假設你剛剛開始一個新的數據科學項目。目標是建立一個預測目標變量 Y 的模型。您已經從利益相關者/數據工程師那里收到了一些數據,進行了徹底的 EDA ,并選擇了一些您認為與當前問題相關的變量。然后你終于建立了你的第一個模型。分數可以接受,但你相信你可以做得更好。你是做什么的?
有很多方法可以讓你跟進。一種可能是增加所用 machine-learning 模型的復雜性。或者,您可以嘗試提出一些更有意義的功能,并繼續使用當前的模型(至少目前是這樣)。
對于許多項目,企業數據科學家和 Kaggle 等數據科學競賽的參與者都同意,后者——從數據中識別出更有意義的特征——往往能夠以最少的努力最大程度地提高模型的準確性。
你有效地將復雜性從模型轉移到了功能上。這些功能不一定非常復雜。但是,理想情況下,我們會發現與目標變量有著強烈而簡單的關系的特征。
許多數據科學項目包含一些關于時間流逝的信息。這并不局限于時間序列預測問題。例如,您通常可以在傳統的回歸或分類任務中找到此類特征。本文研究如何使用日期相關信息創建有意義的特征。我們介紹了三種方法,但首先需要做一些準備。
設置和數據
在本文中,我們主要使用非常知名的 Python 軟件包,并依賴于一個相對未知的scikit-lego,這是一個庫,其中包含許多擴展scikit-learn’s功能的有用功能。我們按如下方式導入所需的庫:
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from datetime import date from sklearn.linear_model import LinearRegression from sklearn.preprocessing import FunctionTransformer from sklearn.metrics import mean_absolute_error from sklego.preprocessing import RepeatingBasisFunction
為了保持簡單,我們自己生成數據。在本例中,我們使用一個人工時間序列。我們首先創建一個空數據框,索引跨越四個日歷年(我們使用pd.date_range)。然后,我們創建兩列:
day_nr——表示時間流逝的數字索引day_of_year——一年中的第幾天
最后,我們必須創建時間序列本身。為此,我們將兩條經過變換的正弦曲線和一些隨機噪聲結合起來。用于生成數據的代碼基于scikit-lego’s documentation 中包含的代碼。
# for reproducibility np.random.seed(42) # generate the DataFrame with dates range_of_dates = pd.date_range(start="2017-01-01", End="2020-12-30") X = pd.DataFrame(index=range_of_dates) # create a sequence of day numbers X["day_nr"] = range(len(X)) X["day_of_year"] = X.index.day_of_year # generate the components of the target signal_1 = 3 + 4 * np.sin(X["day_nr"] / 365 * 2 * np.pi) signal_2 = 3 * np.sin(X["day_nr"] / 365 * 4 * np.pi + 365/2) noise = np.random.normal(0, 0.85, len(X)) # combine them to get the target series y = signal_1 + signal_2 + noise # plot y.plot(figsize=(16,4), title="Generated time series");
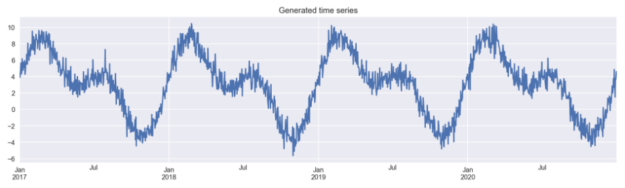
