
在生成式 AI 的動態領域,擴散模型脫穎而出,成為使用文本提示生成高質量圖像的功能強大的架構 .Stable Diffusion 等模型徹底改變了創意應用。
但是,由于需要執行迭代降噪步驟,擴散模型的推理過程非常計算密集。這對致力于實現最佳端到端推理速度的公司和開發者帶來了嚴峻挑戰。
首先,NVIDIA TensorRT 9.2.0 引入了一款出色的量化工具包,支持FP8 或 INT8 預訓練量化 (PTQ),顯著提升了在 NVIDIA 硬件上部署擴散模型的速度,同時保持圖像質量。TensorRT 的 8 位量化功能已成為眾多生成式 AI 公司的首選解決方案,特別是對于領先的創意視頻編輯應用程序提供商。
在本文中,我們討論了 TensorRT 與 Stable Diffusion XL 的性能。我們介紹了支持 TensorRT 成為低延遲 Stable Diffusion 推理首選的技術差異。最后,我們展示了如何使用 TensorRT 通過幾行代碼加速模型。
基準測試
NVIDIA TensorRT INT8 和 FP8 量化方法適用于擴散模型,在 NVIDIA RTX 6000 Ada GPU 上的速度比原生 PyTorch 快 1.72 倍和 1.95 倍torch.compile在 FP16 中運行 .FP8 的額外加速主要歸因于多頭注意力 (MHA) 層的量化。使用 TensorRT 8 位量化,您可以增強生成式 AI 應用程序的響應速度并降低推理成本。
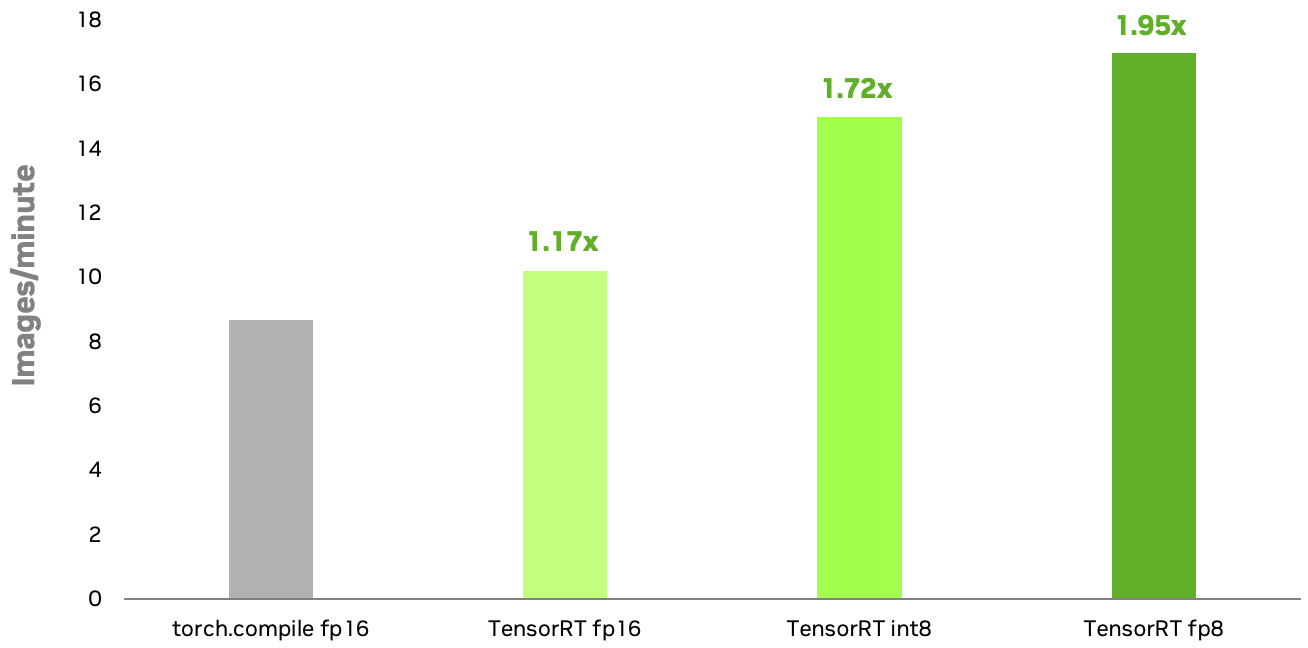
配置:Stable Diffusion XL 1.0 基礎模型;圖像分辨率=1024×1024;批量大小=1;Euler 調度程序適用于 50 個步驟; NVIDIA RTX 6000 Ada GPU.TensorRT INT8 量化現已推出,預計很快推出 FP8.基準測試可能會在發布時發生變化。
除了加快推理速度外,TensorRT 8 位量化還擅長保留圖像質量。通過專有量化技術,它可以生成與原始 FP16 圖像非常相似的圖像。我們將在本文中后續部分介紹這些技術。

TensorRT 解決方案:克服推理速度挑戰
雖然 PTQ 被認為是降低內存占用和加快 AI 任務推理速度的首選壓縮方法,但它在擴散模型上不起作用。擴散模型具有獨特的多時間步驟降噪過程,并且在每個時間步驟的噪聲估計網絡的輸出分布可能會發生顯著變化。這使得直觀的 PTQ 校正方法無法使用。
在現有的技術中,SmoothQuant 是一種流行的 PTQ 方法,它為 LLM 實現了 8 位權重和 8 位激活(W8A8)量化。它的主要創新之處在于通過將量化挑戰從激活轉移到權重,并通過數學等效變換來解決激活異常問題。
盡管它很有效,但用戶經常遇到在 SmoothQuant 中手動定義參數的困難。實踐研究還發現,SmoothQuant 很難適應各種圖像特征,從而限制了其在真實場景中的靈活性和性能。此外,其他現有的擴散模型量化技術僅適用于單個擴散模型的一個版本,而用戶正在尋找一種通用方法,以加快各種模型版本的速度。
為了應對這些挑戰, NVIDIA TensorRT 開發了一個精細的細粒度調整管線,以便為 SmoothQuant 確定每個模型層的最佳參數設置。您可以根據特定的特征圖塊開發自己的調整管線。此功能使 TensorRT 量化能夠實現比現有方法更出色的圖像質量,從而保留原始圖像的豐富細節。
