這篇文章是關于生成準確語音轉錄的系列文章的一部分。有關第 1 部分,請參見 Speech Recognition: Generating Accurate Transcriptions Using NVIDIA Riva. 有關第 3 部分,請參見 Speech Recognition: Deploying Models to Production.
從頭開始創建一個新的人工智能深度學習模型是一個非常耗費時間和資源的過程。解決這個問題的一個常見方法是采用遷移學習。為了使這一過程更加簡單,NVIDIA TAO Toolkit,它可以將工程時間框架從 80 周縮短到 8 周。 TAO 工具包支持計算機視覺和對話 AI ( ASR 和 NLP )用例。
在本文中,我們將介紹以下主題:
- 安裝 TAO 工具包并訪問預訓練模型
- 微調預訓練語音轉錄模型
- 將微調模型導出到 NVIDIA Riva
跟隨 download the Jupyter notebook。
安裝 TAO 工具包并下載預訓練模型
在安裝 TAO 工具包之前,請確保您的系統上安裝了以下組件:
- Python [3 . 6 . 9]
- docker ce > 19 . 03 . 5
- nvidia-DOCKR2 3 . 4 . 0-1
有關安裝 nvidia docker 和 docker 的更多信息,請參閱Prerequisites。您可以使用 pip 安裝 TAO 工具包。我們建議使用virtual environment以避免版本沖突。
pip3 install nvidia-pyindex pip3 install nvidia-tao
安裝完成后,下一步是獲得一些經過預訓練的模型。 NVIDIA 提供了許多人工智能或機器學習模型,不僅在對話人工智能領域,而且在 NGC 或 NVIDIA GPU 云上的廣泛領域。 NGC 目錄是一套精心策劃的 GPU 優化軟件,用于 AI 、 HPC 和可視化。
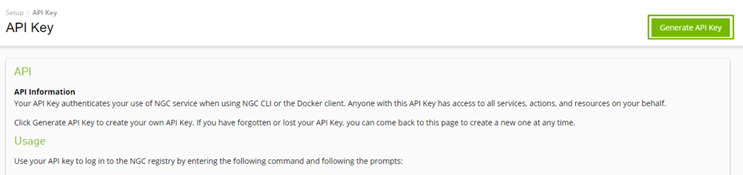
要從 NGC 下載資源,請使用NGC API key登錄注冊表。您可以免費創建和使用一個。
CitriNet是由 NVIDIA 構建的最先進的自動語音識別( ASR )模型,可用于生成語音轉錄。您可以從Speech to Text English Citrinet型號卡下載此型號。
wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/speechtotext_english_citrinet/versions/trainable_v1.7/files/speechtotext_english_citrinet_1024.tlt
為了提供流暢的體驗,工具包在后臺下載并運行 Docker 容器,使用前面提到的規范文件。所有細節都隱藏在 TAO 啟動器中。您可以通過定義 JSON 文件~/.tao_mounts.json來指定裝載 Docker 容器的首選位置。您可以在Jupyter notebook中找到裝載文件。
{
"Mounts":[
{
"source": "~/tao/data",
"destination": "/data" # The location in which to store the dataset
},
{
"source": "~/tao/specs",
"destination": "/specs" # The location in which to store the specification files
},
{
"source": "~/tao/results",
"destination": "/results" # The location in which to store the results
},
{
"source": "~/.cache",
"destination": "/root/.cache"
}
],
"DockerOptions":{
"shm_size": "16G",
"ulimits": {
"memlock": -1,
"stack": 67108864
}
}
}
這樣,您就安裝了 TAO 工具包,下載了一個經過預訓練的 ASR 模型,并指定了 TAO 工具包啟動器的安裝點。在下一節中,我們將討論如何使用 TAO 工具包在您選擇的數據集上微調此模型。
微調模型
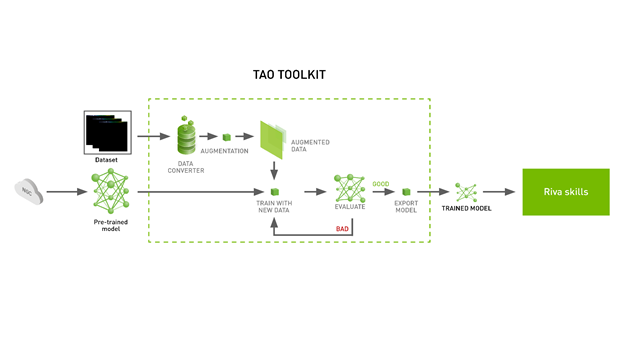
使用 TAO 工具包微調模型包括三個步驟:
- 下載規范文件。
- 預處理數據集。
- 使用超參數進行微調。
圖 3 顯示了微調模型所需的步驟。
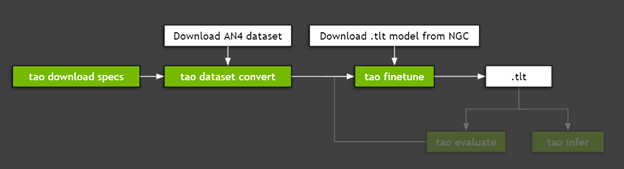
步驟 1 :下載規范文件
NVIDIA TAO Toolkit 是一種低代碼或無代碼的解決方案,通過規范文件簡化模型的培訓或微調。通過這些文件,您可以自定義特定于模型的參數、培訓師參數、優化器和所用數據集的參數。可以將這些規范文件下載到先前裝載的文件夾:
tao speech_to_text_citrinet download_specs \
