每年,作為課程的一部分,波蘭華沙大學的學生都會在 NVIDIA 華沙辦事處工程師的監督下,就深度學習和加速計算中的挑戰性問題開展工作。我們展示了三位理學碩士學生——Alicja Ziarko、Pawe? Pawlik 和 Micha? 的TorToiSe,一個多階段、基于擴散的文本到語音(TTS)模型。
Alicja、Pawe? 和 Micha? 首先了解了語音合成和擴散模型的最新進展。他們選擇了 combination,這是 無分類器引導 和 漸進式蒸餾 的一部分,在計算機視覺中表現良好,并將其應用于語音合成。在不降低語音質量的情況下,他們將擴散延遲降低了 5 倍。小型感知語音測試證實了這一結果。值得注意的是,這種方法不需要從原始模型開始進行昂貴的訓練。
為什么要加快基于擴散的 TTS?
自從WaveNet 在 2016 年出現以來,神經網絡已經成為語音合成的主要模型。在一些簡單的應用中,例如基于人工智能的語音助手的語音合成,合成的語音幾乎無法與人類的語音區分。這種語音合成的速度可以比實時快幾個數量級,例如使用NVIDIA NeMo AI 工具包。
然而,基于幾秒鐘的錄音(幾次拍攝)來實現高表現力或模仿聲音仍然被認為是具有挑戰性的。
去噪擴散概率模型 (DDPMs)作為一種生成技術出現,它能夠基于輸入文本生成高質量和高表現力的圖像。DDPM 可以很容易地應用于 TTS,因為基于頻率的聲譜圖可以像圖像一樣進行處理,從而圖形化地表示語音信號。
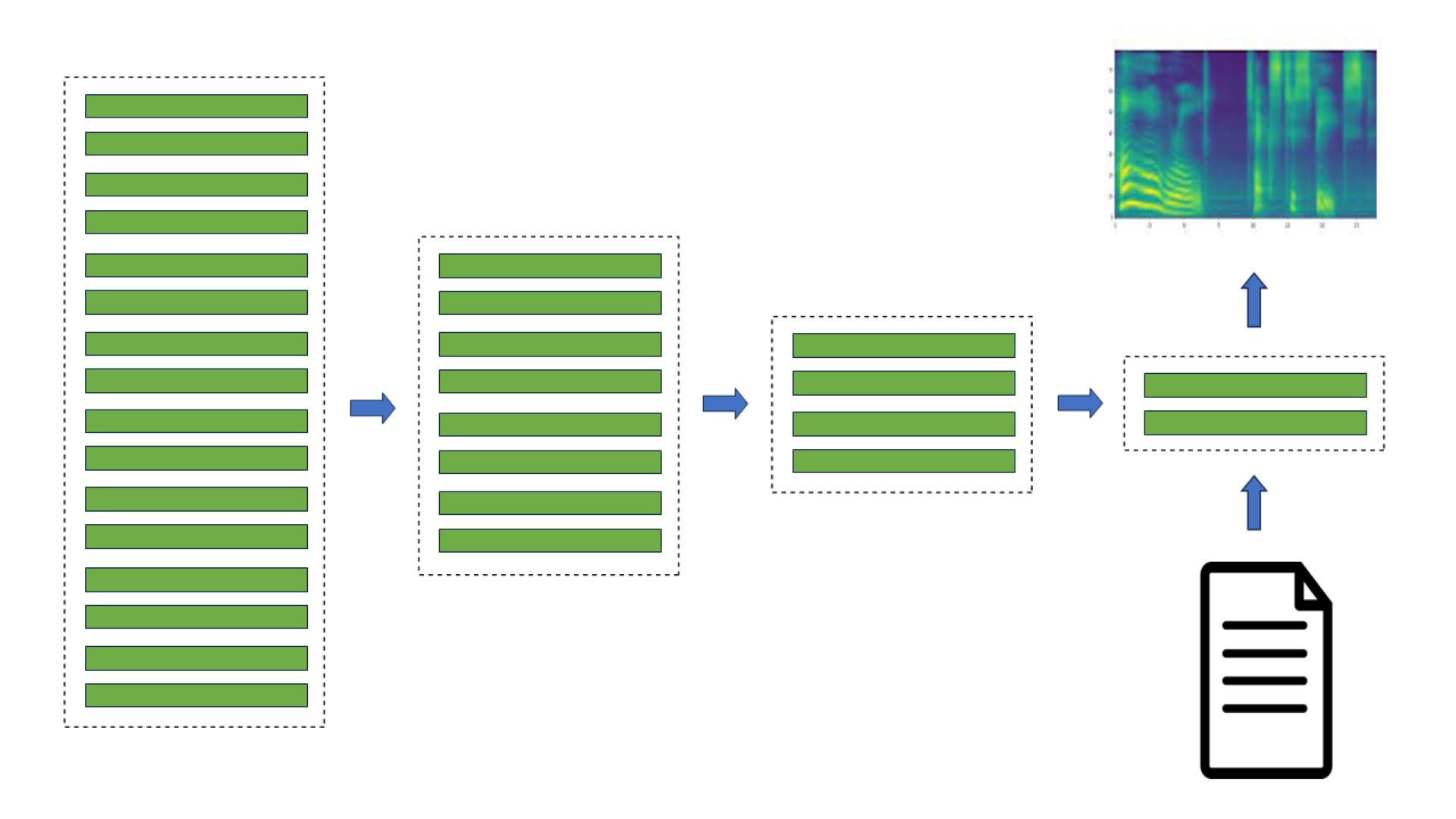
