
這篇文章最初發表在 RAPIDS AI 博客here上。
PyCaret是一個低代碼 Python 機器學習庫,基于流行的 R Caret 庫。它自動化了從數據預處理到 i NSight 的數據科學過程,因此短代碼行可以用最少的人工完成每個步驟。此外,使用簡單的命令比較和調整許多模型的能力可以簡化效率和生產效率,同時減少創建有用模型的時間。
PyCaret 團隊在 2 . 2 版中添加了 NVIDIA GPU 支持,包括RAPIDS中所有最新和最偉大的版本。使用 GPU 加速, PyCaret 建模時間可以快 2 到 200 倍,具體取決于工作負載。
這篇文章將介紹如何在 GPU 上使用 PyCaret 以節省大量的開發和計算成本。
所有基準測試都是在一臺 32 核 CPU 和四個 NVIDIA Tesla T4 的機器上運行的,代碼幾乎相同。為簡單起見, GPU 代碼編寫為在單個 GPU 上運行。
PyCaret 入門
使用 PyCaret 與導入庫和執行 setup 語句一樣簡單。setup()功能創建環境,并提供一系列預處理功能,一氣呵成。
from pycaret.regression import *
exp_reg = setup(data = df, target = ‘Year’, session_id = 123, normalize = True)在一個簡單的設置之后,數據科學家可以開發其管道的其余部分,包括數據預處理/準備、模型訓練、集成、分析和部署。在準備好數據后,最好從比較模型開始。
與 PyCaret 的簡約精神一樣,我們可以通過一行代碼來比較一系列標準模型,看看哪些模型最適合我們的數據。 compare _ models 命令使用默認超參數訓練 PyCaret 模型庫中的所有模型,并使用交叉驗證評估性能指標。然后,數據科學家可以根據這些信息選擇他們想要使用的模型、調整和集成。
top3 = compare_models(exclude = [‘ransac’], n_select=3)比較模型
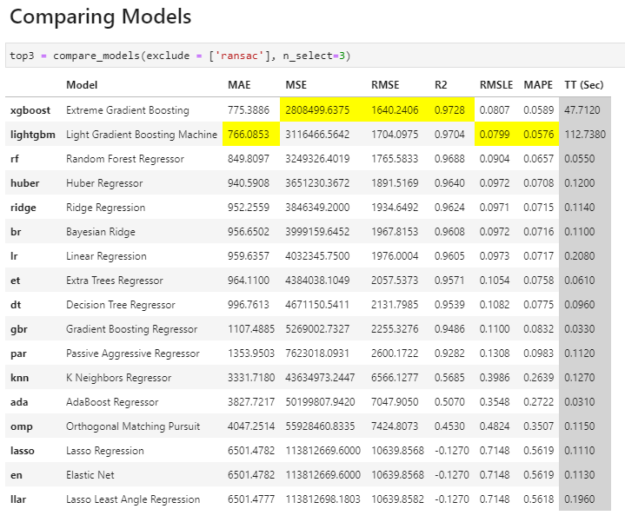
**模型從最佳到最差排序, PyCaret 突出顯示了每個度量類別中的最佳結果,以便于使用。
用 RAPIDS cuML 加速 PyCaret
PyCaret 對于任何數據科學家來說都是一個很好的工具,因為它簡化了模型構建并使運行許多模型變得簡單。使用 GPU s , PyCaret 可以做得更好。由于 PyCaret 在幕后做了大量工作,因此看似簡單的命令可能需要很長時間。例如,我們在一個具有大約 50 萬個實例和 90 多個屬性(加州大學歐文分校的年度預測 MSD 數據集)的數據集上運行了前面的命令。在 CPU 上,花費了 3 個多小時。在 GPU 上,只花了不到一半的時間。
在過去,在 GPU 上使用 PyCaret 需要許多手動編碼,但謝天謝地, PyCaret 團隊集成了 RAPIDS 機器學習庫( cuML ),這意味著您可以使用使 PyCaret 如此有效的相同簡單 API ,同時還可以使用 GPU 的計算能力。
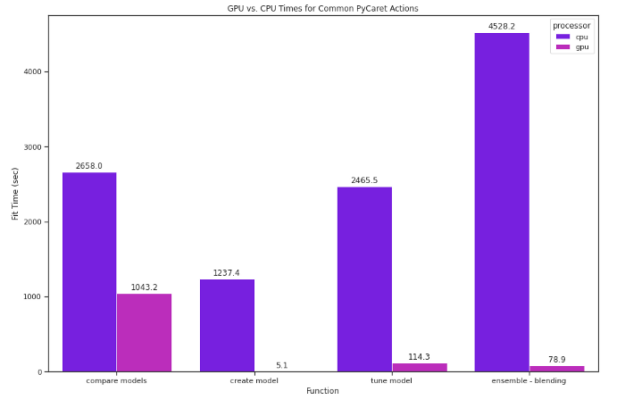
在 GPU 上運行 PyCaret 往往要快得多,這意味著您可以充分利用 PyCaret 提供的一切,而無需平衡時間成本。使用剛才提到的同一個數據集,我們在 CPU 和 GPU 上測試了 PyCaret ML 功能,包括比較、創建、調優和集成模型。切換到 GPU 很簡單;我們在設置函數中將use_gpu設置為True:
exp_reg = setup(data = df, target = ‘Year’, session_id = 123, normalize = True, use_gpu = True)PyCaret 設置為在 GPU 上運行,它使用 cuML 來訓練以下所有型號:
- 對數幾率回歸
- 脊分類器
- 隨機森林
- K 鄰域分類器
- K 鄰域回歸器
- 支持向量機
- 線性回歸
- 嶺回歸
- 套索回歸
- 群集分析
- 基于密度的空間聚類
僅在 GPU 上運行相同的compare_models代碼的速度是 GPU 的2.5倍多。
對于流行但計算昂貴的模型,在模型基礎上的影響更大。例如, K 鄰域回歸器在 GPU 上的速度是其 265 倍。
影響
PyCaret API 的簡單性釋放了原本用于編碼的時間,因此數據科學家可以做更多的實驗并對實驗進行微調。當與 GPU 配合使用時,這種影響甚至更大,因為充分利用 PyCaret 的評估和比較工具套件的計算成本顯著降低。
結論
廣泛的比較和評估模型有助于提高結果的質量,而 PyCaret 正是為了這樣做。 GPU 上的 PyCaret 抵消了大量處理所帶來的時間成本。
RAPIDS 的目標是加速您的數據科學, PyCaret 是越來越多的庫之一,它們與 RAPIDS 套件的兼容性有助于為您的機器學習追求帶來新的效率。
**可在此處找到用于此筆記本的代碼。
 by
by 




