深度學習徹底改變了我們分析、理解和處理數據的方式,而且在各個領域的應用中都取得了巨大的成功,其在計算機視覺、自然語言處理、醫療診斷和醫療保健、自動駕駛汽車、推薦系統以及氣候和天氣建模方面有許多成功案例。
在神經網絡模型不斷變大的時代,對計算速度的高需求對硬件和軟件都形成了巨大的挑戰。模型剪枝和低精度推理是非常有效的解決方案。
自 NVIDIA Ampere 架構開始, 隨著 A100 Tensor Core GPU 的推出,NVIDIA GPU 提供了可用于加速推理的細粒度結構化稀疏功能。在本文中,我們將介紹此類稀疏模型的訓練方法以保持模型精度,包括基本訓練方法、漸進式訓練方法以及與 int8 量化的結合。我們還將介紹如何利用 Ampere 架構的結構化稀疏功能進行推理。
騰訊機器學習平臺部門 (MLPD) 利用了漸進式訓練方法,簡化了稀疏模型訓練并實現了更高的模型精度。借助稀疏功能和量化技術,他們在騰訊的離線服務中實現了 1.3 倍~1.8 倍的加速。
NVIDIA Ampere 架構的結構化稀疏功能
NVIDIA Ampere 和 NVIDIA Hopper 架構 GPU 增加了新的細粒度結構化稀疏功能,該功能主要用于加速推理。此功能是由稀疏 Tensor Core 提供,這些稀疏 Tensor Core 需要 2: 4 的稀疏模式。也就是說,以 4 個相鄰權重為一組,其中至少有 2 個權重必須為 0,即 50% 的稀疏率。
這種稀疏模式可實現高效的內存訪問能力,有效的模型推理加速,并可輕松恢復模型精度。在模型壓縮后,存儲格式只存儲非零值和相應的索引元數據(圖 1)。稀疏 Tensor Core 在執行矩陣乘法時僅處理非零值,理論上,計算吞吐量是同等稠密矩陣乘法的 2 倍。
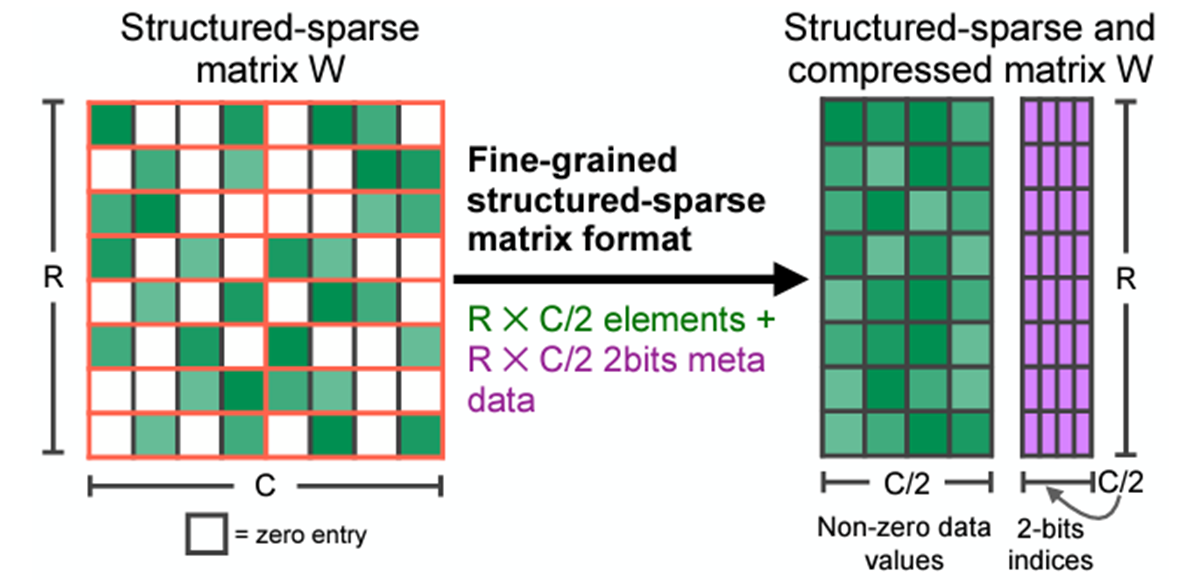
圖 1. 2: 4 結構化稀疏模式及其壓縮格式
結構化稀疏功能主要應用于能夠提供 2: 4 稀疏權重的全連接層和卷積層。如果提前對這些層的權重做剪枝,則這些層可以使用結構化稀疏功能來進行加速。
訓練方法
由于直接對權重做剪枝會降低模型精度,因此在使用結構化稀疏功能的時候,您需要進行訓練來恢復模型精度。下面,我們將介紹一些基本訓練方法和新的漸進式訓練方法。
基本訓練方法
基本訓練方法可保持模型精度,并且無需任何超參數調優。了解更多技術細節,請參閱論文Accelerating Sparse Deep Neural Networks。
基本訓練方法易于使用,步驟如下:
- 訓練一個常規稠密模型,不需要稀疏化的特殊處理。
- 對全連接層和卷積層上的權重以 2: 4 的稀疏模式進行剪枝。
- 按照以下規則重新訓練經過剪枝的模型:
- 將所有權重初始化為第 2 步中的值。
- 使用與第 1 步相同的優化器和超參數(學習率、調度方法、訓練次數等)進行稀疏調優訓練。
- 保持第 2 步中剪枝后的稀疏模式。
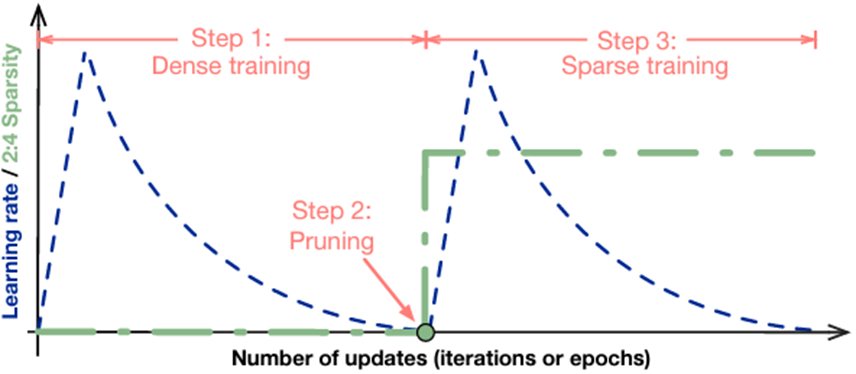
圖 2. 基本訓練方法
對于復雜情況,還有一些進階的方法。
例如,把稀疏訓練應用在多階段式的稠密模型訓練當中。比如對于一些目標檢測模型,如果下游任務的數據集足夠大,您只需做稀疏調優訓練。對于像 BERT-SQuAD 等模型,調優階段使用的數據集相對較小,您則需要在預訓練階段進行稀疏訓練以獲得更好的模型精度。
