這篇文章是關于生成準確語音轉錄的系列文章的一部分。有關第 1 部分,請參見Speech Recognition: Generating Accurate Transcriptions Using NVIDIA Riva.有關第 2 部分,請參見Speech Recognition: Customizing Models to Your Domain Using Transfer Learning
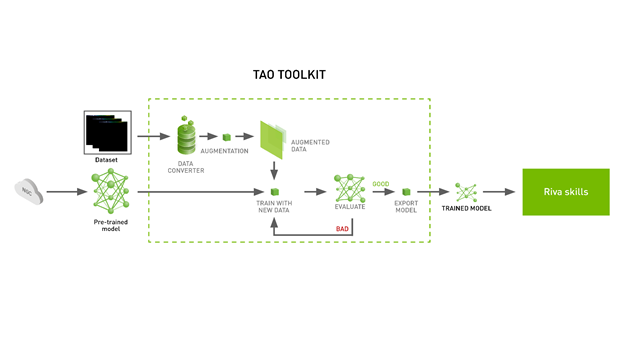
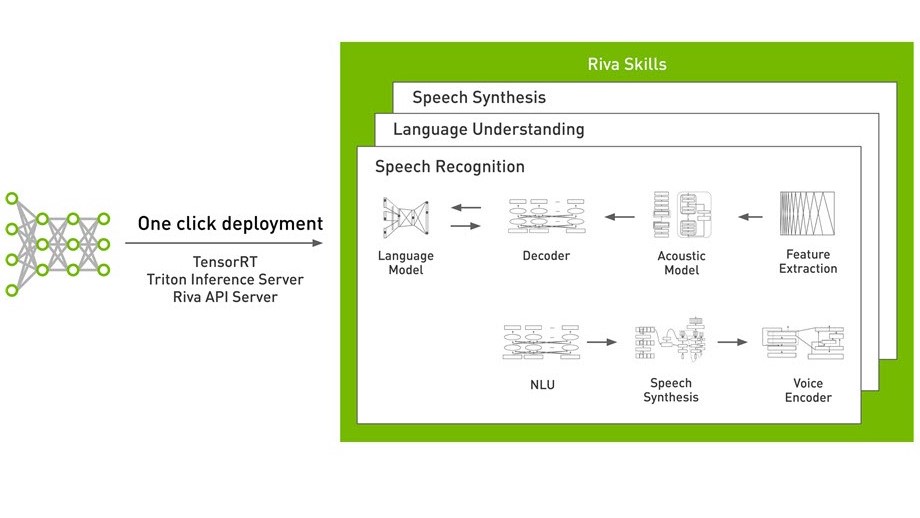
NVIDIA Riva 是一款 AI 語音 SDK ,用于開發實時應用程序,如轉錄、虛擬助理和聊天機器人。它包括 NGC 中經過預訓練的最先進模型、用于在您的領域中微調模型的 TAO 工具包以及用于高性能推理的優化技能。 Riva 使使用 NGC 中的 Riva 容器或使用 Helm chart 在 Kubernetes 上部署模型變得更簡單。 Riva 技能由 NVIDIA TensorRT 提供支持,并通過 NVIDIA Triton 提供服務推理服務器。
在本文中,我們將討論以下主題:
- 背景 向上 Riva
- 配置 Riva 并部署您的模型
- 用你的模型推斷
- 關鍵外賣
這篇文章的內容可以在 Jupyter notebook 中找到,你可以下載它來跟進。有關 Riva 的更多信息,請參閱 Introducing NVIDIA Riva: An SDK for GPU-Accelerated Conversational AI Applications。
配置 Riva
在設置 NVIDIA Riva 之前,請確保您的系統上已安裝以下設備:
- Python [3 . 6 . 9]
- docker ce > 19 . 03 . 5
- nvidia-DOCKR2 3 . 4 . 0-1 :Installation Guide
如果您按照第 2 部分中的說明進行操作,那么您應該已經安裝了所有的先決條件。
設置 Riva 的第一步是到 install the NGC Command Line Interface Tool。
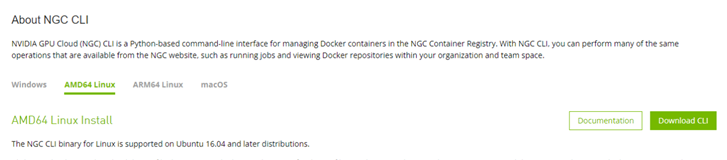
要登錄到注冊表,您必須 get access to the NGC API Key。
設置好工具后,您現在可以從 NGC 上的Riva Skills Quick Start資源下載 Riva 。要下載該軟件包,可以使用以下命令(最新版本的命令可在前面提到的 Riva 技能快速入門資源中找到):
ngc registry resource download-version "nvidia/riva/riva_quickstart:1.6.0-beta"
下載的軟件包具有以下資產,可幫助您入門:
- asr _ lm _工具:這些工具可用于微調語言模型。
- nb _ demo _ speech _ api . ipynb :Riva 的入門筆記本。
- Riva _ api-1 . 6 . 0b0-py3-none-any . whl和NeMo 2 Riva -1 . 6 . 0b0-py3-none-any . whl :安裝 Riva 的滾輪文件和將 NeMo 模型轉換為 Riva 模型的工具。有關更多信息,請參閱本文后面的Inferencing with your model部分。
- 快速啟動腳本( Riva .*. sh , config . sh ):初始化并運行 Triton 推理服務器以提供 Riva AI 服務的腳本。有關更多信息,請參閱配置 Riva 和部署您的模型。
- 示例:基于 gRPC 的客戶機代碼示例。
配置 Riva 并部署您的模型
你可能想知道從哪里開始。為了簡化體驗, NVIDIA 通過提供一個配置文件,使用 Riva AI 服務調整您可能需要調整的所有內容,從而幫助您使用 Riva 定制部署。對于本演練,您依賴于特定于任務的 Riva ASR AI 服務。
對于本演練,我們只討論一些調整。因為您只使用 ASR ,所以可以安全地禁用 NLP 和 TTS 。
