
Machine learning ( ML )采用算法和統計模型,使計算機系統能夠在大量數據中發現模式。然后,他們可以使用識別這些模式的模型對新數據進行預測或描述。
如今, ML 幾乎應用于所有行業,包括零售、醫療、運輸和金融,以提高客戶滿意度、提高生產力和運營效率。然而,獲得環境訪問權,使您能夠嘗試新的工具和技術,充其量是棘手的,最壞的情況下是令人望而卻步的。
在本文中,我將使用 RAPIDS 完成構建端到端 ML 服務的每個步驟,從數據處理到模型訓練再到推理。使用 NGC 目錄的新一鍵部署功能,您可以訪問筆記本并嘗試 ML 管道,而無需啟動基礎設施并自行安裝軟件包。
使用 AI 軟件和基礎架構加速應用程序開發
如果您已經在構建數據科學應用程序,那么您已經完成了使用 RAPIDS 的 90% 。
RAPIDS :加速機器學習
RAPIDS 是一套開源軟件庫,允許您完全在 GPU 上開發和執行端到端的數據科學和分析管道。 RAPIDS Python API 看起來和感覺上都像您已經使用的數據科學工具,如 pandas 和 scikit-learn ,因此您只需對代碼進行少量更改即可獲得好處。
RAPIDS 通過在攝取期間將數據直接帶到 GPU 上,并將其保存在那里,用于探索、特征工程和模型訓練,消除了現代數據科學工作流中的瓶頸。這允許您快速迭代 ML 工作流的早期階段,并在 GPU 上定時嘗試更高級的技術。
RAPIDS 還與其他知名框架集成,包括 XGBoost ,它提供了一個 API ,用于使用梯度增強的決策樹進行訓練和推理。
NGC 目錄: GPU 優化軟件的中心