此外,通過在稀疏調優之前插入量化節點,您可以輕松將稀疏調優與 int8 量化調優結合起來。所有這些訓練以及調優方法都是一次性的,即最終獲得的模型只需要經過一次稀疏訓練處理。
漸進式稀疏訓練方法
一次性稀疏調優(fine-tuning)可以覆蓋大多數任務,并在不損失精度的情況下實現加速。然而,就一些對權重數值變化敏感的困難任務而言,對所有權重做一次性稀疏訓練會導致大量信息損失。在小型數據集上只做稀疏化調優可能會很難恢復精度,對于這些任務而言,就需要稀疏預訓練(pretraining)。
然而稀疏預訓練需要更多數據,而且更加耗時。因此,受到卷積神經網絡剪枝方法的啟發,我們引入了漸進式稀疏訓練方法,在此類任務上僅應用稀疏化調優便可以實現模型的稀疏化,同時不會造成明顯的精度損失。了解更多細節,請參閱論文 Learning both Weights and Connections for Efficient Neural Networks 。

圖 3. 漸進式稀疏訓練的概念
漸進式稀疏訓練方法的核心思想是將目標稀疏率進行若干次切分。
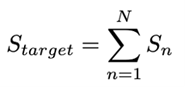
如上述公式和圖 4 所示,對于目標稀疏率 S,我們將其分為 N份,這將有助于在稀疏調優過程中快速恢復信息。根據我們的實驗,在相同的調優迭代次數內,使用漸進式稀疏訓練相比一次性稀疏訓練,可以獲得更高的模型精度。
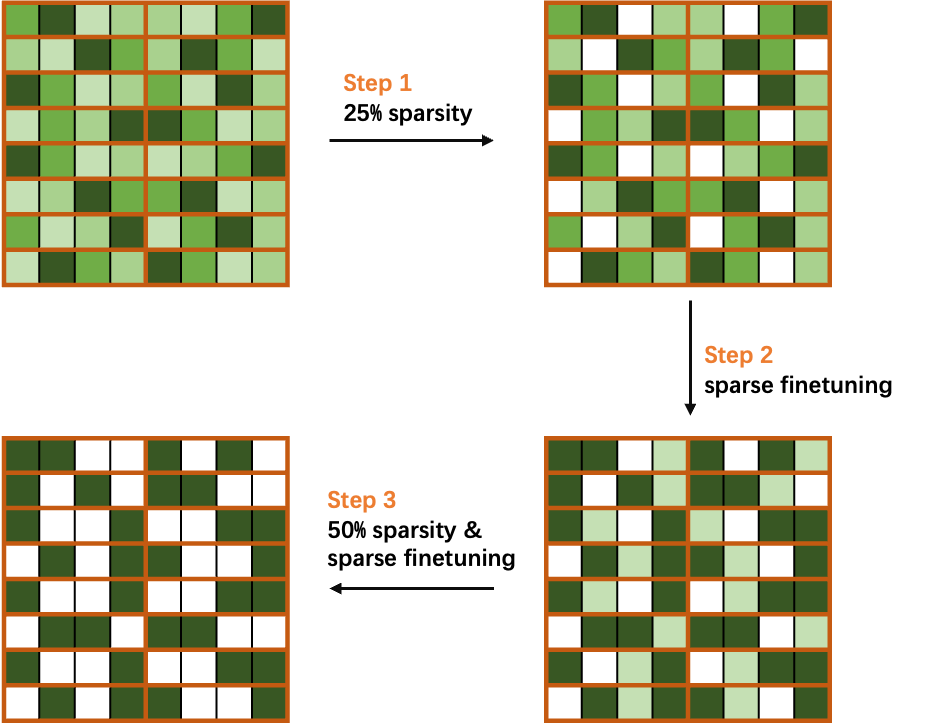
圖 4. 漸進式稀疏訓練方法 (以50% 稀疏率的 2: 4 結構化稀疏模式為例)
我們以 50% 稀疏率的 2: 4 結構化稀疏為例,將稀疏率分為兩份,然后逐步稀疏和調優模型中的權重參數。如圖 4 所示,首先計算權重掩碼以實現 25% 的稀疏率,然后執行稀疏調優以恢復模型精度。接下來,重新對剩余權重計算權重掩碼以達到 50% 的稀疏率,并對網絡進行調優,以獲得一個精度無損的稀疏模型。
Sparse-QAT:稀疏化與量化、蒸餾相結合
為了獲得更輕量的模型,我們進一步將稀疏與量化、蒸餾相結合,即 Sparse-QAT。
量化(PTQ 和 QAT)
下方的公式表示一個通用的量化過程。對于32位浮點數值 x,我們使用 Q [x] 表示其具有 K-bits 表示的量化值。
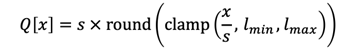
通常情況下,我們首先將原始參數量化到特定范圍,并將其近似為整數。然后,可以使用這個量化比例scale (s) 來恢復原始值。這樣就得到了第一種量化方法,即校準,也稱為訓練后量化(post-training quantization, PTQ)。在校準中,一個關鍵的因素是要設置一個適當的量化比例(scale)。如果這個比例值過大,量化范圍內的數字將不太準確。相反,如果這個比例值過小,會導致大量的數字落在 lmin 到 lmax 的范圍之外。因此,為了平衡這兩個方面,我們首先獲得張量中數值的統計分布,然后設置量化比例以覆蓋 99.99% 的數值。許多工作已經證明,這種方法對于在校準過程中找到合適的量化比例非常有幫助。