例如,在 TorToiSe 中,這是一個基于引導擴散的 TTS 模型,通過組合兩個擴散模型的結果來生成譜圖(圖 1)。迭代擴散過程涉及數百個步驟來實現高質量的輸出,與最先進的 TTS 方法相比,延遲顯著增加,這嚴重限制了其應用。
在圖 1 中,無條件擴散模型迭代地細化初始噪聲,直到獲得高質量的譜圖。第二擴散模型進一步以語言模型產生的文本嵌入為條件。
加速擴散的方法
現有的基于擴散的 TTS 中的延遲減少技術可以分為無訓練和基于訓練的方法。
無訓練方法不涉及通過反轉擴散過程來訓練用于生成圖像的網絡。相反,他們只專注于優化多步驟擴散過程。擴散過程可以看作是解決ODE/SDE方程,因此優化它的一種方法是創建一個更好的解算器DDPM,DDIM和DPM,這降低了擴散步驟的數量。并行采樣方法,例如基于Picard iterations或Normalizing Flows,可以將擴散過程并行化,以受益于 GPU 上的并行計算。
基于訓練的方法主要優化擴散過程中使用的網絡。網絡可以被剪枝,量化 或 稀疏化,然后進行微調以提高精度。或者,可以手動或自動更改其神經結構,使用NAS 知識提取技術從教師網絡中提取學生網絡,以減少擴散過程中的步驟數量。
基于擴散的 TTS 中的蒸餾
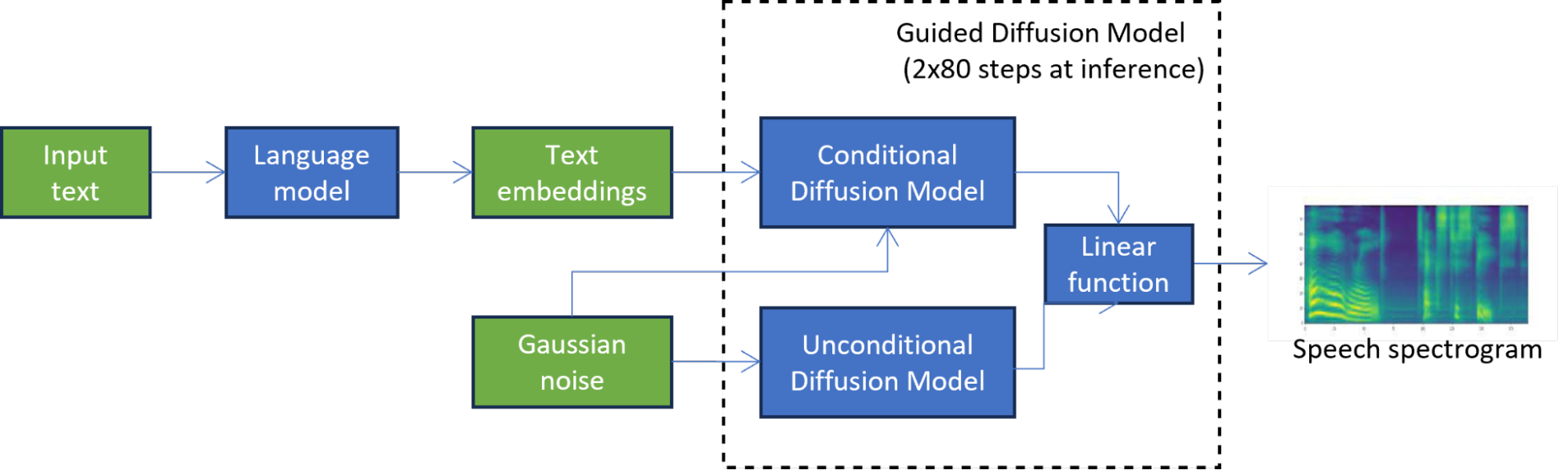
Alicja、Pawe? 和 Micha? 決定使用基于有前景的結果在計算機視覺中的方法,并且它在推斷時能夠將擴散模型的延遲減少 5 倍。他們成功地將漸進蒸餾應用于預訓練的 TorToiSe 模型的擴散部分,克服了無法訪問原始訓練數據等問題。