NVIDIA NGC catalog 提供 GPU 優化的 AI 和 ML frameworks 、 SDK 和預訓練模型。它還托管了各種應用程序的示例 Jupyter Notebooks ,包括我在本文中介紹的示例。現在,只需單擊 Vertex AI Workbench ,即可輕松部署筆記本電腦。
Google Cloud Vertex AI :一個 GPU 加速的云平臺
Google Cloud Vertex AI 工作臺 是整個數據科學工作流的單一開發環境。它通過與在生產中快速構建和部署模型所需的所有服務深度集成,加快了數據工程的速度。
NVIDIA 和 Google Cloud 已合作啟用此一鍵功能,可在 Vertex AI 上以最佳配置啟動 JupyterLab 實例,預加載軟件依賴項,并一次性下載 NGC 筆記本。這允許您立即開始執行代碼,而不需要任何專業知識來配置開發環境。
如果您沒有 Google 云帳戶,請注冊以接收 free credits ,這足以構建和運行此應用程序。
獲取建筑
以下是使用 GPU 加速數據科學開始旅程所需的每一步。
訪問環境
開始之前,請確保滿足以下先決條件:
- 您已注冊 NGC account ,并已登錄。
- 您已注冊 谷歌云平臺 帳戶,并已登錄。
登錄 NGC 后,您將看到策劃的內容。
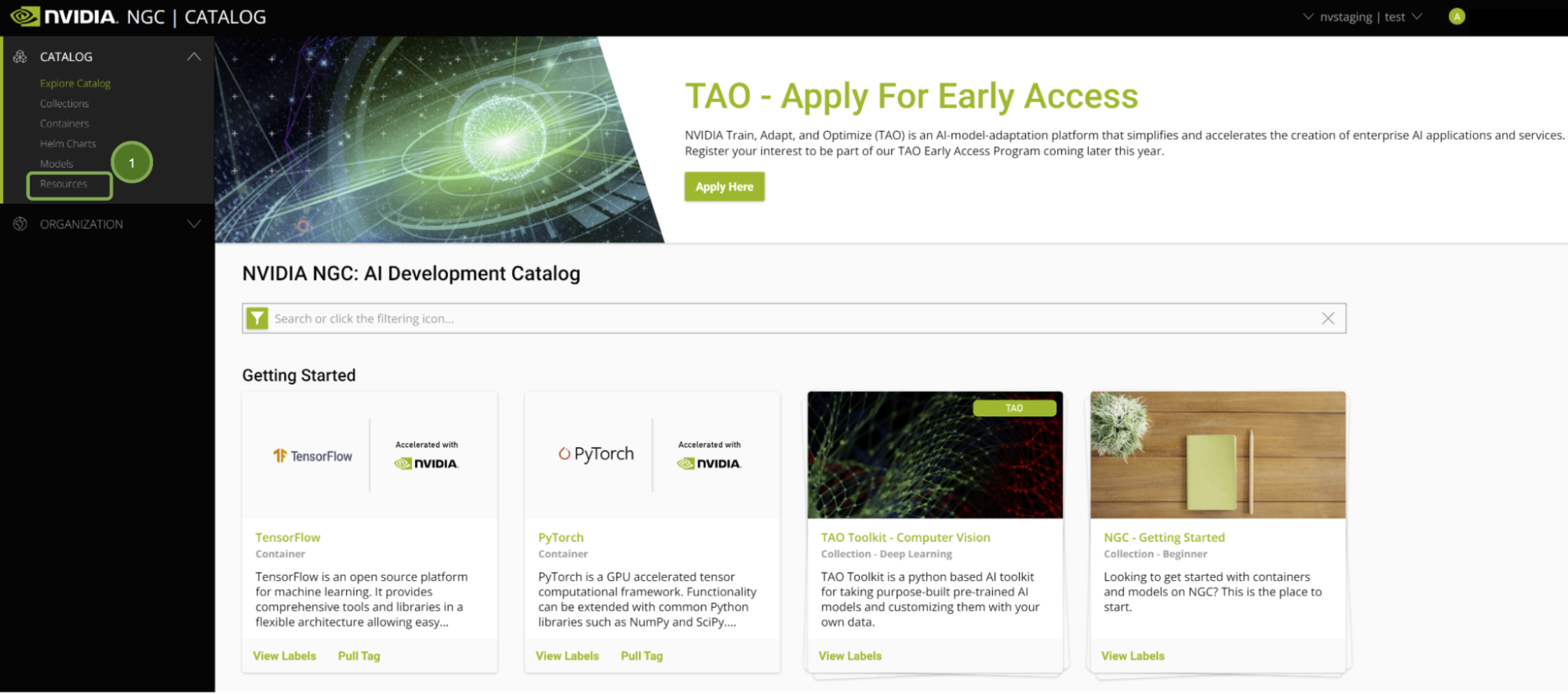
NGC 上的所有 Jupyter 筆記本電腦都托管在 Resources 選項卡下。看看 端到端 RAPIDS 工作流簡介 。此頁面包含有關 RAPIDS 庫的信息,以及筆記本中所涵蓋內容的概述。
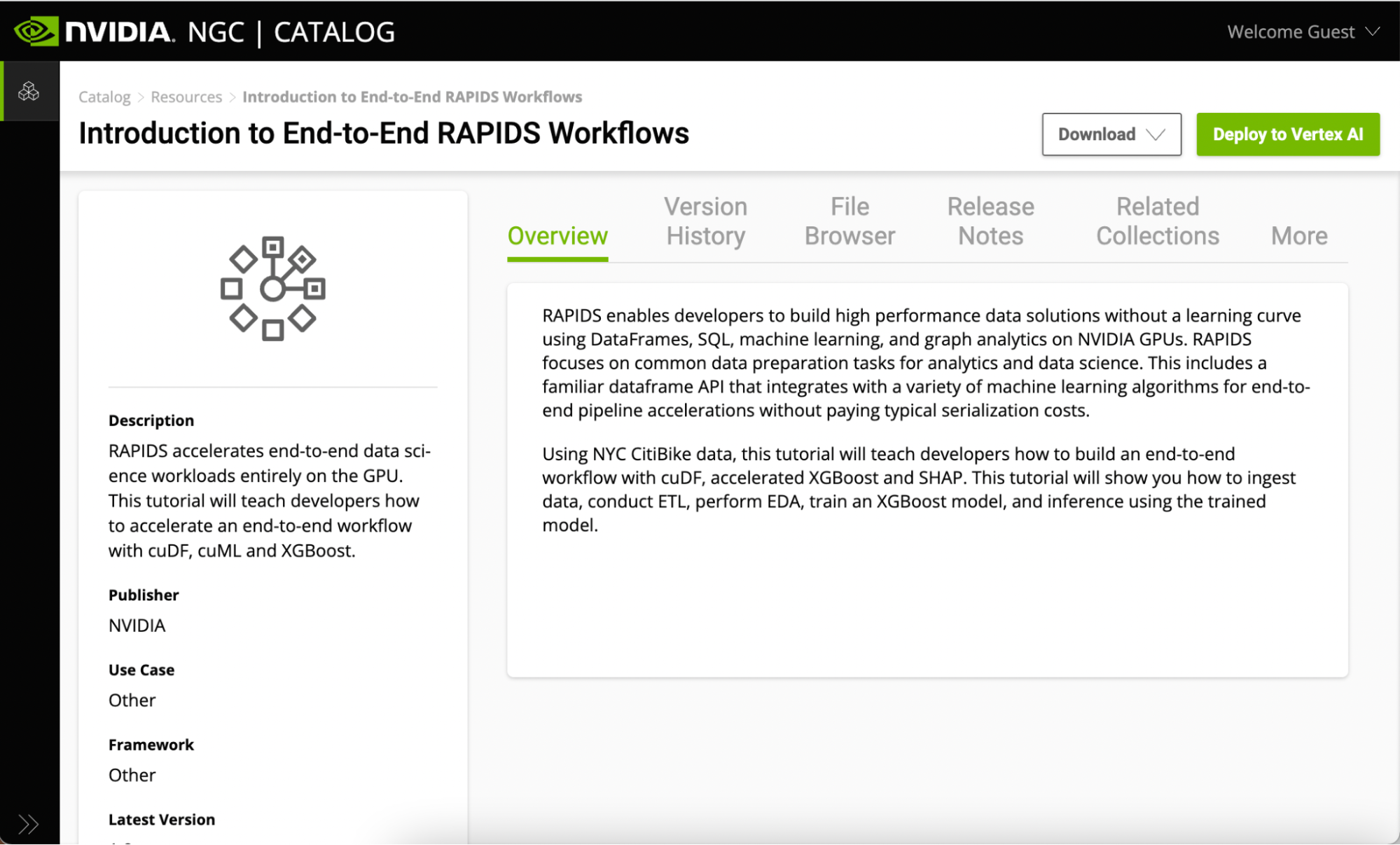
有幾種方法可以開始使用此資源中的 Jupyter 筆記本示例:
- 下載資源
- 單擊“部署到頂點 AI ”。
如果您已經擁有自己的本地或云環境并啟用了 GPU ,那么您可以下載資源并在自己的基礎設施上運行它。但是,對于這篇文章,可以使用一鍵部署功能在 Vertex AI 上運行筆記本,而無需手動安裝自己的基礎設施。
一鍵式部署功能獲取 Jupyter 筆記本,配置 GPU 實例,安裝依賴項,并提供運行 JupyterLab 界面以開始使用。
設置托管筆記本
按照簡要教程進行操作,以確保您的環境設置正確。
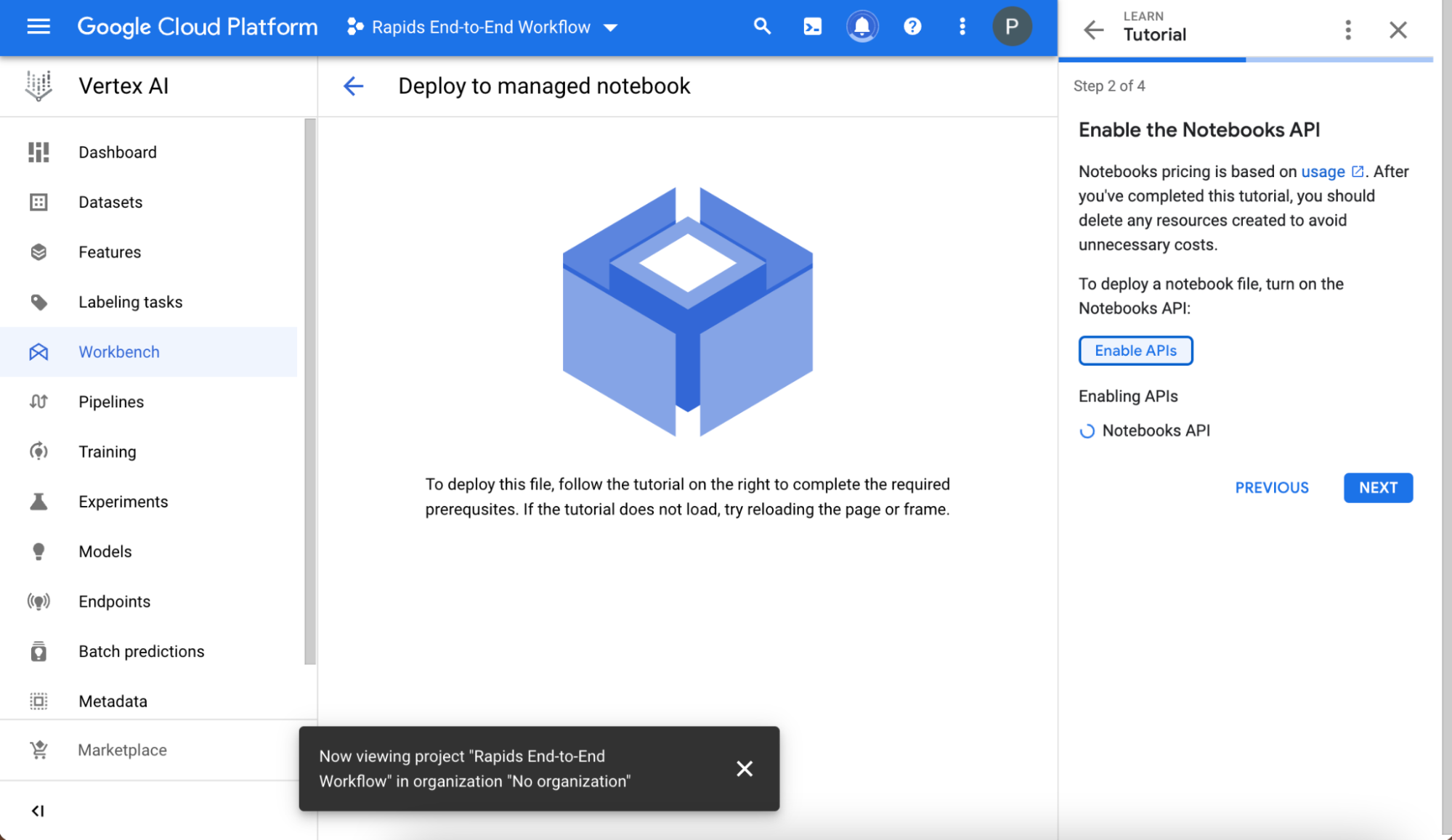
創建并命名項目,并在項目創建后在 選擇項目 字段中選擇它。記下項目名稱下方自動顯示的項目 ID 值,以備以后使用。
接下來,啟用筆記本 API 。
設置硬件
在您選擇創建以部署筆記本之前,請選擇高級設置。以下信息是預配置的,但可根據資源的要求進行定制:
- 筆記本的名稱
- 區域
- Docker 容器環境
- 機器類型,GPU 類型,GPU 數量
- 磁盤類型和數據大小
部署前:
- 檢查以確保該地區有預配置的 GPU 可用。如果 GPU 不可用,您會看到一條警告,您應該更改您的地區:
- 確保自動為我安裝 GPU 驅動程序按鈕已選中。
現在一切看起來都很好,您有了 GPU 和驅動程序,請在頁面底部選擇 Create 。創建 GPU 計算實例和設置 JupyterLab 環境大約需要幾分鐘的時間。
啟動 Jupyter
選擇 Open – > Open JupyterLab 啟動界面。 JupyterLab 接口從 NGC 提取資源(自定義容器和 Jupyter 筆記本)。內核可能需要一段時間才能拉出,所以請耐心等待!
