金融服務欺詐是一個巨大的問題。根據 NASDAQ 的數據,在 2023 年,銀行在支付、支票和信用卡欺詐方面預計會面臨 442 億美元的損失。不過,這不僅僅與資金有關。欺詐會損害公司的聲譽,并在阻止合法購買時讓客戶失望。這被稱為 誤報 。遺憾的是,這些錯誤發生的頻率比您想象的要多,因為傳統的欺詐檢測方法根本跟不上欺詐的復雜性。
本文重點介紹信用卡交易欺詐,這是一種最常見的金融欺詐形式。雖然其他類型的欺詐(例如身份盜用、帳戶接管和反洗錢)也值得關注,但信用卡欺詐由于其交易量大、攻擊面廣,因此構成了一項獨特的挑戰,使其成為欺詐者的主要目標。據 Nilson 估計,到 2026 年,金融機構每年的信用卡損失預計將達到 430 億美元。
傳統的欺詐檢測方法依賴于基于規則的系統或統計方法,在識別復雜的欺詐活動方面反應遲鈍,并且效率越來越低。隨著數據量的增長和欺詐策略的演變,金融機構需要更主動、更智能的方法來檢測和預防欺詐交易。
AI 為分析大量交易數據、識別異常行為和識別出可能存在欺詐的模式提供了必不可少的工具。但是,盡管已經采取措施改進欺詐檢測,但仍需要更先進的技術來提高檢測準確性、減少誤報率,并提高欺詐檢測的運營效率。
本文介紹了端到端的 AI 工作流,該工作流使用圖形神經網絡(GNN)提供靈活、高性能的欺詐檢測解決方案。本文還將介紹如何開始使用此欺詐檢測工作流構建模型和進行推理。
用于欺詐檢測的圖形神經網絡?
傳統的機器學習(ML)模型(例如 XGBoost )已廣泛應用于欺詐檢測,并已證明能夠有效識別單個交易中的異常行為。然而,欺詐檢測很少是孤立事件的問題。欺詐者在復雜的網絡中運作,通常使用帳戶和交易之間的連接來隱藏其活動。這是圖神經網絡(GNNs)發揮作用的地方。
GNN 旨在處理圖形結構化數據,因此特別適合在金融服務中進行欺詐檢測。想象一下,每個帳戶、交易和設備都是網絡中的一個節點。GNN 不只是分析單個交易,而是考慮這些節點之間的連接,從而揭示整個網絡中的可疑活動模式。
例如,假設一個帳戶與已知的欺詐實體有關系,或與其他高風險實體類似,GNNs 可以選擇該連接并標記它以進行進一步調查,即使帳戶本身看起來正常。
將 GNN 與 XGBoost 相結合,可以兼顧兩者的優勢:
- 更高的準確性 :GNN 不僅專注于單個事務,還會考慮如何連接一切,從而捕獲原本可能無法被檢測到的欺詐行為。
- 誤報率更低 :隨著上下文的增加,GNNs 有助于減少誤報,因此合法交易不會被不必要地標記出來。
- 更高的可擴展性 :GNN 模型構建可擴展處理大量網絡數據。將 GNN 與 XGBoost 實時欺詐檢測 (推理) 結合,即使在大規模情況下也是可行的。
- 可解釋性 :將 GNN 與 XGBoost 相結合可提供深度學習的強大功能以及決策樹的可解釋性。
使用 GNN 的端到端欺詐檢測 AI 工作流
NVIDIA 構建了一個端到端的欺詐檢測工作流程,將傳統的機器學習與圖神經網絡(GNN)的強大功能相結合。該流程基于標準的 XGBoost 方法,但通過 GNN 嵌入對其進行增強,以顯著提高準確性。雖然確切的數字是保密的,但即使是微小的改進(例如 1%)也可以節省數百萬美元,從而使 GNN 成為欺詐檢測系統的重要組成部分。
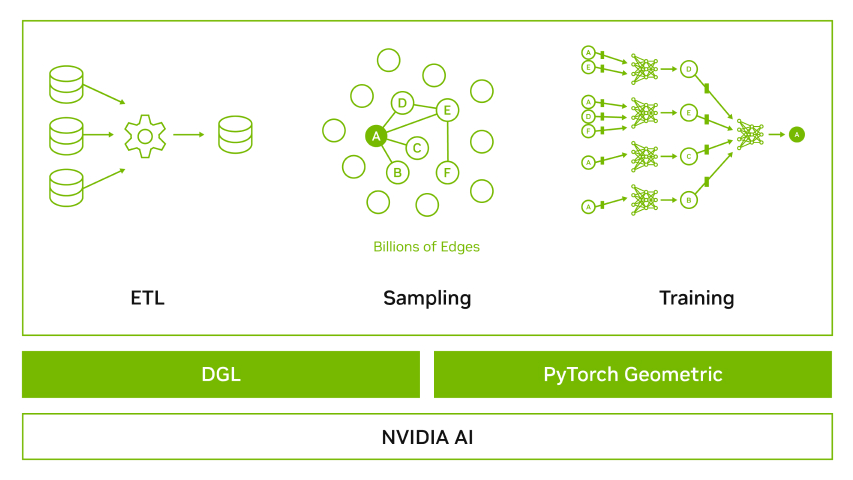
一般架構包括兩個主要部分:模型構建步驟和推理過程,如圖 1 所示。

使用 GNN 和 XGBoost 構建模型?
