GPU 在擴展 AI 方面有許多好處,從更快的模型訓練到 GPU 加速的欺詐檢測。在規劃 AI 模型和部署應用程序時,必須考慮可擴展性挑戰,尤其是性能和存儲。
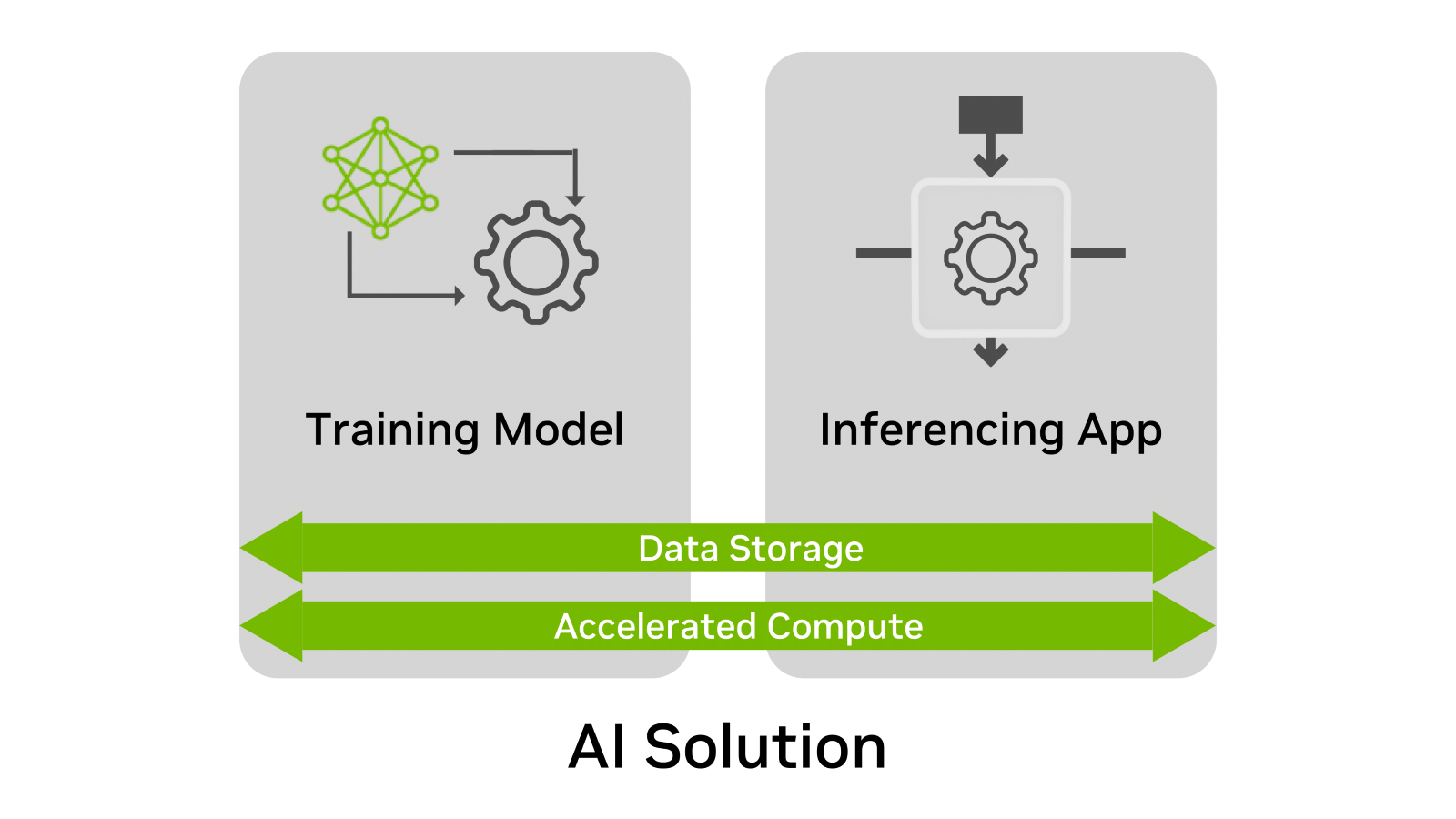
無論使用何種情況,人工智能解決方案都有四個共同點:
- 培訓模式
- 推斷應用程序
- 數據存儲
- 加速計算
在這些元素中, 數據存儲 ?通常是規劃過程中最被忽視的元素。為什么?因為隨著時間的推移,在創建和部署 AI 解決方案時并不總是考慮數據存儲需求。 AI 部署的大多數需求都可以通過 POC 或測試環境快速確認。
然而,挑戰在于 POC 傾向于解決單個時間點。培訓或推斷部署可能會持續數月或數年。由于許多公司迅速擴大了其人工智能項目的范圍,基礎設施也必須進行擴展,以適應不斷增長的模型和數據集。
這篇博客解釋了如何提前計劃和擴展數據存儲以進行訓練和推理。
AI 的數據存儲層次結構
首先,了解 AI 的數據存儲層次結構,包括 GPU 內存、數據結構和存儲設備(圖 2 )。
通常,存儲層次結構中的級別越高,存儲性能就越快,尤其是延遲。在本討論中,存儲被定義為在電源打開或關閉時存儲數據的任何東西,包括內存。
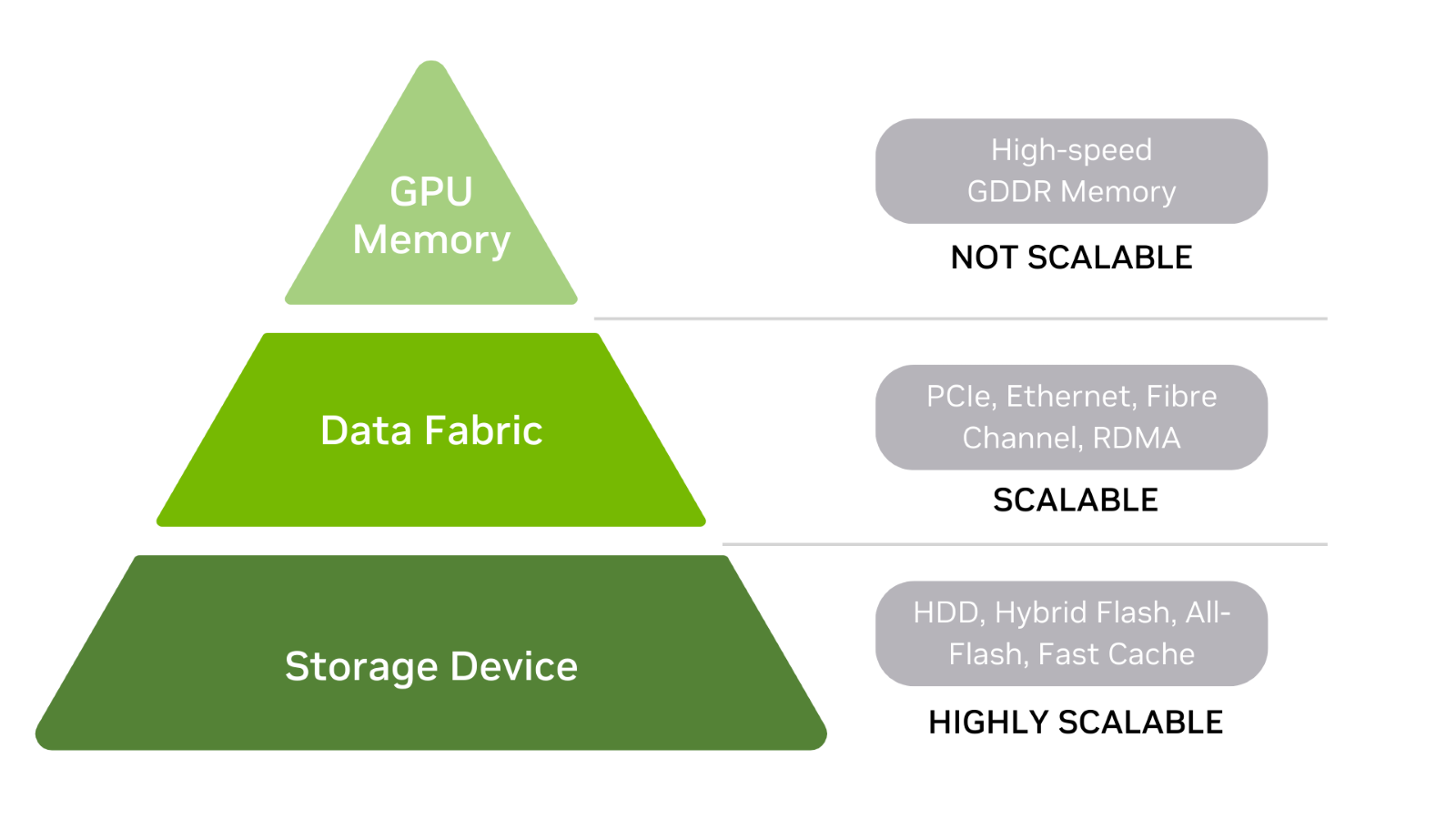
存儲設備
硬盤驅動器和閃存驅動器是存儲層次結構的基礎。還有混合陣列,它們是每種陣列的組合。 HDD 可以前端有一個快速緩存層,而所有閃存陣列都可以使用存儲類內存( SCM )來提高讀取性能。
當大型數據集加載到 GPU 內存的時間很重要時,快速存儲非常有用。當需要訓練不再適合存儲設備的模型時,很容易擴展存儲容量。也可能是必須存儲多個數據集,這是具有可擴展存儲的另一個原因。