# Enable or Disable Riva Services service_enabled_asr=true service_enabled_nlp=false service_enabled_tts=false
如果您遵循第 2 部分的內容,可以將 use _ existing _ rmirs 參數設置為 true 。我們將在后面的文章中對此進行詳細討論。
# Locations to use for storing models artifacts riva_model_loc="riva-model-repo" use_existing_rmirs=false
您可以選擇從模型存儲庫下載的預訓練模型,以便在不進行自定義的情況下運行。
########## ASR MODELS ##########
models_asr=(
### Punctuation model
"${riva_ngc_org}/${riva_ngc_team}/rmir_nlp_punctuation_bert_base:${riva_ngc_model_version}"
...
### Citrinet-1024 Offline w/ CPU decoder,
"${riva_ngc_org}/${riva_ngc_team}/rmir_asr_citrinet_1024_asrset3p0_offline:${riva_ngc_model_version}"
)
如果您在閱讀本系列第 2 部分時有 Riva 模型,請首先將其構建為稱為 Riva 模型中間表示( RMIR )格式的中間格式。您可以使用 Riva Service Maker 來完成此操作。 ServiceMaker 是一組工具,用于聚合 Riva 部署到目標環境所需的所有工件(模型、文件、配置和用戶設置)。
使用riva-build和riva-deploy命令執行此操作。有關更多信息,請參閱Deploying Your Custom Model into Riva。
docker run --rm --gpus 0 -v <path to model>:/data <name and version of the container> -- \
riva-build speech_recognition /data/asr.rmir:<key used to encode the model> /data/<name of the model file>:<key used to encode the model> --offline \
--chunk_size=1.6 \
--padding_size=1.6 \
--ms_per_timestep=80 \
--greedy_decoder.asr_model_delay=-1 \
--featurizer.use_utterance_norm_params=False \
--featurizer.precalc_norm_time_steps=0 \
--featurizer.precalc_norm_params=False \
--decoder_type=greedy
docker run --rm --gpus 0 -v <path to model>:/data <name and version of the container> -- \
riva-deploy -f /data/asr.rmir:<key used to encode the model> /data/models/
現在已經設置了模型存儲庫,下一步是部署模型。雖然您可以這樣做manually,但我們建議您在第一次體驗時使用預打包的腳本。快速啟動腳本riva_init.sh和riva_start.sh是可用于使用config.sh中的精確配置部署模型的兩個腳本。
bash riva_init.sh bash riva_start.sh
運行riva_init.sh時:
- 您在
config.sh中選擇的模型的 RMIR 文件從指定目錄下的 NGC 下載。 - 對于每個 RMIR 模型文件,將生成相應的 Triton 推理服務器模型存儲庫。此過程可能需要一些時間,具體取決于所選服務的數量和型號。
