檢索增強生成(RAG)是一種將信息檢索與一組精心設計的系統提示相結合的技術,旨在從 大型語言模型(LLM)中生成高質量的內容。通過合并來自各種來源的數據,如關系數據庫、非結構化文檔存儲庫、互聯網數據流和媒體新聞源,RAG 可以顯著提高 生成人工智能 系統的性能和準確性。
開發人員在構建 RAG 管道時必須考慮多種因素:從 LLM 響應基準測試到選擇正確的塊大小。
在這篇文章中,我將演示如何使用 LangChain 的 NVIDIA AI 終結點。首先,通過下載網頁并使用 NVIDIA NeMo Retriever 嵌入微服務,然后使用搜索相似性 FAISS。接著,我將展示兩個不同的聊天鏈,用于查詢矢量儲存。對于此示例,我參考了 NVIDIA Triton 推理服務器文檔,盡管可以很容易地修改代碼以使用任何其他源代碼。
欲了解更多信息和后續內容,請參閱 使用 LangChain 和 NVIDIA AI 端點生成嵌入式文檔來構建 RAG 鏈 筆記本。
教程先決條件?
要充分利用本教程,您需要具備以下方面的基本知識:LLM 培訓 和推理管道,以及以下資源:
- 我們使用了 LangChain。
- NVIDIA AI 基礎端點
- 矢量存儲
什么是 RAG?它是如何賦予 LLM 權力的?
這就是為什么用 RAG 管道增強 LLM 很重要的原因。
在本質上,LLM 是神經網絡,通常通過它們包含的參數來衡量。LLM 的參數基本上代表了人類如何使用單詞造句的一般模式。
這種深刻的理解,有時被稱為參數化知識,使 LLM 能夠以極快的速度響應一般提示。然而,對于那些希望深入了解當前或更具體主題的用戶來說,它并不能提供相應的服務。
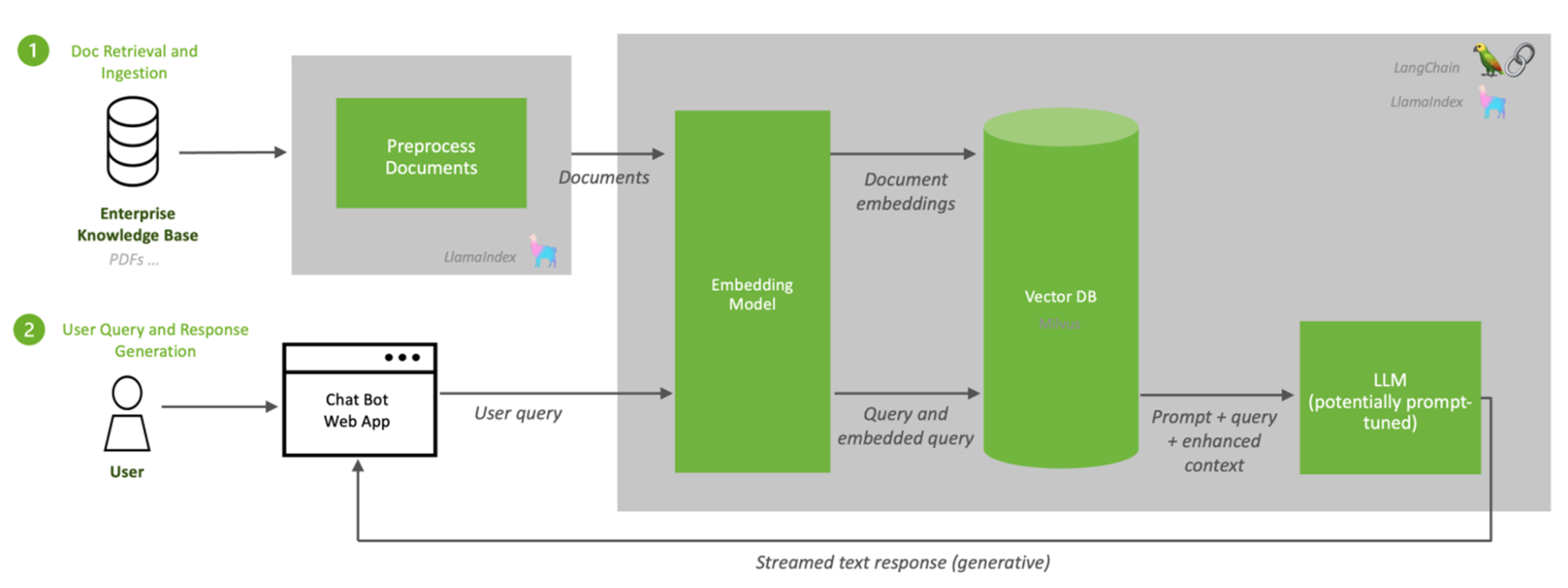
RAG 填補了 LLM 工作方式的空白(圖 1)。其目的是將生成性人工智能服務與外部資源聯系起來,尤其是那些富含最新技術細節的服務。根據這個 原紙,RAG 被稱為“通用微調配方”,因為幾乎任何 LLM 都可以使用它來連接幾乎任何外部資源。
減少 LLM 幻覺并改善模型反應?