然后,我們創建一個新的數據幀,在其中存儲生成的時間序列。該數據框架將用于使用不同的特征工程方法比較模型的性能。
results_df = y.to_frame() results_df.columns = ["actuals"]
創建與時間相關的功能
在本節中,我們將介紹三種生成時間相關特征的方法。
在深入研究之前,我們應該定義一個評估框架。我們的模擬數據包含四年的觀察結果。我們將使用前三年生成的數據作為培訓集,并在第四年進行評估。我們將使用平均絕對誤差( MAE )作為評估指標。
下面我們定義了一個變量,用于切斷這兩個集合:
TRAIN_END = 3 * 365
方法# 1 :虛擬變量
我們從你最可能已經熟悉的東西開始,至少在某種程度上。編碼時間相關信息的最簡單方法是使用 dummy variables (也稱為單熱編碼)。讓我們看一個例子。
X_1 = pd.DataFrame( data=pd.get_dummies(X.index.month, drop_first=True, prefix="month") ) X_1.index = X.index X_1
下面,您可以看到我們操作的輸出。
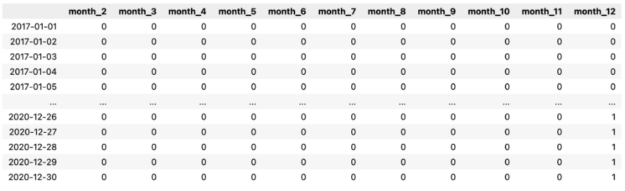
首先,我們從DatetimeIndex中提取關于月份的信息(編碼為 1 到 12 的整數)。然后,我們使用pd.get_dummies函數創建虛擬變量。每列都包含有關觀察(行)是否來自給定月份的信息。
正如你可能已經注意到的,我們已經降低了一個級別,現在只有 11 列。我們這樣做是為了避免臭名昭著的 虛擬變量陷阱 (完美多重共線性),這在使用線性模型時可能會成為一個問題。
在我們的示例中,我們使用虛擬變量方法來捕獲記錄觀察的月份。然而,同樣的方法也可用于指示DatetimeIndex中的一系列其他信息。例如,一年中的天/周/季度、某一天是否為周末的標志、某一時段的第一天/最后一天,等等。您可以在 pandas.pydata.org 上找到一個列表,其中包含我們可以從pandas文檔索引中提取的所有可能功能。
Bonus tip :這超出了這個簡單練習的范圍,但在現實生活場景中,我們還可以使用有關特殊日子的信息(比如國定假日、圣誕節、黑色星期五等)來創建功能。holidays是一個不錯的 Python 庫,包含每個國家過去和未來的特殊日子信息。
如引言所述,特征工程的目標是將復雜性從模型側轉移到特征側。這就是為什么我們將使用一個最簡單的 ML 模型——線性回歸——來觀察我們僅使用創建的模型就能很好地擬合時間序列。
model_1 = LinearRegression().fit(X_1.iloc[:TRAIN_END], y.iloc[:TRAIN_END]) results_df["model_1"] = model_1.predict(X_1) results_df[["actuals", "model_1"]].plot(figsize=(16,4), title="Fit using month dummies") plt.axvline(date(2020, 1, 1), c="m", linestyle="--");
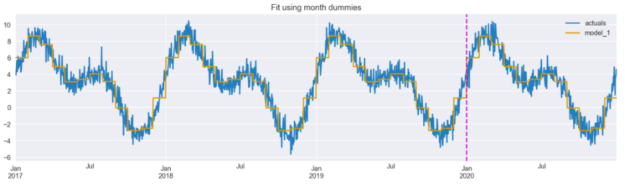
我們可以看到,擬合線已經很好地遵循了時間序列,盡管它有點鋸齒狀(階梯狀)——這是由虛擬特征的不連續性造成的。這就是我們將嘗試用下兩種方法解決的問題。
但在繼續之前,可能值得一提的是,當使用決策樹(或其集合)等非線性模型時,我們不會明確地將月數或一年中的某一天等特征編碼為假人。這些模型能夠學習有序輸入特征和目標之間的非單調關系。
方法 2 :正弦/余弦變換循環編碼
如前所述,擬合線類似于臺階。這是因為每個假人都是單獨處理的,沒有連續性。然而,時間等變量存在明顯的周期性連續性。這是什么意思?
