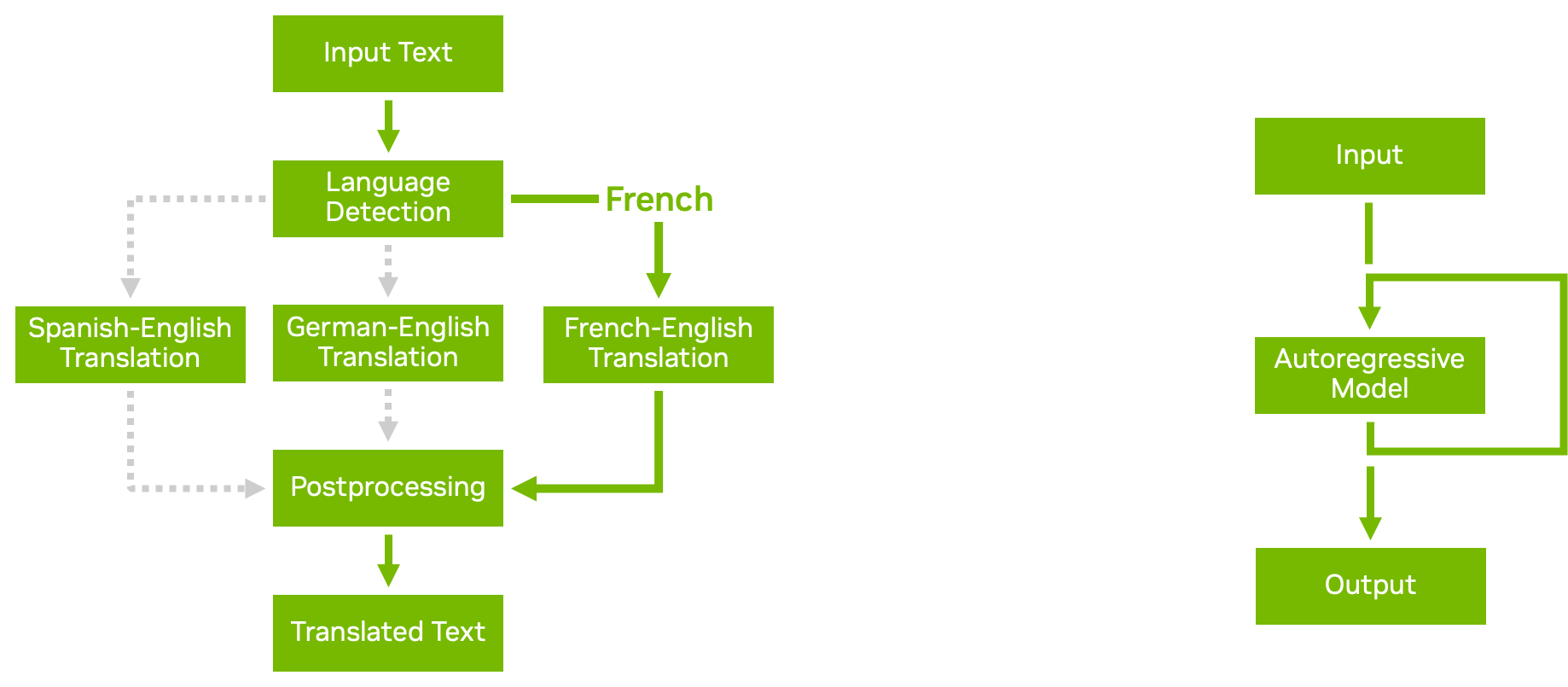
使用 Triton ?聲波風廓線儀的模型集成功能,您可以構建復雜的模型管道和集成,其中包含多個模型以及預處理和后處理步驟。業務邏輯腳本使您能夠在管道中添加條件、循環和步驟的重新排序。
使用 Python 或 C ++后端,您可以定義一個自定義腳本,該腳本可以根據您選擇的條件調用 Triton 提供的任何其他模型。 Triton 有效地將數據傳遞到新調用的模型,盡可能避免不必要的內存復制。然后將結果傳遞回自定義腳本,您可以從中繼續進一步處理或返回結果。
圖 4 顯示了兩個業務邏輯腳本示例:
- Conditional execution 通過避免執行不必要的模型,幫助您更有效地使用資源。
- Autoregressive models 與 transformer 解碼一樣,要求模型的輸出反復反饋到自身,直到達到某個條件。業務邏輯腳本中的循環使您能夠實現這一點。
有關詳細信息,請參閱 Business Logic Scripting 。
自動生成模型配置
Triton 可以自動為您的模型生成配置文件,以加快部署速度。對于 TensorRT 、 TensorFlow 和 ONNX 模型,當 Triton 在存儲庫中未檢測到配置文件時,會生成運行模型所需的最低配置設置。
Triton 還可以檢測您的模型是否支持批推理。它將max_batch_size設置為可配置的默認值。
您還可以在自己的自定義 Python 和 C ++后端中包含命令,以便根據腳本內容自動生成模型配置文件。當您有許多模型需要服務時,這些特性特別有用,因為它避免了手動創建配置文件的步驟。有關詳細信息,請參閱 Auto-generated Model Configuration 。
解耦輸入處理
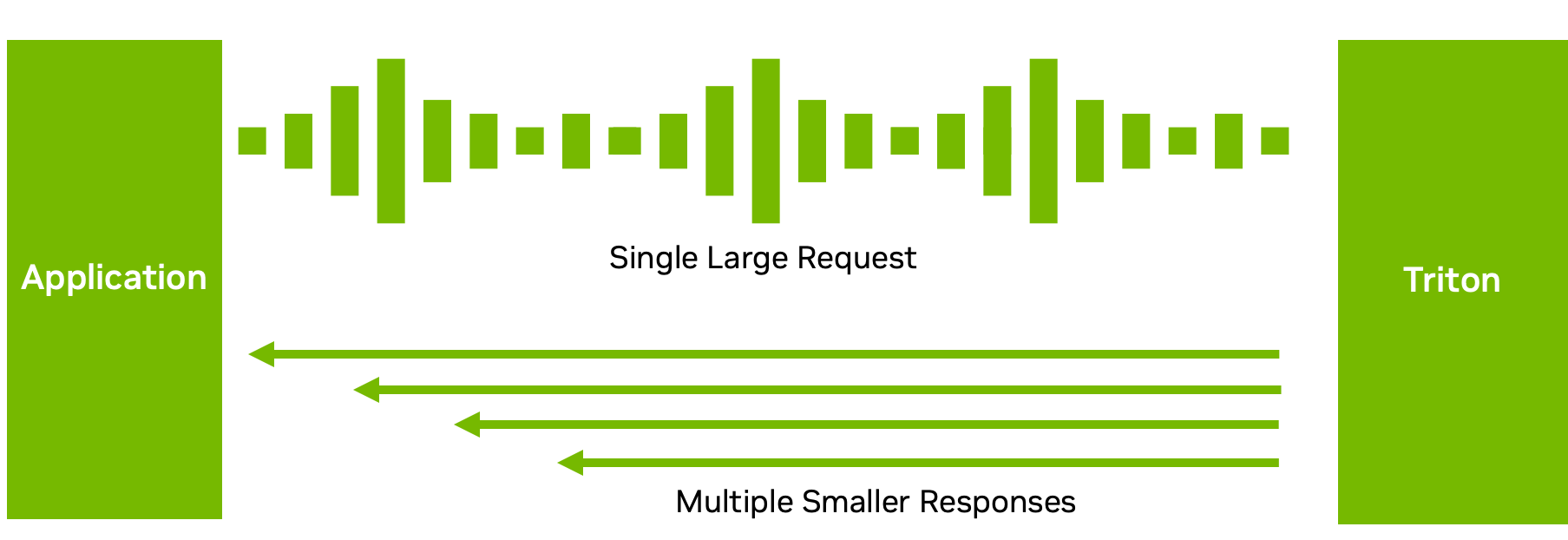
雖然許多推理設置需要推理請求和響應之間的一對一對應,但這并不總是最佳數據流。