-r <path to results dir>/speech_to_text_citrinet \
-o < path to specs dir>/speech_to_text_citrinet
以下是 TAO 工具包附帶的 YAML 文件。有關更多信息,請參閱Downloading Sample Spec Files。
create_tokenizer.yamldataset_convert_an4.yamldataset_convert_en.yamldataset_convert_ru.yamlevaluate.yamlexport.yamlfinetune.yamlinfer_onnx.yamlinfer.yamltrain_citrinet_256.yamltrain_citrinet_bpe.yaml
這些規范文件可供自定義和使用。從預處理和模型評估到推理和導出模型,都有相應的功能。這使您能夠完成開發或定制模型的過程,而無需構建復雜的代碼庫。下載等級庫文件后,現在可以繼續預處理數據。
步驟 2 :預處理數據集
在本演練中,您將使用CMU’s AN4 Dataset,這是一個小型普查數據集,其中包含地址、數字和其他個人信息的記錄。這與客戶支持對話中對話的初始步驟所需的轉錄類型類似。具有類似內容的較大自定義數據集可用于實際應用程序。
您可以直接下載和解壓縮 AN4 數據集,或使用以下命令:
wget http://www.speech.cs.cmu.edu/databases/an4/an4_sphere.tar.gz tar -xvf an4_sphere.tar.gz
TAO 工具包培訓和微調模塊期望數據以特定格式呈現。可以使用 dataset _ convert 命令完成此預處理。我們將 AN4 和 Mozilla 的通用語音數據集的規范文件與 TAO 啟動器一起打包。您可以在步驟 1 中定義的目錄中找到這些規范文件。
這些清單文件(圖 3 )包含在后面的步驟中使用的以下信息:
- 音頻文件的路徑
- 每個文件的持續時間
- 每個文件的文字內容
tao speech_to_text_citrinet dataset_convert \
-e <path to specs dir>/speech_to_text_citrinet/dataset_convert_an4.yaml \
-r <path to result dir>/citrinet/dataset_convert \
source_data_dir= </path/to/data/dir>/an4 \
target_data_dir=</path/to/data/dir>/an4_converted
此命令將音頻文件轉換為 WAV 文件,并生成訓練和測試清單文件。有關更多信息,請參閱Preparing the Dataset。
在大多數情況下,您都會進行預處理,但 CitriNet 模型是一個特例。它需要以子詞標記化的形式進行進一步處理,為文本創建子詞詞匯表。這與 Jasper 或 QuartzNet 不同,因為在它們的情況下,詞匯表中只有單個字符被視為元素。在 CitriNet 中,子字可以是一個或多個字符。這可以使用以下命令完成:
tao speech_to_text_citrinet create_tokenizer \ -e <path to specs dir>/speech_to_text_citrinet/create_tokenizer.yaml \ -r <path to result dir>/citrinet/create_tokenizer \ manifests=<path to data dir>/an4_converted/train_manifest.json \ output_root=<path to data dir>/an4 \ vocab_size=32
到目前為止,您已經建立了一個工具,為諸如遷移學習之類的復雜問題提供低代碼或無代碼解決方案。您已經下載了一個預訓練的模型,將音頻文件處理為必要的格式,并執行了標記化。您使用的命令不到 10 個。現在,所有必要的細節都已散列出來,您可以繼續微調模型。
步驟 3 :使用超參數進行微調
正如在前面的步驟中所做的那樣,您正在與規范文件交互。有關更多信息,請參閱Creating an Experiment Spec File。如果要調整 FFT 窗口大小的大小,可以指定幾乎所有內容,從特定于訓練的參數(如優化器)到特定于數據集的參數,再到模型配置本身。
是否要更改學習速率和調度程序,或者在詞匯表中添加新字符?無需打開代碼庫并對其進行掃描以進行更改。所有這些定制都很容易獲得,并可在整個團隊中共享。這減少了在嘗試新想法和分享結果以及模型配置方面的摩擦,從而提高了準確性。
以下是如何微調培訓師:
trainer: max_epochs: 3 # This is low for demo purposes tlt_checkpoint_interval: 1 change_vocabulary: true
以下是如何微調標記器:
tokenizer: dir: /path/to/subword/vocabulary type: "bpe" # Can be either bpe or wpe
