這篇文章是關于生成準確語音轉錄的系列文章的一部分。有關第 2 部分,請參見Speech Recognition: Customizing Models to Your Domain Using Transfer Learning. 有關第 3 部分,請參見Speech Recognition: Deploying Models to Production.
每天,電信、金融和統一通信即服務( UCaaS )等行業都會產生數百萬分鐘的音頻。這些音頻會議記錄可以轉錄,以便為呼叫中心代理提供實時建議,從客戶呼叫記錄中提取見解,或在視頻會議中生成實時字幕。

自動語音識別使您能夠將語音轉錄成文本。生成高質量的文字記錄是一項挑戰,因為這些技能需要理解特定于行業的術語、數百到數千分鐘特定于領域的培訓音頻以及實時運行的管道。 NVIDIA Riva 語音識別是一項技術,可為跨行業的幾個常見用例提供世界級的實時準確度。
在這篇文章中,我們討論 Riva 語音識別。后續文章將討論如何定制語音識別模型,并將其作為優化技能進行部署:
- Customizing Speech Recognition Models to Your Domain Using TAO Toolkit
- Deploying Speech Recognition Models to Production Using Riva
Riva 語音識別
Riva 是 GPU 加速的 AI 語音 SDK ,用于實時轉錄和虛擬助理等對話 AI 應用程序。 Riva 具有以下優點:
- NGC 中經過預訓練的最先進的語音模型
- 沒有編碼工具,例如TAO Toolkit,用于在自定義數據集上微調這些模型
- 用于高性能推理的優化語音識別和語音合成管道
Riva 下面的模型是基于數百到數千小時的開放和真實世界數據進行訓練的,這些數據來自電信、金融、醫療保健和 NVIDIA 超級計算機上的教育等行業。數據集樣本還來自嘈雜的環境、自發的語音對話、多種英語口音和不同的采樣率。所有這些屬性都有助于生成噪聲魯棒、高質量的轉錄。
Riva 語音識別技能在各種真實世界的用例數據集上進行評估,包括視頻會議、聯絡中心、播客和技術視頻。您可以在云中、數據中心和邊緣部署這些技能。
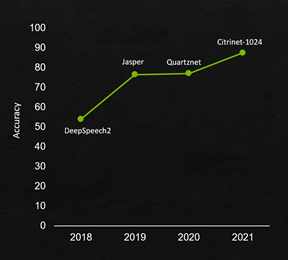
Riva 語音識別管道在保持準確性的同時,為新的最先進的體系結構提供支持。圖 2 顯示了在過去 3 年中,通過新的模型體系結構、訓練方法以及最新的基于 TensorRT 和 GPU 的優化,語音準確性的提高。
使用 Riva ,您可以在流式或批處理模式下以實時延遲快速部署和擴展到數百和數千個并發流。
有關使用 Riva 自定義并部署到語音應用程序的更多信息,請參閱本系列的下一篇文章Speech Recognition: Customizing Models to Your Domain Using Transfer Learning。在第 3 部分中,我們將介紹如何部署經過微調的模型。有關更多信息,請參閱Speech Recognition: Deploying Models to Production。
?