然而,盡管我們已經為校準設置了一個合理的量化比例,但是對于 8 bit 量化來說,模型精度仍然會顯著下降。因此,我們引入量化感知訓練(quantization-aware training, QAT),以進一步提高校準后的精度。QAT 的核心思想是以模擬量化的方法來訓練模型。
在前向傳播過程中,我們將權重量化為 int8,然后將其反量化為浮點數來模擬真實量化。在反向傳播過程中,引入straight through estimation (STE)的方法來更新模型權重。STE 的核心思想可以用如下公式表示:
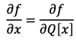
由上述公式可知,閾值范圍內的值對應的梯度直接反向傳播,超出閾值范圍的值對應的梯度被裁剪為 0。
知識蒸餾
除了上述方法外,我們還引入了知識蒸餾(knowledge distilation, KD),以進一步確保 Sparse-QAT 模型的精度。我們以原始稠密模型作為教師模型,以量化稀疏模型作為學生模型。在調優過程中,我們采用了 Mini-distillation,這是一種層級別的蒸餾方法。使用 MiniLM,我們只需要使用 Transformer 模型最后一層的輸出。引入蒸餾作為輔助工具甚至可以獲得比 教師模型精度更高的稀疏量化學生模型。了解更多信息,請參閱 MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers。
Sparse-QAT 訓練流水線
圖 5 顯示了 Sparse-QAT 的訓練流水線。稀疏化、量化、蒸餾以并行的方式執行,最終獲得一個稀疏的 int8 量化模型。整個流水線包括如下三條路徑:
- 在稀疏路徑中,應用漸進式稀疏化來獲取一個稀疏權重張量。
- 在量化路徑中,使用 PTQ 和 QAT 來獲取 int8 類型的權重張量。
- 在知識蒸餾路徑中,使用 MiniLM 來進一步保障最終稀疏 int8 模型的精度。
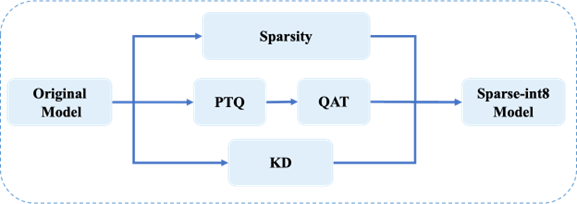
圖 5. Sparse-QAT 流水線
使用 NVIDIA Ampere 架構的結構化稀疏功能進行推理
在訓練好稀疏模型后,您可以使用 NVIDIA TensorRT 和 cuSPARSELt 庫來加速基于 NVIDIA Ampere 架構結構化稀疏功能的推理。
使用 NVIDIA TensorRT 進行推理
自 8.0 版本開始,TensorRT 可以支持稀疏卷積,矩陣乘法 (GEMM) 需要用 1×1 的卷積替代來進行稀疏化推理。在 TensorRT 中啟用稀疏化推理非常簡單。在導入 TensorRT 之前,模型的權重應具有 2: 4 的稀疏模式。如果使用 trtexec 構建引擎,只需設置 -sparity=enable 標志即可。如果您正在編寫代碼或腳本來構建引擎,只需按如下所示設置構建配置:
對于 C++:config->setFlag(BuilderFlag::kSPARSE_WEIGHTS)
對于 Python:config.set_flag(trt.BuilderFlag.SPARSE_WEIGHTS)
使用 NVIDIA cuSPARSELt 庫增強 TensorRT
在某些用例中,TensorRT 可能因為輸入尺寸不同而無法提供最佳性能。您可以使用 cuSPARSELt 進一步加速這些用例。