想象一下,我們正在處理能源消耗數據。當我們將觀察到的消費月份的信息包括在內時,連續兩個月之間的聯系就更緊密了。按照這種邏輯, 12 月和 1 月之間以及 1 月和 2 月之間的聯系非常緊密。相比之下, 1 月和 7 月之間的聯系并沒有那么緊密。這同樣適用于其他與時間相關的信息。
那么,我們如何將這些知識整合到特征工程中呢?三角函數起到了解救的作用。我們可以使用以下正弦/余弦變換將周期時間特征編碼為兩個特征。
def sin_transformer(period): return FunctionTransformer(lambda x: np.sin(x / period * 2 * np.pi)) def cos_transformer(period): return FunctionTransformer(lambda x: np.cos(x / period * 2 * np.pi))
在下面的代碼片段中,我們復制初始數據幀,添加帶有月號的列,然后使用正弦/余弦變換對month和day_of_year列進行編碼。然后,我們繪制兩對曲線。
X_2 = X.copy()
X_2["month"] = X_2.index.month X_2["month_sin"] = sin_transformer(12).fit_transform(X_2)["month"]
X_2["month_cos"] = cos_transformer(12).fit_transform(X_2)["month"] X_2["day_sin"] = sin_transformer(365).fit_transform(X_2)["day_of_year"]
X_2["day_cos"] = cos_transformer(365).fit_transform(X_2)["day_of_year"] fig, ax = plt.subplots(2, 1, sharex=True, figsize=(16,8))
X_2[["month_sin", "month_cos"]].plot(ax=ax[0])
X_2[["day_sin", "day_cos"]].plot(ax=ax[1])
plt.suptitle("Cyclical encoding with sine/cosine transformation");
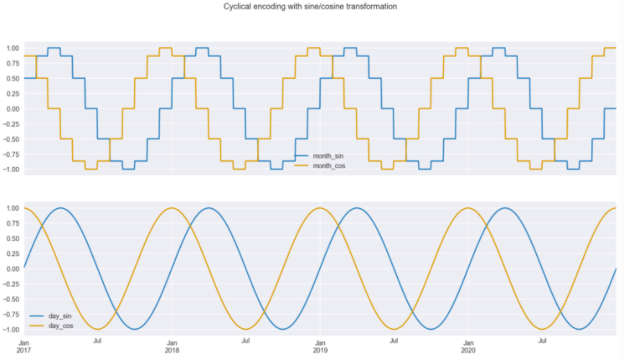
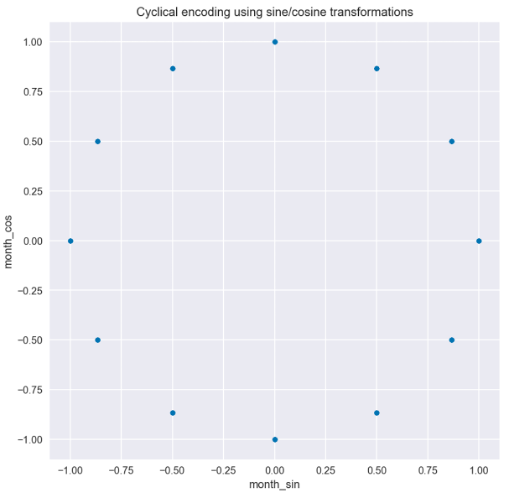
我們可以從轉換后的數據中得出兩個見解,如圖 3 所示。首先,我們可以很容易地看到,當使用月份進行編碼時,曲線是逐步的,但當使用日頻率時,曲線要平滑得多;其次,我們也可以看到為什么我們必須使用兩條曲線而不是一條。由于曲線的重復性,如果你在一年內畫一條直線穿過地塊,你會在兩個地方穿過曲線。這還不足以讓模型理解觀測的時間點。但有了這兩條曲線,就不存在這樣的問題,用戶可以識別每個時間點。當我們在散點圖上繪制正弦/余弦函數的值時,這是顯而易見的。在圖 4 中,我們可以看到沒有重疊值的圓形圖案。
讓我們只使用來自每日頻率的新創建的特征來擬合相同的線性回歸模型。
X_2_daily = X_2[["day_sin", "day_cos"]] model_2 = LinearRegression().fit(X_2_daily.iloc[:TRAIN_END], y.iloc[:TRAIN_END]) results_df["model_2"] = model_2.predict(X_2_daily) results_df[["actuals", "model_2"]].plot(figsize=(16,4), title="Fit using sine/cosine features") plt.axvline(date(2020, 1, 1), c="m", linestyle="--");