加載后,您可以從內核選擇器中選擇 RAPIDS 內核。內核加載完成后,在左側窗格中,雙擊筆記本名稱。
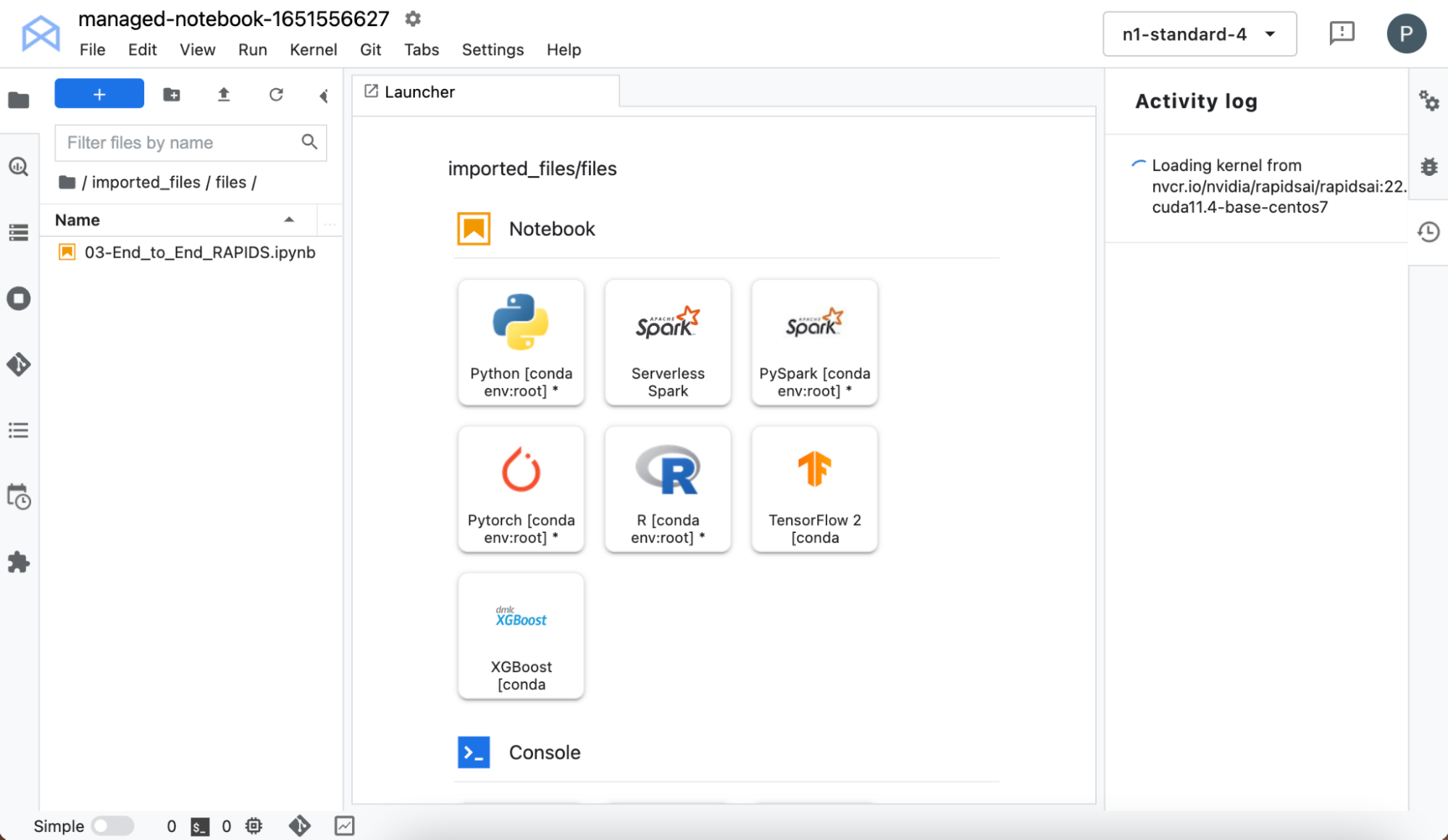
在不設置自己的基礎設施的情況下,您現在可以訪問預裝了 RAPIDS 庫的筆記本環境,這樣您就可以自己嘗試了。
使用工作流
該項目使用來自紐約市 CitiBike 自行車共享計劃 的數據。更多詳細信息可在筆記本中找到。
在深入研究數據處理之前,可以使用 NVIDIA SMI 命令查看有關 GPU 的詳細信息。這顯示了您的期望: VertexAI 已分配了一個 V100 T4 GPU ,內存為 16 GB 。
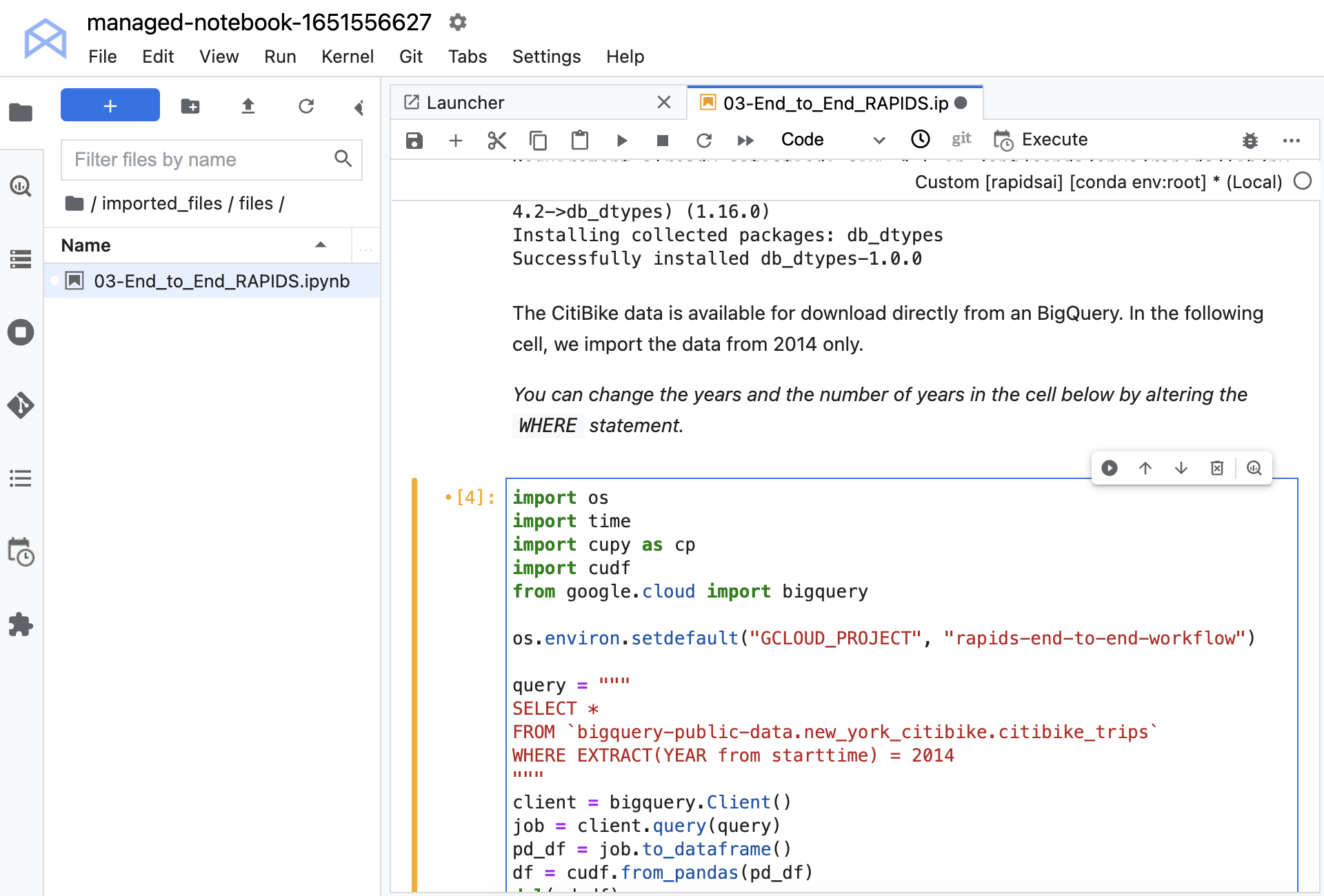
您必須安裝幾個庫,使您能夠從 Google BigQuery 加載數據。此數據集在 BigQuery 上公開可用,因此您不需要任何憑據即可加載它。使用 Python API 從大型查詢加載數據。