激活分布可能會在不同時間步長之間發生顯著變化,而圖像的形狀和整體風格主要在降噪過程的初始階段決定。因此,使用傳統的最大校正會在初始步驟中產生大量量化錯誤。參見 Q-Diffusion 白皮書了解更多詳情。
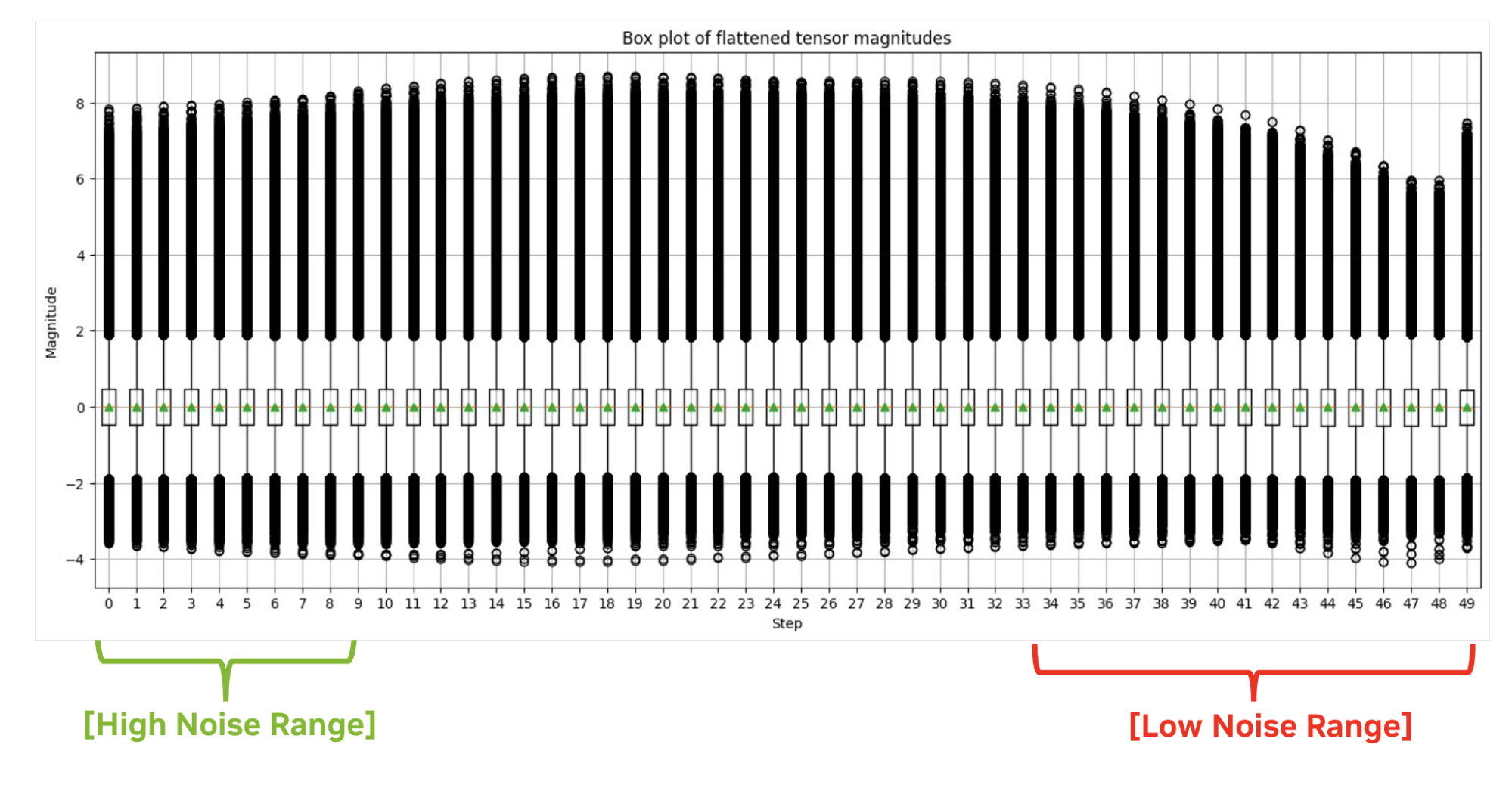
相反,我們選擇性地使用選定步長范圍中的最小量化擴展因子,因為我們發現激活值中的異常點對最終圖像質量的影響并不大。這種定制方法我們稱之為百分位數量重點關注步驟范圍的重要百分比。它使 TensorRT 能夠生成幾乎與原始 FP16 精度相同的圖像。

使用 TensorRT 8 位量化來加速擴散模型
這個 /NVIDIA/TensorRT?GitHub repo 現在托管一個端到端、SDXL、8 位推理管道,提供一個現成的解決方案,在 NVIDIA GPU 上實現優化的推理速度。
運行一個命令,使用 Percentile Quant 生成圖像,并使用 demoDiffusion 測量延遲。在本節中,我們使用 INT8 作為示例,但 FP8 的工作流程大致相同。
python demo_txt2img_xl.py "enchanted winter forest with soft diffuse light on a snow-filled day" --version xl-1.0 --onnx-dir onnx-sdxl --engine-dir engine-sdxl --int8 --quantization-level 3 |
以下是此命令的主要步驟概述:
- 校正
- 導出 ONNX
- 構建 TensorRT 引擎
校正
校正是量化過程中計算目標精度范圍的步驟。目前,TensorRT 中的量化功能包含 nvidia-ammo,這是 TensorRT 8 位量化示例中包含的依賴項。
# Load the SDXL-1.0 base model from HuggingFaceimport torchfrom diffusers import DiffusionPipelinebase = DiffusionPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True)base.to("cuda")# Load calibration prompts:from utils import load_calib_promptscali_prompts = load_calib_prompts(batch_size=2,prompts="./calib_prompts.txt")# Create the int8 quantization recipefrom utils import get_percentilequant_configquant_config = get_percentilequant_config(base.unet, quant_level=3.0, percentile=1.0, alpha=0.8)# Apply the quantization recipe