解決方案是使用 cuSPARSELt 編寫 TensoRT 插件,我們可以為不同的輸入尺寸初始化多個描述符以及多個 cuSPARSELt 稀疏矩陣乘法 plan,并根據輸入尺寸選擇合適的 plan。
假設您在實現 SpmmPluginDynamic 插件,該插件繼承自 nvinfer1:: IPluginV2DynamicExt,您可以使用一個私有結構來存儲這些 plan。
struct cusparseLtContext {
??? cusparseLtHandle_t handle;
??? std::vector<cusparseLtMatmulPlan_t> plans;
??? std::vector<cusparseLtMatDescriptor_t> matAs, matBs, matCs;
??? std::vector<cusparseLtMatmulDescriptor_t> matmuls;
??? std::vector<cusparseLtMatmulAlgSelection_t> alg_sels;
}TensorRT 插件應實現 configurePlugin 方法,該方法會根據輸入和輸出類型及尺寸設置插件。您需要在這個函數當中初始化 cuSPARSELt 的相關結構。
cuSPARSELt 的輸入尺寸有一些限制,應為 4、8 或 16 的倍數,具體取決于數據類型。在本文中,我們將其設置為 16 的倍數。了解該限制條件的相關信息,請查看此文檔。
for (int i = 0; i < size_num; ++i) {
? m = 16 * (i + 1);
? int alignment = 16;
? CHECK_CUSPARSE(cusparseLtStructuredDescriptorInit(
????? &handle, &matBs[i], n, k, k, alignment, type, CUSPARSE_ORDER_ROW,
????? CUSPARSELT_SPARSITY_50_PERCENT))
? CHECK_CUSPARSE(cusparseLtDenseDescriptorInit(
????? &handle, &matAs[i], m, k, k, alignment, type, CUSPARSE_ORDER_ROW))
? CHECK_CUSPARSE(cusparseLtDenseDescriptorInit(
????? &handle, &matCs[i], m, n, n, alignment, type, CUSPARSE_ORDER_ROW))
? CHECK_CUSPARSE(cusparseLtMatmulDescriptorInit(
????? &handle, &matmuls[i], CUSPARSE_OPERATION_NON_TRANSPOSE,
????? CUSPARSE_OPERATION_TRANSPOSE, &matAs[i], &matBs[i], &matCs[i], &matCs[i], compute_type))
? CHECK_CUSPARSE(cusparseLtMatmulAlgSelectionInit(