數據結構
在層次結構的中間,數據結構用于連接存儲設備和 GPU 內存。
該層包括:
- PCIe 總線
- 網卡
- 動力總成
- 存儲器和 GPU 存儲器之間的數據路徑中的任何其他卡。
為了保持簡單,可以簡單地將結構視為存儲設備和 GPU 存儲器之間的傳遞數據層。
GPU 存儲器
存儲層次結構的頂部是 GPU 內存(通常稱為 vRAM )。由于 GPU 內存速度快且直接連接到 GPU ,因此當整個模型駐留在內存中時,訓練數據集可以快速處理。 CPU 內存也位于層次結構的頂部,正好位于 GPU 內存的下方。
或者,模型數據可以多批次發送到 GPU 存儲器。大 GPU 內存導致更少的批次和更快的訓練時間。如果 GPU 穿過數據結構到達模型或數據集的任何部分的內部或外部存儲,則將活動交換到磁盤會大大降低訓練性能。
請記住,雖然存儲設備和數據結構可以擴展,但 GPU 內存是固定的。這意味著 GPU 內存已配置為 GPU .內存大小無法升級以支持更大的訓練模型和數據集。
如果制造商支持,例如通過 NVIDIA NVLink ,原始 GPU 可以使用添加的 GPU 的內存。然而,并非所有系統都能容納第二個 GPU 和附加存儲器的可能性。
最終,部署計劃應包括內存遠遠超過當前需求的 GPU 。解決未來的內存短缺可能代價高昂。
擴展存儲以進行推斷時的注意事項
推理是 AI 解決方案的價值所在。因此,需要有效的存儲。
要確保推理存儲是可擴展的,請考慮以下因素:
- 放大和縮小
- 無縫升級
- 實時要求
放大和縮小
存儲可擴展性不僅僅以容量來衡量。它也以性能來衡量。真正的橫向擴展可確保當容量和性能需求增加時,存儲系統可以根據需要提供更多的容量和性能。