以下是如何微調優化器:
optim:
name: novograd
lr: 0.01
betas: [0.8, 0.5]
weight_decay: 0.001
sched:
name: CosineAnnealing
warmup_steps: null
warmup_ratio: null
min_lr: 0.0
last_epoch: -1
以下是如何微調數據集:
# Fine-tuning settings: validation dataset validation_ds: manifest_filepath: /path/to/manifest/file/ sample_rate: 16000 labels: [" ", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z", "'"] batch_size: 32 shuffle: false finetuning_ds: manifest_filepath: ??? sample_rate: 160000 labels: [" ", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z", "'"] batch_size: 32 trim_silence: true max_duration: 16.7 shuffle: true is_tarred: false tarred_audio_filepaths: null
最后,要繼續,請根據需要修改規范文件并運行以下命令。此命令使用先前下載的數據集微調下載的模型。有關更多信息,請參閱Fine-Tuning the Model。
tao speech_to_text_citrinet finetune \
-e $SPECS_DIR/speech_to_text_citrinet/finetune.yaml \
-g 1 \
-k <key used to encode the model> \
-m </path to downloaded model>/speechtotext_english_citrinet_1024.tlt \
-r $RESULTS_DIR/citrinet/finetune \
finetuning_ds.manifest_filepath=$DATA_DIR/an4_converted/train_manifest.json \
validation_ds.manifest_filepath=$DATA_DIR/an4_converted/test_manifest.json \
trainer.max_epochs=1 \
finetuning_ds.num_workers=1 \
validation_ds.num_workers=1 \
trainer.gpus=1 \
tokenizer.dir=$DATA_DIR/an4/tokenizer_spe_unigram_v32
在對模型進行微調或培訓后,自然會評估模型并評估是否需要進一步微調。為此, NVIDIA 為evaluate your model和run inference提供了功能。
將微調模型導出到 Riva
在生產環境中部署模型會帶來一系列挑戰。為此,您可以使用NVIDIA Riva,一種 GPU 加速 AI 語音 SDK 來開發實時轉錄和虛擬助理等應用程序。
Riva 使用其他 NVIDIA 產品:
- NVIDIA Triton Inference Server用于簡化大規模生產中模型的部署。
- NVIDIA TensorRT用于通過優化 NVIDIA GPU s 的模型來加速模型并提供更好的推理性能。
如果您對使用本演練中微調的模型感興趣,可以使用以下命令將其導出到 Riva 。有關更多信息,請參閱Model Export。
tao speech_to_text_citrinet export \
-e <path to spec dir>/speech_to_text_citrinet/export.yaml \
-g 1 \
-k <key used to encode the model> \
-m <path to results dir>/citrinet/train/checkpoints/trained-model.tlt \
-r <path to results dir>/citrinet/riva \
export_format=RIVA \
export_to=asr-model.riva
下一步是什么?
Citrinet for Speech Transcription 不是 NVIDIA 提供的唯一模型或用例。在會話人工智能和計算機視覺中有多種用例和預先訓練的模型。有關更多信息,請參閱NVIDIA TAO Toolkit產品頁面。
在下一篇文章中,我們將介紹如何安裝 NVIDIA Riva 在生產環境中部署這些模型,以及如何使用NGC Catalog中的眾多模型之一。有關更多信息,請參閱Speech Recognition: Deploying Models to Production。