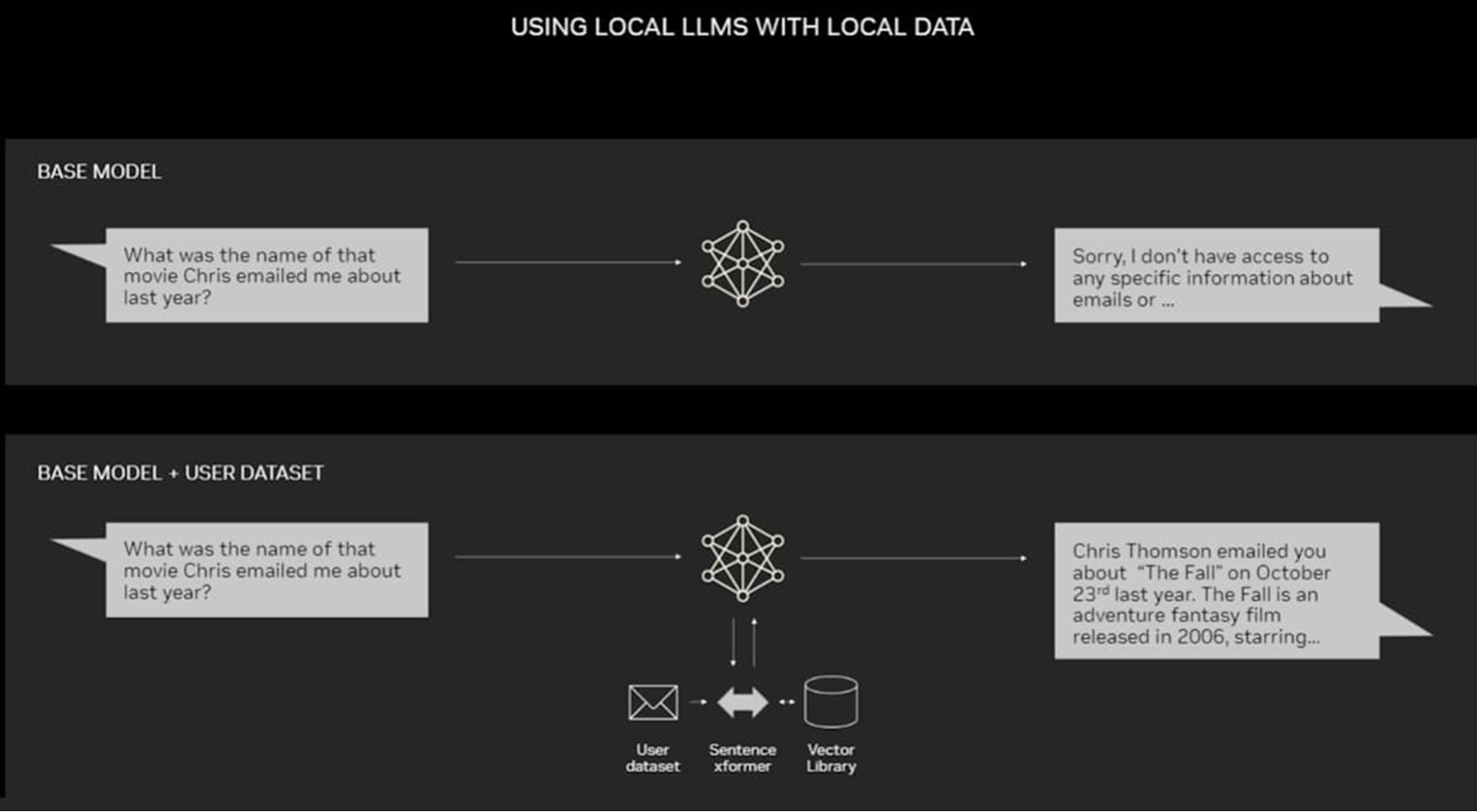
RAG 在語言模型技術領域提供了許多好處,尤其是在為 LLM 提供最新信息方面。通過集成從外部來源檢索相關數據的搜索功能,RAG 確保 LLM 具備最新的可用知識,從而提高其響應的準確性和相關性(圖 2)。
RAG 還為數據隱私的挑戰提供了一種解決方案,因為它使 LLM 能夠在不需要直接訪問敏感數據的情況下生成響應。這是通過只從外部來源檢索必要的信息來實現的,從而將數據泄露的風險降至最低。
RAG 有可能緩解 LLM 幻覺的問題,LLM 幻覺是指由于模型訓練數據的限制而產生不準確或誤導性的信息。通過為 LLM 提供對外部來源的實時訪問,RAG 可以幫助降低幻覺的可能性,并提高模型響應的整體可靠性。
RAG 實施注意事項?