讓我們來看看一個實際的縮放示例。舊金山旅游區有幾十輛三輪車。一個騎自行車的人或司機駕駛一輛載客量為 2 人、 4 人甚至 6 人的三輪車。
只有一名乘客,駕駛員可以快速踩踏板,更快地到達目的地,并更快地尋找新乘客。三輪車裝載了更多的乘客,導致加速較慢,最高速度較低,一天的行程也較少。三輪車是一種放大機器。
您可以很容易地增加容量,但由于僅限于單個驅動程序的能力,性能沒有相應的提高。通過一臺比例縮小機,每增加一名乘客,一名額外的駕駛員為三輪車提供動力。當功率和容量線性增加時,性能永遠不會成為瓶頸。
對于推斷,容量和性能的真正擴展是關鍵。推理服務器可以隨時間存儲大量數據。存儲讀取和寫入性能必須可擴展,以防止延遲推斷結果。
但是,存儲容量也必須隨著語音、圖像、客戶檔案和其他數據在推理應用程序執行時寫入磁盤而擴展。還需要有效地存儲再培訓數據,以便反饋到模型中。
無縫升級
某些推理應用程序不能很好地容忍宕機。例如,關閉網店欺詐檢測的最佳時機是什么?當您禁用網絡商店推薦引擎以升級存儲容量或存儲性能時,丟失訂單的成本是多少?
可能受到維護升級影響的推理應用程序列表非常廣泛。示例包括:
- 用于客戶服務的對話式 AI 應用程序。
- 全天候分析視頻流,實現智能洞察。
- 關鍵的圖像識別應用程序。
除非推理能夠容忍維護窗口,否則擴展容量和性能將成為一項挑戰。在進行特定的存儲部署之前,最好先考慮存儲升級和可用性方案。
實時要求
作為實時推理示例,考慮在線交易的欺詐檢測。推理應用程序正在尋找揭示不可接受風險的異常行為和交易概況。當用戶等待交易批準時,數百個決策必須在幾秒鐘內做出。低延遲存儲和高性能數據結構連接是實時事務的關鍵,尤其是當必須從存儲中快速檢索風險參數時。
