超過 55% 的全球人口使用社交媒體,只需單擊一下即可輕松分享在線內容。在與他人聯系并消費娛樂內容的同時,你也可以發現構成現實生活威脅的有害敘事。
這就是為什么 Pendulum 的工程副總裁 Ammar Haris 希望他的公司的人工智能能夠幫助客戶更深入地了解在線生成的關于他們的有害內容。這些謊言經常像一場快速蔓延的野火一樣在社交媒體平臺上的視頻、音頻和文本中傳播。
就像野火一樣,及早發現有害的網絡敘事可能是撲滅任何破壞性影響的關鍵。
鐘擺是 NVIDIA Inception program ,通過提供接觸尖端技術和 NVIDIA 專家的機會,幫助創業公司發展。
演講 AI 和 NLP 促進社會福祉
早在 2021 , Sam Clark 和 Mark Listes 創建了 Pendulum ,目的是幫助客戶識別有害內容。業務合作伙伴知道,他們的平臺可以應用 speech AI 和自然語言處理( NLP )來幫助保護在線聲譽,甚至幫助員工實時安全。
在接下來的一年里,工程團隊開發了一系列人工智能系統,以檢測和表征困擾全球社會福祉的有害謊言。
今天,盡管需要處理大量數據,但 Pendulum 的平臺正在使以前無法發現的敘事最終變得可訪問。 Pendulum 的工程師熟悉尋找媒體寶庫的挑戰。
哈里斯解釋道:“ YouTube 、 BitChute 、 Rumble 和 TikTok 上的視頻,更不用說播客中的音頻了,很難搜索,甚至很難放到上下文中。這就是為什么經常只以其他人的方式搜索元數據,而不是實際的原始內容。”。
AI 引擎發現真實的謊言
處理數據環境發生了什么變化?通過使用加速語音 AI 和 NLP , Pendulum 的 Intelligence Explorer 和 Narrative Engine 現在可以在一大堆龐大的媒體語料庫中進行智能、深入的搜索,以找到最重要的信息(有害的敘事)。
事實上,你很可能已經熟悉許多網絡上的大規模謊言,以及它們如何在網絡上變異。例如,到目前為止, Pendulum 的引擎已將重點放在以下方面:
- 關于名人的虛假信息
- 對公司員工的身體威脅
- 供應鏈延誤的陰謀
- 新冠肺炎疫苗虛假信息
- 關于烏克蘭戰爭的謠言
- 最近試圖在 2022 年國際足聯世界杯上造成傷害
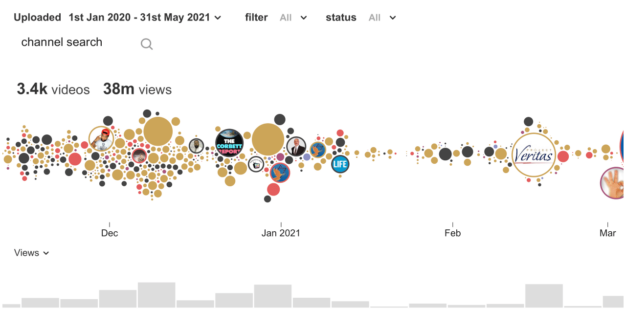
圖 1 顯示, Pendulum 確定了 3360 個視頻,占 3800 萬次瀏覽量,可能支持新冠病毒疫苗改變 DNA 的錯誤說法。其中,平臺上仍有 1600 個視頻可用,截至本文撰寫之日,瀏覽量為 1600 萬。虛假陳述是一段時間內的圓圈,其大小與觀看次數相對應。
敘事引擎如何在線檢測這些敘事并生成警報? Pendulum 開發了一種自動方法來發現和分類 YouTube 頻道,能夠每天轉錄數萬個視頻,主要通過分析 automatic speech recognition (ASR) 轉錄的文本。
該引擎對文本進行梳理,以對話、演講、播客和談話曲目的形式搜索數十億項支持數據,基本上獨立于媒體類型或社交媒體平臺。然后對感興趣的內容進行標記,以提醒客戶發現任何風險或趨勢。
解決方案背后的技術
ASR 處理的速度可能會成為問題,除非基于 GPU 的實現能夠處理吞吐量。 NVIDIA Riva Enterprise 對 Pendulum 有意義,結果證明是一個很好的解決方案。
哈里斯說:“這些記錄比我們評估的其他云服務更準確,同時實現了更高的吞吐量和更低的成本。”。
有了 Riva 的 Helm 圖表,工程團隊在設置過程中不必處理太多開銷。他們能夠很快推出加速版的引擎。 Riva 允許在本地或云中自行托管 ASR 服務,并通過 Helm 圖表配置進行優化。