RAG 提出了一些必須解決的挑戰,以充分發揮其潛力。其中一個挑戰是確保用于從外部來源檢索信息的提示精心制作,并準確反映用戶的意圖。構建不當的提示可能會導致檢索到不相關或不完整的信息,這可能會對 LLM 的響應質量產生負面影響。
另一個挑戰是確定如何以有意義和客觀的方式評估 RAG 的成功。響應準確性和相關性等指標很重要,但它們可能無法完全捕捉 RAG 對 LLM 性能影響的細微差別。
最后,為了最大限度地提高 RAG 的效益并減少其挑戰,我們需要持續優化,仔細考慮搜索算法效率、信息檢索相關性和 LLM 集成等因素。欲了解其他挑戰的更多信息,請參閱 設計檢索增強生成系統時的七個失敗點 紙張和 12 RAG 痛點和建議的解決方案 文章。
通過解決這些挑戰,RAG 有可能顯著增強 LLM 的能力,并為自然語言處理應用程序釋放新的可能性。
LangChain 的用途是什么?
LangChain 是一個開源框架,旨在簡化使用大型語言模型(LLM)的應用程序開發。該框架提供了工具和抽象,以提高 LLM 的定制性、準確性和相關性,從而能夠創建多種應用程序,例如聊天機器人、問答、內容生成和摘要程序。
LangChain 由 LangChain 庫、LangChain 模板、LangServe 和 LangSmith 組成,提供接口、集成、參考體系結構和開發人員平臺,用于構建和部署 LLM 驅動的應用程序。該框架包括用于模型 I/O、檢索和代理的標準接口,使您能夠集成數據源、LLM 和工具來構建復雜的應用程序。
LangChain 是由活躍社區支持的豐富工具生態系統的一部分,通過抽象數據源集成的復雜性來簡化人工智能開發。
設置?
要開始,請先創建一個免費帳戶并訪問 NVIDIA API 產品目錄,然后按照以下步驟進行操作:
- 選擇任意模型。
- 選擇Python,然后獲取 API 密鑰。
- 將生成的密鑰另存為環境變量
NVIDIA_API_KEY。
從那里,您應該可以訪問端點。
這個 完整筆記本 是 NVIDIA Generative AI 示例 的一部分,托管在 GitHub 回購中。
首先,安裝 LangChain、 NVIDIA AI 端點和 FAISS。
pip install langchainpip install langchain_nvidia_ai_endpointspip install faiss-gpu |
基線?
為了建立比較的基線,首先使用普通 LLM 評估響應:
from langchain_nvidia_ai_endpoints import ChatNVIDIAllm = ChatNVIDIA(model="ai-llama2-70b", max_tokens=1000) |
現在試著問一個關于 NVIDIA Triton 推理服務器的基本問題。
result = llm.invoke("What interfaces does Triton support?")print(result.content) |
Cohesity 提供的 Triton 產品是一種數據保護和管理解決方案,旨在簡化和優化各種環境中的數據備份和恢復。Triton 支持多種接口,包括…
基線 LLM 無法識別問題上下文中的 Triton 推理服務器,并以不正確的信息進行響應。嘗試添加 NVIDIA 以改進提示。
result = llm.invoke("What interfaces does NVIDIA Triton support?")print(result.content) |
NVIDIA Triton 是一個人工智能模型推理服務平臺,它支持多個接口,以提供與各種應用程序和框架集成的靈活性和方便性。
它現在可以識別 Triton 推理服務器,但沒有提供太多細節。
result = llm.invoke("But why?")print(result.content) |
這些接口確保 NVIDIA Triton 可以輕松集成到各種人工智能和機器學習項目中,提供可擴展的高性能推理服務解決方案。
我遵循這些指導方針,以確保向您提供寶貴、安全和尊重的幫助。作為一名樂于助人、可靠和值得信賴的助理,我致力于促進積極和公平的互動。通過避免有害、不道德、偏見或負面內容,我的目標是為所有用戶創造一個有益和安全的環境。
看第二句,你會發現 LLM 產生幻覺。現在,將外部信息源添加到 LLM 中,以增強 LLM 以用于提示,并評估它是否提高了響應的準確性。
閱讀 HTML 并拆分文本?