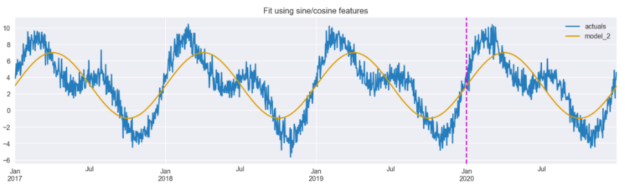
圖 5 顯示,該模型能夠提取數據的總體趨勢,識別具有較高和較低值的時段。然而,預測的大小似乎不太準確,乍一看,這種擬合似乎比使用虛擬變量實現的擬合更差(圖 2 )。
在討論第三種特征工程技術之前,值得一提的是,這種方法有一個嚴重的缺點,這在使用基于樹的模型時是顯而易見的。根據設計,基于樹的模型在同一時間基于單個特征進行分割。正如我們之前所提到的,正弦/余弦特征應該同時考慮,以便正確識別一段時間內的時間點。
方法# 3 :徑向基函數
最后一種方法使用徑向基函數。我們不會詳細介紹它們的實際情況,但您可以閱讀更多關于 here 主題的內容。本質上,我們再次希望解決我們在第一種方法中遇到的問題,即我們的時間特征具有連續性。
我們使用方便的scikit-lego庫,它提供RepeatingBasisFunction類,并指定以下參數:
- 我們想要創建的基函數的數量(我們選擇了 12 個)。
- 使用哪一列為 RBF 編制索引。在我們的例子中,這是一個列,包含給定觀測值來自一年中哪一天的信息。
- 輸入的范圍——在我們的例子中,范圍是從 1 到 365 。
- 如何處理我們將用于擬合估計器的數據幀的剩余列。
”drop”將只保留創建的 RBF 功能,”passthrough”將保留舊功能和新功能。
rbf = RepeatingBasisFunction(n_periods=12, column="day_of_year", input_range=(1,365), remainder="drop") rbf.fit(X) X_3 = pd.DataFrame(index=X.index, data=rbf.transform(X)) X_3.plot(subplots=True, figsize=(14, 8), sharex=True, title="Radial Basis Functions", legend=False);
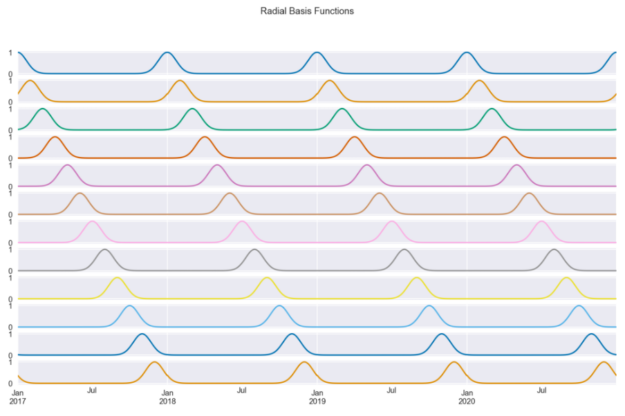
圖 6 顯示了我們使用天數作為輸入創建的 12 個徑向基函數。每一條曲線都包含關于我們離一年中某一天有多近的信息(因為我們選擇了該列)。例如,第一條曲線測量的是從 1 月 1 日開始的距離,因此它在每年的第一天達到峰值,并在我們離開該日期時對稱地減小。
通過設計,基函數在輸入范圍內是等間距的。我們選擇了 12 個,因為我們想讓 RBF 看起來像幾個月。通過這種方式,每個函數大致顯示(由于月份長度不相等)到月份第一天的距離。
與前面的方法類似,讓我們使用 12 個 RBF 特征擬合線性回歸模型。
model_3 = LinearRegression().fit(X_3.iloc[:TRAIN_END], y.iloc[:TRAIN_END]) results_df["model_3"] = model_3.predict(X_3) results_df[["actuals", "model_3"]].plot(figsize=(16,4), title="Fit using RBF features") plt.axvline(date(2020, 1, 1), c="m", linestyle="--");
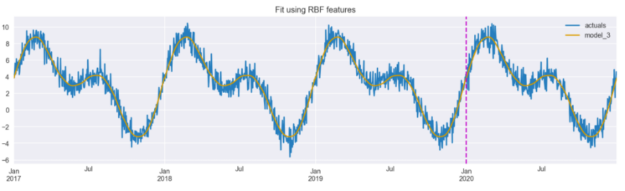
圖 7 顯示,當使用 RBF 特征時,該模型能夠準確捕獲真實數據。