Pendulum 目前在 Amazon Web Services ( AWS )上的 NVIDIA 驅動的 GPU 實例上運行 Riva 企業服務,以擴展可以快速轉錄和處理的音頻和視頻內容的數量。
ASR 步驟完成后, Pendulum 的敘事引擎將 Riva 中的更多 AI 資源應用于新轉錄的文本或其他地方收集的文本。例如, ASR 過程的原始輸出通常是一長串未大寫的單詞。這幾乎不是你認為可以巧妙地運用到可操作的情報報告中的那種數據。
考慮到輸出, Pendulum 接下來應用 Riva 的標點符號和大寫 AI 模型將雜亂的單詞流轉換為句子。輸出包含大寫的專有名詞、正確放置的逗號和終止句點或問號(視情況而定)。
參考圖 1 中的示例,在 Pendulum 的敘事發現方法中,專有的 NLP 子系統進一步處理文本。例如,該引擎將 1400 萬個視頻的文本字幕拆分為 2.05 億 snippets (長度約為 100 tokens 的文本片段)。結果被進一步過濾為包含一個或多個 COVID 錨定詞的視頻,包括“疫苗”和“ DNA ”等詞的形式。這個過程產生了一組 9200 個視頻和 15689 個片段。
最后, Pendulum 應用了一種專有的混合零鏡頭學習算法,檢測精度為 0.74 ,召回率為 0.83 。在這種情況下, 74% 的預測支持敘事 id 的片段確實支持敘事,而 83% 的支持敘事的片段是通過這種方法識別的。這是一個令人印象深刻的結果。
為了跟上業務增長的需求, Pendulum 團隊現在在 AWS 上部署了多節點 GPU 集群,以滿足吞吐量和延遲要求。在那之后,除了強大的硬件之外,還需要什么才能實現這些具有挑戰性的需求?
GPU 服務器上的 NVIDIA Triton Inference Server 軟件處理針對擺錘各種 AI 模型的多個請求。 Triton 推理服務器支持邏輯上鏈接在一起的模型,以在 GPU 中完全處理,從而避免 GPU 到 CPU 內存復制的緩慢陷阱。
未來的現實世界挑戰
Pendulum 平臺的功能將進一步擴展到社交媒體品牌,開發者將在目前可用的 YouTube 、 Rumble 、 BitChute 、 Tik Tok 和播客之外增加支持。
盡管如此,該公司的領導層不能僅僅通過其引擎的應用來判斷真相。事實上,避免這種復雜的情況已經讓擺錘打開了更大的光圈,迎接了新的挑戰。
舉個例子,我們都知道視頻不僅僅是口頭表達,還有更多的意義,尤其是伴隨著情感意象和令人回味的音樂配樂。即使在這樣的視頻中根本沒有演講,它仍然可以為敘事做出貢獻。
(想想幾年前 ISIS 的招募視頻:許多視頻幾乎沒有演講,但確實有激動人心的場景和音樂,旨在與特定觀眾建立聯系。)
畢竟,在沒有語音的地方, ASR 沒有什么可以轉錄的,而且敘事仍然沒有被發現。
Pendulum 的技術團隊正致力于處理視頻廣告等干擾因素,視頻廣告在播放過程中會彈出語音,可能會混淆正在形成的敘事。哈里斯解釋道,“有一個銀行視頻廣告是我團隊存在的禍根,擾亂了轉錄過程。還有工作要做。”
立即開始使用語音 AI
您也可以嘗試 NVIDIA Riva ,看看在構建應用程序時,它在轉錄準確性、速度和易用性方面的表現如何。以下是一些幫助您入門的資源:
- 了解有關 speech recognition 和如何啟動 using it today 的更多信息。
- 在這本免費電子書 Introduction to Speech AI 中詳細了解語音 AI 的發展前景。
- 學習如何通過免費電子書 End-to-End Speech AI Pipelines 將 TTS 技能添加到您的應用程序中來實現自然發音。
參加自主進度的深度學習培訓中心課程 Get Started with Highly Accurate Custom ASR for Speech AI ,學習如何定制語音識別管道。
?