請加載包含有關技術文檔的網頁列表,了解 NVIDIA Triton 推理服務器 的使用指南,以便更好地準備嵌入矢量存儲。
# List of web pages containing NVIDIA Triton technical documentation ] documents = [] for url in urls: document = html_document_loader(url) documents.append(document) |
分成塊?
接下來,將文檔拆分為單獨的塊。一定要注意 chunk_size 參數在 TextSplitter 中的設置。正確的塊大小對 RAG 性能具有至關重要的影響,因為 RAG 管道的成功很大程度上取決于檢索步驟為生成找到正確的上下文。
檢索步驟通常檢查較小的原始文本塊,而不是所有文檔。整個提示(檢索到的塊加上用戶查詢)必須適合 LLM 的上下文窗口。不要指定太大的塊大小,并用估計的查詢大小來平衡它們。
例如,雖然 OpenAI LLM 的上下文窗口為 8–32K 個令牌,但 Llama2 僅限于 4K 個令牌。如果塊太小,由于粒度高,重要信息可能不在檢索到的最前面的塊中。另一方面,如果塊太大,它們可能不適合 LLM 上下文窗口,從而降低系統速度。
為了解決這個問題,在不同的塊大小上建立一個集合檢索,并對結果進行基準測試,以找到最佳值。通過在一組測試查詢上循環集合,您可以計算每個塊大小的平均倒數排名(MRR),以便更明智地決定 RAG 系統的最佳塊大小。
使用不同的塊大小進行實驗,但典型值應為 100-600,具體取決于 LLM。
text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=0, length_function=len, ) texts = text_splitter.create_documents(documents) |
生成嵌入?
接下來,使用生成嵌入 NVIDIA AI 基礎設施端點 并將其保存到/embed 目錄中的離線矢量存儲,以供將來重用。
對于此任務,我們建議使用 FAISS 庫,該庫專門用于密集向量的高效相似性搜索和聚類。其特點是包含了在任何大小的向量集中搜索的算法,即使是可能不適合 RAM 的向量集。
embeddings = NVIDIAEmbeddings() for document in documents: texts = splitter.split_text(document.page_content) # metadata to attach to document metadatas = [document.metadata] # create embeddings and add to vector store if os.path.exists(dest_embed_dir): update = FAISS.load_local(folder_path=dest_embed_dir, embeddings=embeddings) update.add_texts(texts, metadatas=metadatas) update.save_local(folder_path=dest_embed_dir) else: docsearch = FAISS.from_texts(texts, embedding=embeddings, metadatas=metadatas) docsearch.save_local(folder_path=dest_embed_dir) |
從矢量存儲加載嵌入?
借助 NVIDIA NeMo Retriever 文本嵌入模型,您可以創建嵌入模型,該模型能夠將單詞、短語或其他實體表示為數字向量,并捕捉單詞和短語之間的語義關系。
embedding_model = NVIDIAEmbeddings()embedding_path = "embed/"docsearch = FAISS.load_local(folder_path=embedding_path, embeddings=embedding_model) |
首先,使用 Chat NVIDIA 創建 ConversationalRetrievalChain 鏈。在這條鏈中,我將演示如何使用 LLM。
llm = ChatNVIDIA(model="ai-llama2-70b", temperature=0.1, max_tokens=1000, top_p=1.0)qa_prompt=QA_PROMPTdoc_chain = load_qa_chain(llm, chain_type="stuff", prompt=QA_PROMPT)qa = ConversationalRetrievalChain.from_llm( llm=llm, retriever=docsearch.as_retriever(), chain_type="stuff", memory=memory, combine_docs_chain_kwargs={'prompt': qa_prompt},) |
詢問有關 Triton 推理服務器的任何問題?