使用徑向基函數時,我們可以調整兩個關鍵參數:
- 徑向基函數的個數,
- 鐘形曲線的形狀–可以使用
RepeatingBasisFunction的width參數進行修改。
調整這些參數值的一種方法是使用網格搜索來確定給定數據集的最佳值。
最后的比較
我們可以執行以下代碼片段,對編碼時間相關信息的不同方法進行數值比較。
results_df.plot(title="Comparison of fits using different time-based features", figsize=(16,4), color = ["c", "k", "b", "r"]) plt.axvline(date(2020, 1, 1), c="m", linestyle="--");
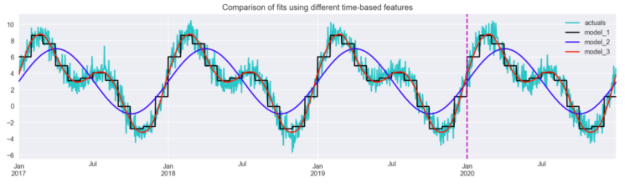
圖 8 說明了徑向基函數與所考慮的方法最接近。正弦/余弦特征允許模型拾取主要模式,但不足以完全捕捉序列的動態。
使用下面的代碼片段,我們計算每個模型在訓練集和測試集上的平均絕對誤差。我們預計訓練集和測試集之間的分數非常相似,因為生成的序列幾乎完全是周期性的——年份之間的唯一區別是隨機成分。
當然,在現實生活中情況并非如此,在現實生活中,隨著時間的推移,我們在同一時期會遇到更多的變化。然而,在這種情況下,我們還將使用許多其他特征(例如,某種趨勢或時間推移的度量)來解釋這些變化。
score_list = []
for fit_col in ["model_1", "model_2", "model_3"]: scores = { "model": fit_col, "train_score": mean_absolute_error( results_df.iloc[:TRAIN_END]["actuals"], results_df.iloc[:TRAIN_END][fit_col] ), "test_score": mean_absolute_error( results_df.iloc[TRAIN_END:]["actuals"], results_df.iloc[TRAIN_END:][fit_col] ) } score_list.append(scores) scores_df = pd.DataFrame(score_list)
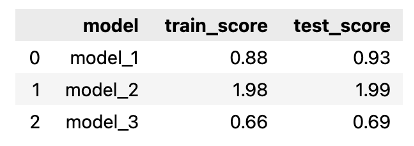
scores_df
與之前一樣,我們可以看到使用 RBF 特征的模型得到了最佳擬合,而正弦/余弦特征表現最差。我們關于訓練集和測試集之間分數相似性的假設也得到了證實。
外賣
- 我們展示了三種將時間相關信息編碼為機器學習模型特征的方法。
- 除了最流行的虛擬編碼外,還有一些方法更適合對時間的周期性進行編碼。
- 使用這些方法時,時間間隔的粒度對新創建的特征的形狀非常重要。
- 使用徑向基函數,我們可以決定要使用的函數的數量,以及鐘形曲線的寬度。
您可以在我的 GitHub 上找到本文使用的代碼。如果您有任何反饋,我很樂意在 Twitter 上討論。
工具書類
- https://scikit-learn.org/stable/auto_examples/applications/plot_cyclical_feature_engineering.html
- https://scikit-lego.readthedocs.io/en/latest/preprocessing.html
- https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#time-date-components
?