他們的方法包括兩個知識提煉階段:
- 模擬引導擴散模型輸出
- 培訓另一個學生模型
在第一個知識提取階段(圖 2),對學生模型進行訓練,以在每個擴散步驟模擬引導擴散模型的輸出。該階段通過將兩個擴散模型組合為一個模型,將延遲減少一半。
為了解決無法訪問原始訓練數據的問題,將語言模型中的文本嵌入傳遞到原始教師模型中,以生成用于提取的合成數據。合成數據的使用也使蒸餾過程更加高效,因為在每個蒸餾步驟都不必調用整個 TTS 引導擴散管道。
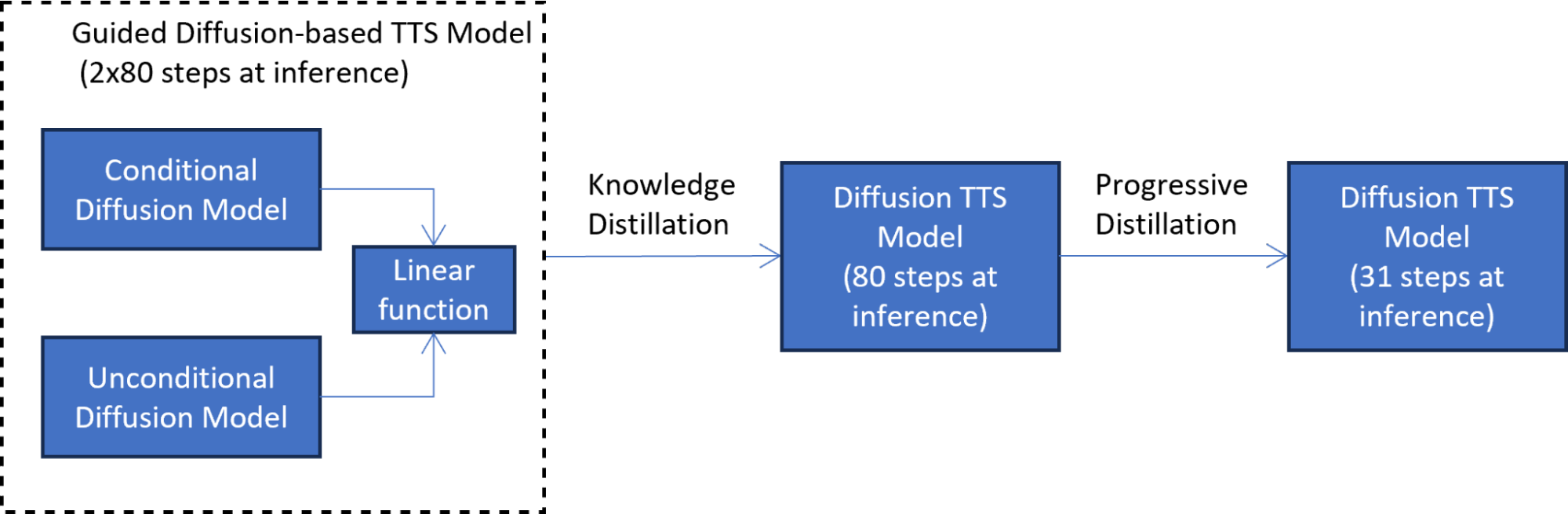
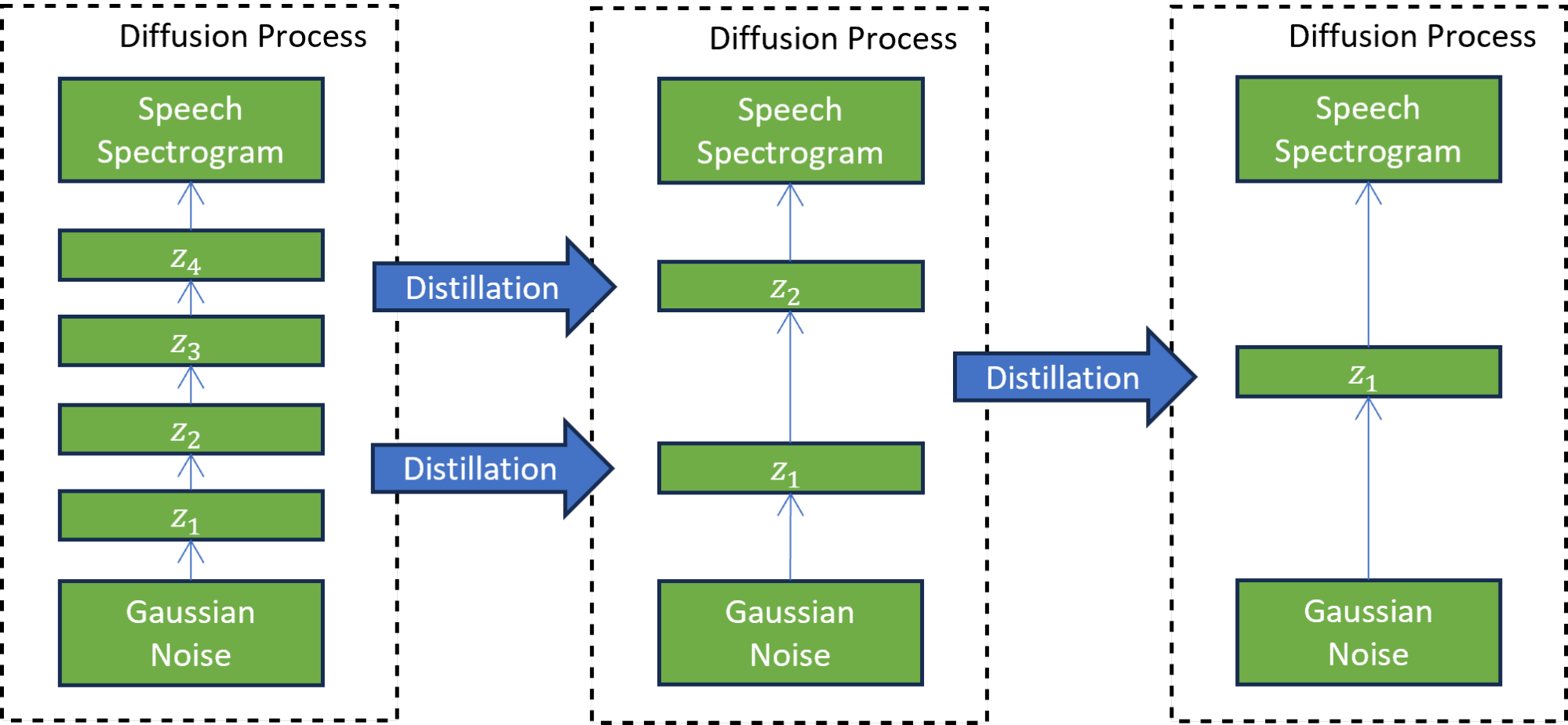
在第二個漸進升華階段(圖 3),新訓練的學生模型充當教師來訓練另一個學生模型。在這種技術中,學生模型被訓練為模仿教師模型,同時將擴散步驟的數量減少兩倍。這個過程重復多次,以進一步減少步驟數量,而每次都有一名新學生擔任下一輪蒸餾的老師。
七次迭代的漸進蒸餾將推理步驟的數量減少了 7^2 次,從訓練模型的 4000 個步驟減少到 31 個步驟。與引導擴散模型相比,這種減少導致了 5 倍的加速,不包括文本嵌入計算成本。
感知成對語音測試表明,提取的模型(在第二階段之后)與基于引導提取的 TTS 模型產生的語音質量相匹配。
例如,收聽表 1 中由基于漸進蒸餾的 TTS 模型生成的音頻樣本。樣本與來自基于引導擴散的 TTS 模型的音頻樣本的質量相匹配。如果我們簡單地將蒸餾步驟的數量減少到 31,而不是使用漸進蒸餾,則生成的語音的質量會顯著惡化。