將數據轉換為cuDF數據幀。cuDF是 RAPIDS GPU 數據幀庫,它提供了在 GPU 上高效轉換、加載和聚合數據所需的一切。cuDF數據幀存儲在 GPU 上,這是剩余工作中保留數據的地方。這有助于利用 GPU 的速度,減少從 CPU 到 GPU 的來回傳輸,從而提供巨大的加速。
在運行筆記本之前,請取消對命令os.environ.setdefault的注釋,并將項目 ID 放入第二個參數中。如果在設置項目時不記得分配給項目的 ID ,則在選擇項目后,它會顯示在工作臺主頁上。記住使用 ID 而不是名稱。
現在,數據已加載。您可以檢查它并查看數據類型和功能摘要。每個條目都包含開始時間、停止時間、表示自行車收集地點的站點 ID 以及表示自行車下車地點的站點 ID 。還有關于自行車、上下車地點和用戶人口統計的其他信息。
數據處理
在接下來的單元中,您將處理數據以創建特征向量,這些特征向量捕獲用于訓練 ML 模型的重要信息。
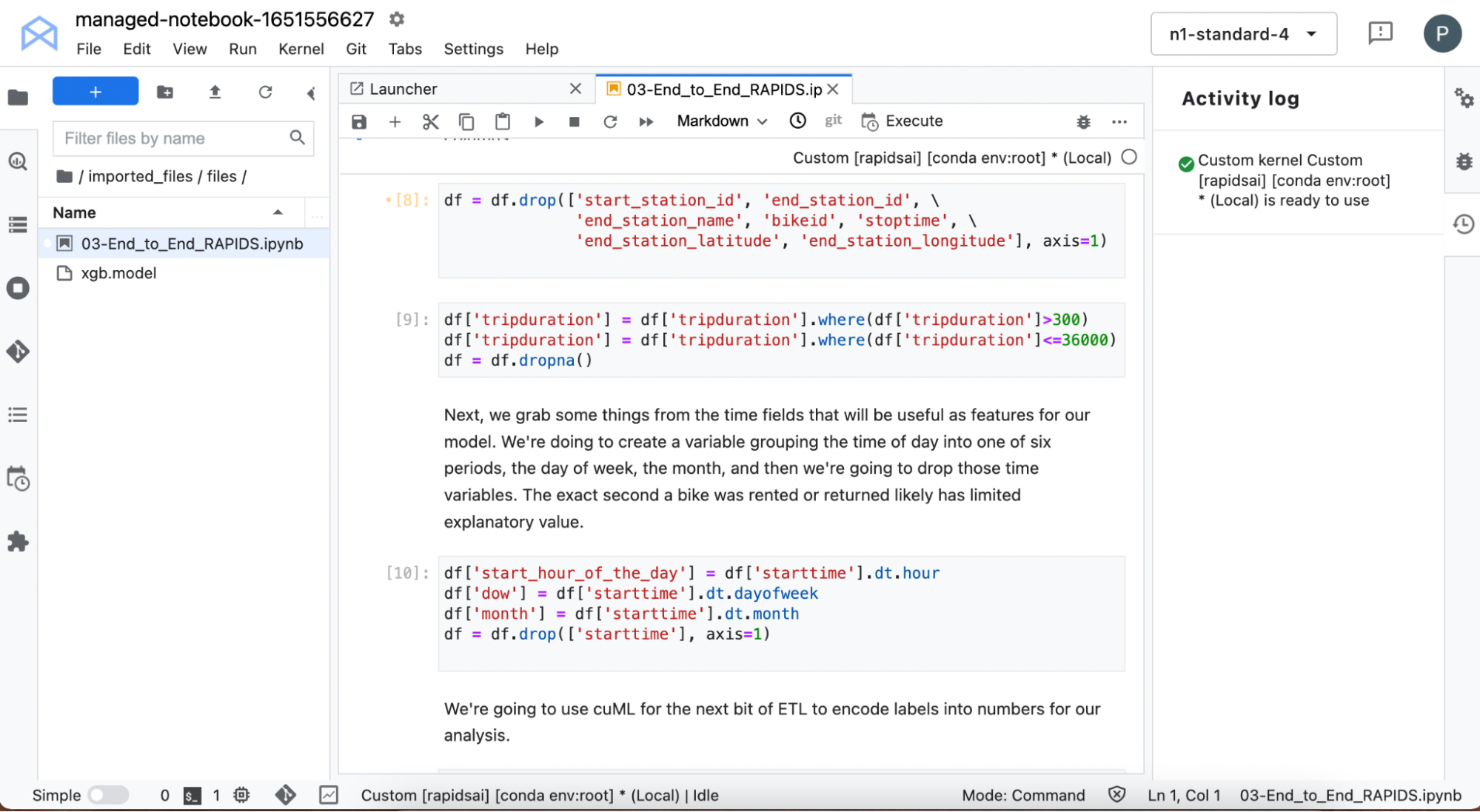
處理開始時間以提取信息,例如租用自行車的一周中的哪一天,以及一天中的小時數。您將從數據中刪除所有特征,這些特征包含關于騎乘結束的信息,因為目標是預測取車點的騎乘持續時間。
您還可以篩選出極短的騎行時間,以查找立即返回的故障自行車,以及持續時間超過 10 小時的極長騎行時間。城市自行車應該用于相對較短的城市旅行,不適合長途旅行,因此您不希望這些數據扭曲模型。
使用一些cuDF內置的時間功能來獲取自行車退房的詳細信息。執行其他一些數據處理,例如使用cuML為某些文本變量自動創建標簽編碼。
模型培訓
然后訓練 XGBoost 模型。 XGBoost 提供了一個 API ,用于使用梯度增強的決策樹進行訓練和推理。
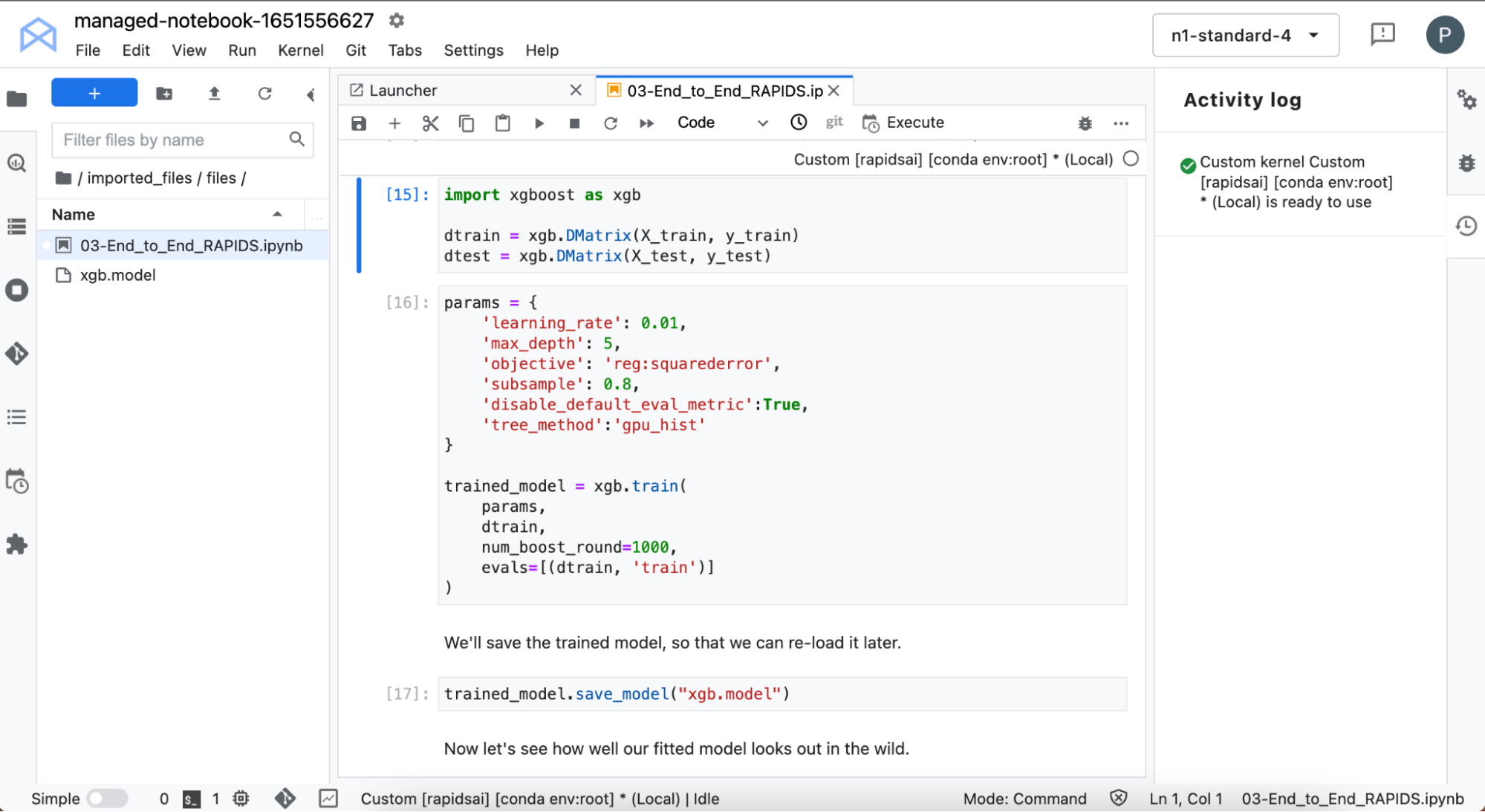