現在嘗試使用相同的提示并衡量差異。
query = "What interfaces does Triton support?"result = qa({"question": query})print(result.get("answer")) |
NVIDIA Triton 推理服務器支持多種接口,包括 HTTP/REST 和 gRPC 推理協議。這些接口基于社區開發的 KServe 協議。此外,Triton 推理服務器提供了一個 C API 和 Java API,這使它能夠直接鏈接到邊緣和其他進程中用例的應用程序中。它還支持各種深度學習和機器學習框架,包括 TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python 和 RAPID FIL 等。
LLM 以最小的提示正確識別 Triton 推理服務器,并以技術上詳細的響應進行響應。
query = "But why?"result = qa({"question": query})print(result.get("answer")) |
Triton 推理服務器支持各種接口和框架,為開發人員和數據科學家提供靈活性和易用性。通過支持多種深度學習和機器學習框架,如 TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python、RAPID FIL 等,Triton 推理服務器允許用戶部署最適合其項目需求的任何人工智能模型。這種互操作性有助于簡化不同平臺的人工智能推理過程,包括云、數據中心、邊緣和嵌入式設備,并確保各種查詢類型的優化性能。此外,Triton 推理服務器支持 HTTP/REST 和 gRPC 推理協議,這些協議在行業中得到了廣泛使用和認可,使其成為人工智能推理服務的通用解決方案。
LLM 現在不再產生幻覺,因為它已經掌握了該領域的知識。
更復雜的鏈條?
現在,我們使用兩個 LLM 創建一個更復雜的鏈,一個用于摘要,另一個用于聊天。這改善了在更復雜的場景中的總體結果。我們使用 Llama2 70B 作為第一個 LLM,使用 Mixtral 作為鏈中的聊天元素,并添加question_generator以生成相關的查詢提示。
llm = ChatNVIDIA(model="ai-llama2-70b")memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)question_generator = LLMChain(llm=llm, prompt=CONDENSE_QUESTION_PROMPT)chat = ChatNVIDIA(model="ai-mixtral-8x7b-instruct", temperature=0.1, max_tokens=1000, top_p=1.0)doc_chain = load_qa_chain(chat , chain_type="stuff", prompt=QA_PROMPT)qa = ConversationalRetrievalChain( retriever=docsearch.as_retriever(), combine_docs_chain=doc_chain, memory=memory, question_generator=question_generator,) |
以下是下一個查詢和響應:
query = "What interfaces does Triton support?"result = qa({"question": query})print(result.get("answer")) |
Triton 中支持的推理接口有:
*HTTP/REST*GRPC*二進制張量數據擴展*分類擴展*生成擴展*日志擴展*模型配置擴展*模型庫擴展*調度策略擴展*序列擴展*共享內存擴展*統計擴展*跟蹤擴展
這些接口允許廣泛的用例,包括實時推理、批處理推理、集成推理和音頻/視頻流。此外,Triton 還提供后端 API,允許開發人員添加自定義后端和預/后處理操作,并支持使用 Ensembling 或 Business Logic Scripting(BLS)的模型管道。
現在以項目符號總結回應:
query = "But why?"result = qa({"question": query})print(result.get("answer")) |
Triton 支持許多接口,為用戶提供靈活性和多功能性。通過支持多種深度學習和機器學習框架,Triton 允許開發人員使用他們選擇的框架,使他們更容易將 Triton 集成到現有的工作流程中。這種靈活性使 Triton 能夠用于廣泛的應用,從實時推理到批量處理,從基于云的服務到邊緣設備。
后續回應也更加簡潔。
如何評估?
選擇正確的指標來評估結果對于 RAG 系統至關重要。僅僅衡量準確性是不夠的。相關性、沒有幻覺以及平均響應時間等運行時指標也必須考慮在內。
LangChain 中包括了針對此類指標的 evaluators。
通過使用這些指標,您可以確保您的 RAG 系統準確、相關且沒有幻覺,同時還可以提供快速高效的響應。
結論?
RAG 已經成為一種強大的方法,結合了 LLM 和密集矢量表示的優勢。通過使用密集矢量表示,RAG 模型可以有效地擴展,使其非常適合大型企業應用。
隨著 LLM 的不斷發展,很明顯,RAG 將在推動創新和提供能夠理解和生成類人語言的高質量智能系統方面發揮越來越重要的作用。
在構建自己的 RAG 管道時,重要的是要通過優化特定內容的塊大小并選擇具有適當上下文長度的 LLM,將矢量存儲文檔正確地拆分為塊。在某些情況下,可能需要多個 LLM 的復雜鏈。要優化 RAG 性能并衡量成功與否,請使用一組強大的評估器和指標。
要開始,請查看作為此帖子的完整筆記本,該筆記本是 NVIDIA Generative AI 示例存儲庫的一部分。有關其他型號和鏈條的更多信息,請參閱NVIDIA AI LangChain 端點。
?