發言者 |
基于引導擴散的 TTS 模型 (2×80 擴散步驟) |
漸進蒸餾后基于擴散的 TTS (31 個擴散步驟) |
基于引導擴散的 TTS 模型 (初始減少到 31 個擴散步驟) |
|---|---|---|---|
| 女的 1 |
Audio | Audio | Audio |
| 女性 2 | Audio | Audio | Audio |
| 女性 3 | Audio | Audio | Audio |
| 男 1 | Audio | Audio | Audio |
結論
與學術界合作,幫助年輕學生塑造他們在科學和工程領域的未來,是 NVIDIA 的核心價值觀之一。Alicja、Pawe?和 Micha?;的成功項目體現了 NVIDIA 駐波蘭華沙辦事處與當地大學的合作關系。
學生們設法解決了加快預先訓練的、基于擴散的文本到語音(TTS)模型的挑戰性問題。他們在基于擴散的 TTS 的復雜領域設計并實現了一個基于知識蒸餾的解決方案,實現了擴散過程的 5 倍加速。最值得注意的是,他們基于合成數據生成的獨特解決方案適用于預訓練的 TTS 模型,而無需訪問原始訓練數據。
我們鼓勵您探索 NVIDIA Academic Programs 并嘗試使用 NVIDIA NeMo Framework 來為生成人工智能的新時代創建完整的會話人工智能(TTS、ASR 或 NLP/LLM)解決方案。
?