該流程從模型構建階段開始 ,因為模型需要在上述工作流中 用于推理 ,其中 GNN 用于創建輸入到 XGBoost 模型的特征(嵌入)(圖 2)。

第 1 步:數據準備
我們通常使用 RAPIDS 等工具來清理和準備傳入的交易數據,以提高效率。數據準備和特征工程對模型構建的性能有重大影響。此步驟需要詳細了解數據,并且可能需要多次嘗試才能獲得最佳結果。
創建數據準備腳本后,即可在工作流中實現自動化。應在添加新數據時評估數據準備過程,或隨著數據的增長定期評估數據準備過程。此工作流的下一次迭代將利用 NVIDIA RAPIDS Accelerator for Apache Spark 來加速此工作流中的數據處理部分。
第 2 步:圖形創建
對于 FSI 中常見的大型數據集,圖形創建過程會將準備好的數據轉換為 Feature Store (表格數據)和 Graph Store (結構數據)。這可以更好地使用主機和設備內存并實現峰值性能。這兩個存儲針對 PyG (PyTorch Geometric)和 DGL (Deep Graph Library)等 GNN 框架進行了優化。使用此工作流的主要好處是確保針對選定的 GNN 框架優化存儲。
# load the edge dataedge_data = cudf.read_csv(edge_path, header=None, names=[edge_src_col, edge_dst_col, edge_att_col], dtype=['int32','int32','float'])# convert to tensorsnum_nodes = max(edge_data[edge_src_col].max(), edge_data[ edge_dst_col].max()) + 1src_tensor = torch.as_tensor(edge_data[edge_src_col], device='cuda')dst_tensor = torch.as_tensor(edge_data[edge_dst_col], device='cuda')# save in a GraphStoregraph_store = cugraph_pyg.data.GraphStore()graph_store[("n", "e", "n"), "coo", False, (num_nodes, num_nodes)] = [src_tensor, dst_tensor]...# load the featuresfeature_data = cudf.read_csv(feature_path)# convert to tensorscol_tensors = []for c in feature_columns: t = torch.as_tensor(feature_data.values, device='cuda') col_tensors.append(t)x_feature_tensor = torch.stack(col_tensors).Tfeature_store = cugraph_pyg.data.TensorDictFeatureStore()feature_store["node", "x"] = x_feature_tensorfeature_store["node", "y"] = y_label_tensor |
第 3 步:生成 GNN 嵌入
我們不會讓 GNN 生成分類,而是將 GNN 的最后一層提取為嵌入。這些 GNN 嵌入將傳遞給 XGBoost 并創建模型,然后該模型將被保存以供推理使用。
def extract_embeddings(model, loader): model.eval() embeddings = [] labels = [] with torch.no_grad(): for batch in loader: batch_size = batch.batch_size hidden = model(batch.x[:,:].to(torch.float32), batch.edge_index, return_hidden=True)[:batch_size] embeddings.append(hidden) # Keep embeddings on GPU labels.append(batch.y[:batch_size].view(-1).to(torch.long)) embeddings = torch.cat(embeddings, dim=0) # Concatenate embeddings on GPU labels = torch.cat(labels, dim=0) # Concatenate labels on GPU return embeddings, labels... in main code ....# Define the modelmodel = GraphSAGE( ....)for epoch in range(best_params['num_epochs']): train_loss = train_gnn(model, train_loader, optimizer, criterion)...# Extract embeddings from the second-to-last layer and keep them on GPUembeddings, labels = extract_embeddings(model, train_loader) |
通過使用 GPU 加速版本的 GNN 框架(例如 cuGraph-pyg 和 cuGraph-dgl),此工作流可以高效處理具有復雜圖形結構的大型數據集。
用于實時欺詐檢測的推理?