????? &handle, &alg_sels[i], &matmuls[i], CUSPARSELT_MATMUL_ALG_DEFAULT))
? int split_k = 1;
? CHECK_CUSPARSE(cusparseLtMatmulAlgSetAttribute(
????? &handle, &alg_sels[i], CUSPARSELT_MATMUL_SPLIT_K, &split_k, sizeof(split_k)))
? int alg_id = 0;
? CHECK_CUSPARSE(cusparseLtMatmulAlgSetAttribute(
????? &handle, &alg_sels[i], CUSPARSELT_MATMUL_ALG_CONFIG_ID, &alg_id, sizeof(alg_id)))
? size_t ws{0};
? CHECK_CUSPARSE(cusparseLtMatmulPlanInit(&handle, &plans[i], &matmuls[i], &alg_sels[i],
????????????????????????????????????????? ws))
? CHECK_CUSPARSE(
????? cusparseLtMatmulGetWorkspace(&handle, &plans[i], &ws))
? workspace_size = std::max(workspace_size, ws);
}在 enqueue 函數中,您可以檢索適當的 plan 來執行矩陣乘法。
int m = inputDesc->dims.d[0];
int idx = (m + 15) / 16 - 1;
float alpha = 1.0f;
float beta = 0.0f;
auto input = static_cast<const float*>(inputs[0]);
auto output = static_cast<float*>(outputs[0]);
cusparseStatus_t status = cusparseLtMatmul(
??? &handle, &plans[idx], &alpha, input,
??? weight_compressed, &beta, output, output, workSpace, &stream, 1);搜索引擎中的應用
在本部分中,我們將展示在搜索引擎中應用了稀疏化加速的四個應用案例:
- 第一是搜索中的相關性預測,旨在評估輸入文本和數據庫中視頻之間的相關性。
- 第二是查詢性能預測,用于文檔召回交付策略。
- 第三是用于召回最相關文本的召回任務。
- 第四是文生圖任務,該任務根據輸入的提示詞自動生成相應的圖片。
搜索相關性案例
我們使用 PNR (Positive Negative Rate,正負率) 或 ACC (accuracy, 精度) 標準來評估稀疏化加速在這些應用案例的效果。在相關性案例 1 中,我們運行 Sparse-QAT 獲得了一個稀疏 int8 模型,該模型在兩個重要的 PNR 評估指標均優于在線 int8 模型。
表 1. 搜索引擎的搜索相關性案例 1 (PNR)
| 模型 | 評估 指標 A | 評估 指標B |