and run calibration import ammo.torch.quantization as atq quantized_model = atq.quantize(base.unet, quant_config, forward_loop)# Save the quantized modelimport ammo.torch.opt as atoato.save(quantized_model, 'base.unet.int8.pt') |
導出 ONNX
獲取量化模型檢查點后,您可以導出 ONNX 模型。
# Prepare the onnx export from utils import filter_func, quantize_lvlbase.unet = ato.restore(base.unet, 'base.unet.int8.pt')quantize_lvl(base.unet, quant_level=3.0)atq.disable_quantizer(base.unet, filter_func) # `filter_func` is used to exclude layers you don't quantize # Export the ONNX modelfrom onnx_utils import ammo_export_sdbase.unet.to(torch.float32).to("cpu")ammo_export_sd(base, 'onnx_dir', 'stabilityai/stable-diffusion-xl-base-1.0') |
構建 TensorRT 引擎
利用 INT8 UNet ONNX 模型,您可以 創建 TensorRT 引擎。
trtexec --onnx=./onnx_dir/unet.onnx --shapes=sample:2x4x128x128,timestep:1,encoder_hidden_states:2x77x2048,text_embeds:2x1280,time_ids:2x6 --fp16 --int8 --builderOptimizationLevel=4 --saveEngine=unetxl.trt.plan |
總結
在生成式 AI 時代,擁有優先考慮易用性的推理解決方案至關重要。借助 NVIDIA TensorRT,您可以通過其專有的 8 位量化技術實現高達 2 倍的推理速度提升,同時確保圖像質量不受影響,從而提供出色的用戶體驗。
TensorRT 致力于平衡速度和質量,凸顯其在加速 AI 應用方面的領先地位,讓您輕松提供尖端解決方案。
注冊參加 關于量化的 GTC 會議,以了解更多關于優化生成式 AI 模型推理速度和模型壓縮的信息。如果您正在使用基于 LLM 的應用程序,我們鼓勵您探索 如何利用 TensorRT-LLM 及其先進的量化技術加速推理過程。
有關更多信息,請參閱以下資源:
- NVIDIA GTC 2024 上的熱門會議:LLM 推理
- NVIDIA TensorRT-LLM 加速 Google Gemma 的推理
- TensorRT SDK
- /NVIDIA/TensorRT-LLM GitHub 資源庫
?