模型經過訓練后,可以使用 NVIDIA Triton 推理服務器對其進行實時欺詐檢測。NVIDIA Triton 是一個開源的 AI 模型服務平臺,可簡化和加速 AI 推理工作負載在生產環境中的部署。NVIDIA Triton 幫助企業降低模型服務基礎設施的復雜性,縮短在生產環境中部署新 AI 模型所需的時間,并提高 AI 推理和預測能力。
經過訓練的模型還可以使用 NVIDIA Morpheus 進行部署。NVIDIA Morpheus 是一個開源網絡安全 AI 框架,使開發者能夠創建優化的應用程序,用于對大量流數據進行過濾、處理和分類。編排此工作流的 Morpheus Runtime Core(MRC) 可加速大規模數據處理和分析,并通過定期觸發構建新模型的過程來幫助推理。
如圖 3 所示,推理過程涉及:
- 使用模型構建(即訓練)期間使用的相同流程轉換原始輸入數據。
- 將數據饋送至 GNN 模型,以將事務轉換為嵌入。由于 XGBoost 模型是在嵌入上訓練的,因此需要執行此操作。
- 將嵌入輸入 XGBoost 模型,以預測交易是否欺詐。

# Load GNN model for creating node embeddingsgnn_model = torch.load(gnn_model_path)gnn_model.eval() # Set the model to evaluation mode# Load xgboost model for node classificationloaded_bst = xgb.Booster()loaded_bst.load_model(xgb_model_path)# Generate node embedding using the GNN modeltransaction_embeddings = gnn_model(X.to(device), ....)# Convert embeddings to cuDF DataFrameembeddings_cudf = cudf.DataFrame(cp.from_dlpack(to_dlpack(embeddings)))# Create DMatrix for the test embeddingsdtest = xgb.DMatrix(embeddings_cudf)# Predict using XGBoost on GPUpreds = bst.predict(dtest) |
通過結合 GNN 和 XGBoost,此 AI 工作流可為欺詐檢測提供靈活、高性能的解決方案。企業可以自定義 GNN 的配置,并根據其獨特需求調整模型構建流程,從而確保系統隨著時間的推移保持優化。
使用 AI 工作流增強欺詐檢測的生態系統,例如使用 PyTorch、pandas 和 LangChain 等工具來構建和部署 AI 模型。Megatron 和 NVIDIA 的 cuOpt 等技術可以用于優化 AI 算法,而 Stable Diffusion 和 Llama 等模型可以用于檢測欺詐行為。同時,Jetson 和 Google 的 Python 庫等工具可以用于部署和集成 AI 模型。Hugging Face 的 Transformers 庫和 Arm 的 DPU 等技術可以用于優化 AI 模型的性能。Anaconda 的 Python 發行版和 Siemens 的 SIMATIC 等產品可以用于部署和集成 AI 模型。GPU 等硬件設備可以用于加速 AI 計算。例如,Llama 3.1-70B-Instruct 和 Falcon 180B 等模型可以用于檢測欺詐行為,Llama-3.1-405b-instruct 等模型可以用于構建和部署 AI 應用程序。
Amazon Web Services (AWS) 是第一家將 這種端到端欺詐檢測工作流 與其高度安全的加速計算功能集成的云服務提供商。通過這種簡單的工作流集成,構建欺詐檢測模型的開發者可以在 Amazon EMR 中使用 NVIDIA RAPIDS 進行數據處理,并利用 Amazon SageMaker 和 Amazon EC2 服務中的 RAPIDS 和 GNN 庫進行模型訓練。這種集成可以通過 Amazon SageMaker 或 Amazon Elastic Kubernetes Service 端點,使用 NVIDIA Morpheus 和 NVIDIA Triton Inference Server 靈活擴展低延遲和高吞吐量的預測。
隨著這些努力的不斷發展,此工作流將在整個 NVIDIA 合作伙伴生態系統中提供,供企業和開發者通過 NVIDIA AI Enterprise 進行原型設計并投入生產。
開始使用?
隨著欺詐策略的發展,傳統的檢測方法不足以滿足需求。將 XGBoost 與 GNN 相結合可提供強大的解決方案,從而提高準確性、減少誤報率并改進實時檢測。這一 AI 工作流 旨在幫助企業在復雜的欺詐企圖面前保持領先,并快速適應新的威脅。
如需詳細了解如何使用 GNN 轉變欺詐檢測方法,請查看 AI 信用卡欺詐工作流程 。您還可以探索 NVIDIA LaunchPad 實驗室 Deploy a Fraud Detection XGBoost Model with NVIDIA Triton 以及 AI for Fraud Detection Use Case 。
?