要使用自定義模型,請將 RMIR 文件復制到config.sh(用于$riva_model_loc)中指定的目錄。要部署模型,請運行riva_start.sh。riva-speech容器將與從所選存儲庫加載到容器的模型一起旋轉。現在,您可以開始發送推斷請求了。
使用您的模型進行推斷
為了充分利用 NVIDIA GPU s , Riva 利用了 NVIDIA Triton 推理服務器和 NVIDIA TensorRT 。在會話設置中,應用程序會優化盡可能低的延遲,但為了使用更多的計算資源,必須增加批大小,即同步處理的請求數,這自然會增加延遲。 NVIDIA Triton 可用于在多個 GPU 上的多個模型上運行多個推理請求,從而緩解此問題。
您可以使用 GRPCAPI 在三個主要步驟中查詢這些模型:導入 LIB 、設置 gRPC 通道和獲取響應。
首先,導入所有依賴項并加載音頻。在這種情況下,您正在從文件中讀取音頻。我們在 examples 文件夾中還有一個流媒體示例。
import argparse
import grpc
import time
import riva_api.audio_pb2 as ra
import riva)api.riva_asr_pb2 as rasr
import riva)api.riva_asr_pb2_grpc as rasr_srv
import wave
audio_file = "<add path to .wav file>"
server = "localhost:50051
wf = wave.open(audio_file, 'rb')
with open(audio_file, 'rb') as fh:
data = fh.read()
要安裝所有 Riva 特定依賴項,可以使用包中提供的. whl 文件。
pip3 install riva_api-1.6.0b0-py3-none-any.whl
接下來,創建一個指向 Riva 端點的 grpc 通道,并將其配置為使用適合您的用例的音頻。
channel = grpc.insecure_channel(server) client = rasr_srv.RivaSpeechRecognitionStub(channel) config = rasr.RecognitionConfig( encoding=ra.AudioEncoding.LINEAR_PCM, sample_rate_hertz=wf.getframerate(), language_code="en-US", max_alternatives=1, enable_automatic_punctuation=False, audio_channel_count=1 )
最后,向服務器發送推斷請求并獲得響應。
request = rasr.RecognizeRequest(config=config, audio=data) response = client.Recognize(request) print(response)
關鍵信息
此 API 可用于構建應用程序。您可以在單個裸機系統上安裝 Riva ,并開始本練習,或者使用 Kubernetes 和提供的Helm chart進行大規模部署。
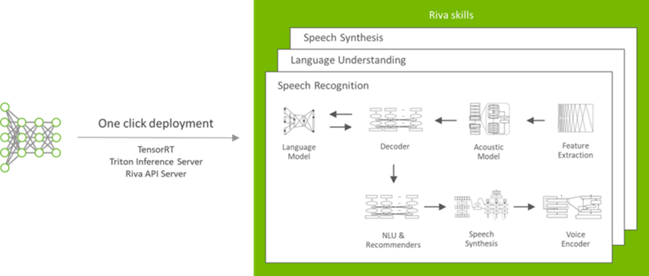
使用此舵圖,您可以執行以下操作:
- 從 NGC 中提取 Riva 服務 API 服務器、 Triton 推理服務器和其他必要的 Docker 映像。
- 生成 Triton 推理服務器模型庫,并啟動英偉達 Triton 服務器,并使用所選配置。
- 公開要用作 Kubernetes 服務的推理服務器和 Riva 服務器終結點。
有關更多信息,請參閱 Deploying Riva ASR Service on Amazon EKS。
結論
Riva 是一款用于開發語音應用程序的端到端 GPU 加速 SDK 。在本系列文章中,我們討論了語音識別在行業中的重要性,介紹了如何在您的領域定制語音識別模型以提供世界級的準確性,并向您展示了如何使用 Riva 部署可實時運行的優化服務。
有關其他有趣的 Riva 解決方案的更多信息,請參閱 all Riva posts on the Developer Blog。