例如,對于 ASR 模型,發送完整的音頻并等待模型完成執行可能不會帶來良好的用戶體驗。等待時間可能很長。相反, Triton 可以將轉錄的文本以多個短塊的形式發送回來(圖 5 ),從而減少了第一次響應的延遲和時間。
通過 C ++或 Python 后端的解耦模型處理,您可以為單個請求發送多個響應。當然,您也可以做相反的事情:分塊發送多個小請求,然后返回一個大響應。此功能在如何處理和發送推理響應方面提供了靈活性。有關詳細信息,請參閱 Decoupled Models 。
有關最近添加的功能的更多信息,請參閱 NVIDIA Triton release notes 。
開始可擴展 AI 模型部署
您可以使用 Triton 部署、運行和縮放 AI 模型,以有效緩解您在多個框架、多樣化基礎設施、大型語言模型、優化模型配置等方面可能面臨的 AI 推理挑戰。
Triton 推理服務器是開源的,支持所有主要模型框架,如 TensorFlow 、 PyTorch 、 TensorRT 、 XGBoost 、 ONNX 、 OpenVINO 、 Python ,甚至支持 GPU 和 CPU 系統上的自定義框架。探索將 Triton 與任何應用程序、部署工具和平臺、云端、本地和邊緣集成的更多方法。
有關詳細信息,請參閱以下資源:
- Get started with NVIDIA Triton 并訪問各種初學者的高級資源。
- 在構建實時或連續數據流應用程序 Fast and Scalable AI Model Deployment with NVIDIA Triton Inference Server 時,發現推理平臺中需要的功能。
- 了解為什么傳統計算基礎設施不再足以支持大規模人工智能 The secret to rapid and insightful AI–GPU-accelerated computing 。
- 尋找動手技能實驗室?在 NVIDIA LaunchPad 上部署 AI 支持聊天機器人或訓練自己的 AI 模型,用于在線產品的圖像分類。
?