| Float32 | 4.0138 | 3.1384 |
| Int8(在線) | 3.9454 | 2.9120 |
| 稀疏 Int8 | 4.0406 | 2.9591 |
在相關性案例 2 中,稀疏 int8 模型可以獲得與 float32 模型接近的 Acc 分數,相比稠密 int8 模型,其獲得了 1.4 倍的推理加速。
表 2. 搜索引擎的搜索相關性案例 2 (PNR)
| 評估 指標 | |
| Bert_12L ( Float32) | 0.8015 |
| Bert_12L ( Sparse-Int8) | 0.8010 |
查詢性能預測案例
在這部分,我們展示了查詢性能預測 (query performance prediction, QPP) 的四個用例,其效果使用 NDCG(normalized discounted cumulative gain, 標準化折扣累積增益)評估。如表 3 所示,這些稀疏 float16 模型甚至可以獲得比原始 float32 模型更高的NDCG分數,同時推理速度相比于float32 模型提高了 4 倍。
表 3. 搜索引擎中的查詢性能預測案例
| 案例 A | 案例 B | 案例 C | 案例 D | |
| NDCG(float32) | 39723 | 39858 | 39878 | 32471 |
| NDCG(稀疏 float16) | 39744 | 39927 | 39909 | 32494 |
| 相對推理時間 (float32) | 1 | 1 | 1 | 1 |
| 相對推理時間 (稀疏 float16) | 0.25 | 0.25 | 0.25 | 0.25 |
| 推理加速比例 | 4 倍 | 4 倍 | 4 倍 | 4 倍 |
文檔查詢案例
表 4 顯示了搜索引擎中文檔查詢案例的結果,與稠密 int8 模型相比,使用我們推薦的 Sparse-QAT 訓練流水線,稀疏 int8 模型可以實現 1.4 倍的推理加速,準確度損失可忽略不計。
表 4. 搜索引擎中的文檔查詢案例
| Acc | f1_ 345 | recall_ 345 | |
| Float32 模型 | 0.7839 | 0.8627 | 0.8312 |
| 稀疏 int8 模型 | 0.7814 | 0.8622 | 0.8416 |
文生圖案例
圖 6 展示了文生圖模型的結果,上面四張圖片是用稠密 float32 模型輸出,下面四張圖片是用稀疏 float16 模型輸出。
從結果中您會發現,輸入相同的提示,稀疏模型可以輸出與稠密模型相當的結果。而且引入模型稀疏化和額外的漸進式稀疏調優使得模型從數據中學習到了更多內容,因此部分稀疏模型的輸出結果看起來更為合理。

圖 6. 搜索引擎中的文生圖案例
總結
NVIDIA Ampere 架構中的結構化稀疏功能可以加速許多深度學習工作負載,并且易于結合 TensorRT 和 cuSPARSELt 稀疏加速庫一起使用。
如需了解更多信息,請觀看 GTC 演講:NVIDIA Ampere 架構的結構化稀疏功能及其在騰訊微信搜索中的應用。
下載最新的 TensorRT 和 cuSPARSELt:TensorRT 下載以及 cuSPARSELt 下載。
?
?
?
?