亞毫秒存儲性能是某些實時應用程序的起點,這些應用程序得益于存儲和 GPU 內存之間的高性能通道。 NVIDIA 利用 RDMA 協議加速從存儲到 vRAM 的傳輸,其功能稱為 NVIDIA GPUDirect 存儲。這可以縮短實時所需的存儲數據(如風險概況數據)的 GPU 檢索時間。檢索到的概況和風險數據點可以稍后重新分析以提高準確性。
NVIDIA GPUDirect 技術支持 GPU 內存和本地 NVMe 存儲之間的 DMA direct datapath transactions ,或通過 NVMe oF 進行遠程存儲。
解決疏忽問題
在規劃過程中通常有改進的空間。培訓和推理中一些常見的與存儲相關的疏忽包括可擴展性、性能、可用性和成本。
在訓練和推理過程中,有一些方法可以避免這種情況。
培訓:
- 始終使用遠遠超過當前要求的 GPU 內存進行部署。
- 始終考慮未來模型和數據集的大小,因為 GPU 內存不可擴展。
推論:
- 當性能和容量預計會隨時間增長時,選擇橫向擴展存儲。
- 選擇支持無縫升級的存儲,特別是對于幾乎沒有維護窗口的應用。
- 未來支持實時推理應用程序的存儲升級可能是不可能的,也不現實。在初始 GPU 、存儲和結構部署之前做出這些決定。
關鍵要點
應盡早以全面的方式解決擴展存儲問題。這包括容量、性能、網絡硬件和數據傳輸協議。最重要的是,確保充足的 GPU 資源,否則可能會抵消所有其他訓練和推理努力。
在文章 Storage Performance Basics for Deep Learning 中,更好地了解工作負載復雜性如何影響存儲性能。
此外,考慮使用 NVIDIA-Certified GPU 加速工作站和服務器,因為它們已通過各種企業存儲和網絡產品的認證。
?