這是 GPU 上的訓練:超快速。它直接從cuDF接收您的數據,無需更改格式。
現在您已經訓練了模型,使用它來預測一些未訓練的數據的行駛時間,并將其與組真實值進行比較。在不調整任何超參數的情況下,該模型在預測行駛時間方面做得很好。我們可以做出一些改進,但現在看看哪些特征影響了模型的預測。
模型說明
當使用復雜的模型(如 XGBoost )時,理解模型所做的預測并不總是那么簡單。在本節中,您將使用 SHapley 加法解釋( SHAP )值來深入了解 ML 模型。
計算形狀值是一個計算成本很高的過程,但您可以通過在 NVIDIA GPU 上運行來加速該過程。為了節省更多時間,請計算數據子集的形狀值。
接下來,看看各個特征以及特征組合的影響。
加速推理
訓練模型通常被視為工作流程中計算成本高昂的部分,因此 GPU 在這里獨樹一幟。實際上,這是真的。但是 GPU 也可以大大加快對某些模型進行預測所需的時間。
重新加載模型,因為 XGBoost 會緩存以前的預測,并在 CPU 和 GPU 上進行預測時計時。
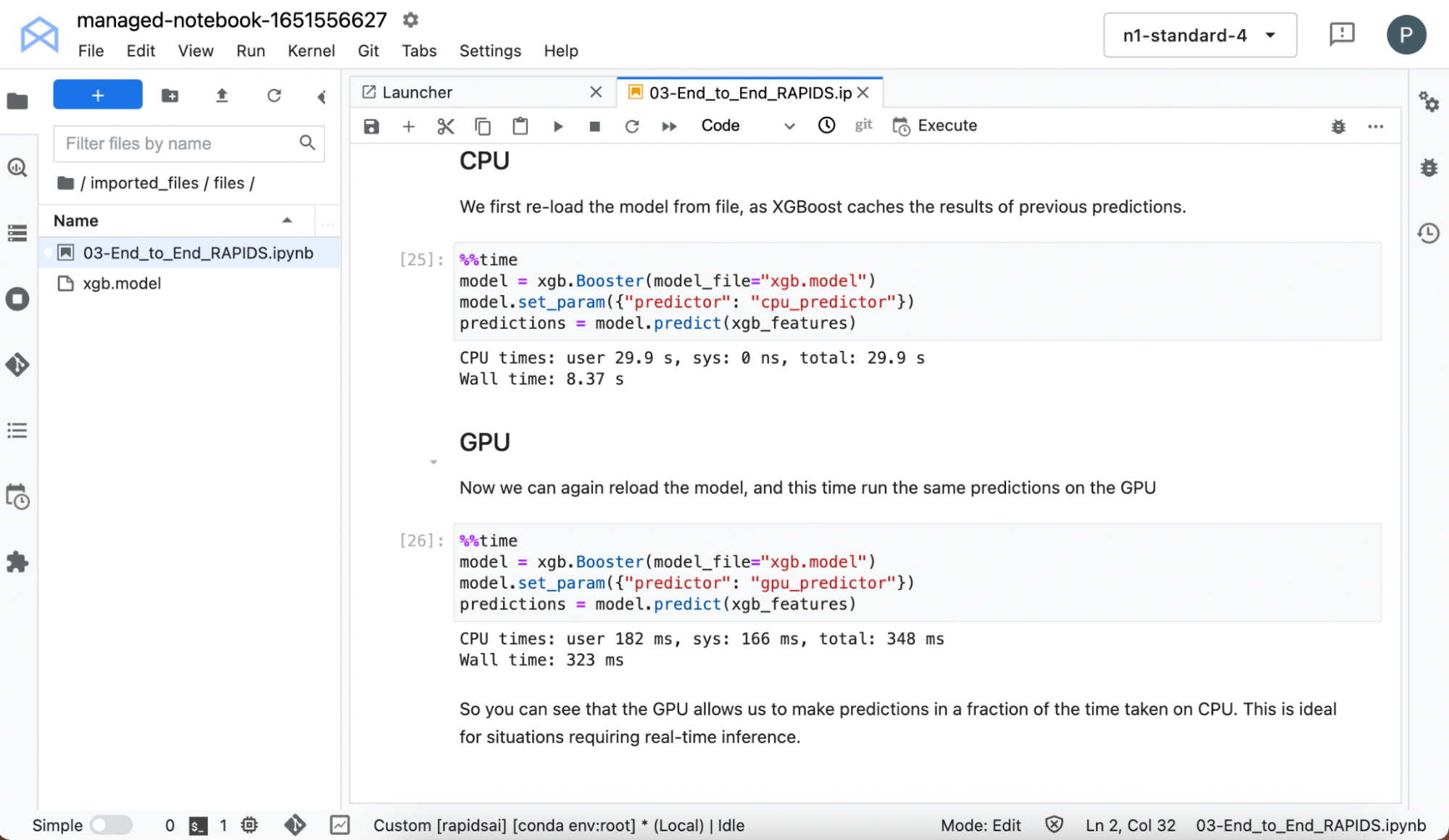
即使在這個小數據集和簡單模型上,您也可以看到在 GPU 上運行時推理的巨大加速。
結論
RAPIDS 使您能夠在 GPU 上執行端到端工作流,使您能夠考慮更復雜的技術并更快地洞察數據。
使用 NGC catalog 的一鍵式部署功能,您可以在幾分鐘內訪問具有 RAPIDS 的環境,并且開發您的 ML 管道,而無需啟動自己的基礎設施或自行安裝庫。
很容易開始!按照這些步驟進行操作,您就可以加快所有數據科學工作的速度,而不必為設置基礎架構而煩惱。
了解更多關于 RAPIDS 的信息,并聯系 Twitter 上的 RAPIDS 團隊。當然,通過搜索 NGC catalog 可以獲得更易于部署的模型和示例。
?





