這些年來,人工智能有了巨大的增長。隨之而來的是對人工智能模型和應用程序的更大需求。創造高質量的人工智能需要人工智能和數據科學方面的專業知識,對許多開發人員來說,這仍然是一種威脅。
為了開發準確的人工智能,您必須選擇要使用的模型架構、要收集的數據,以及最后如何調整模型以滿足期望的 KPI 。有成千上萬的模型架構和超參數組合,您必須嘗試為您的特定用例獲得最佳模型。這個過程非常費力,需要模型架構專業知識來調整超參數。
自動機器學習( AutoML )自動執行手動任務,為所需 KPI 找到最佳模型和超參數。它可以從算法上為給定的 KPI 導出最佳模型,并抽象出 AI 模型創建和優化的許多復雜性。
AutoML 使得即使是新手開發人員也很容易創建高度精確的 AI 模型。
TAO 中的 AutoML
TAO 中的 AutoML 完全可配置,用于自動優化模型的超參數,這減少了手動調整的需要。它迎合了人工智能專家和非專家。
- 對于非專家, Jupyter 筆記本電腦為創建精確的人工智能模型提供了一種簡單、高效的方法。
- 對于專家來說, TAO 可以讓您完全控制要調整的超參數以及用于掃描的算法。
TAO 目前支持兩種優化算法: Baysian 和雙曲線優化。這些算法可以有效地掃描一系列超參數,以找到優化用戶提供的度量的最佳組合。
雙曲線產生的速度更快,因為它不必貫穿整個訓練配置。它只運行有限的時間段,丟棄表現不佳的運行,只在剩余的運行中繼續。這種消除過程將繼續進行,直到有一種配置能夠提供最佳結果。
對于貝葉斯,所有掃描的訓練都將持續到完成。
AutoML 支持多種 CV 任務:圖像分類、對象檢測、分割和 OCR 。表 1 顯示了支持的網絡的完整列表。
| Image Classification | Object Detection | Segmentation | OCR |
| ResNet10/18/34/50/101 EfficientNet_B0-B7 DarkNet19/53 CSPDarkNet19/53/Tiny MobileNet_v1/v2 SqueezeNet VGG16/19 GoogleNet |
YoloV3/V4/V4-Tiny EfficientNet RetinaNet FasterRCNN DetectNet_v2 SSD/DSSD |
UNET MaskRCNN | LPRNet |
AutoML 入門
整個 AutoML 工作流可以從提供的 Jupyter 筆記本運行。 AutoML 使用 TAO API 服務來管理所有培訓工作。
TAO API 服務
TAO API 是一種 Kubernetes 服務,它支持將 TAO 作為微服務部署在您自己的 Kubernete 集群上或使用 Amazon EKS 或 Azure AKS 等云 Kubernets 服務。
TAO API 服務為容器提供了額外的抽象層。您可以使用 Helm 圖表管理和部署 TAO 服務,并使用 REST API 調用遠程運行作業。使用 API ,您可以遠程創建和上載數據集、運行培訓作業、評估模型和導出模型以進行部署。
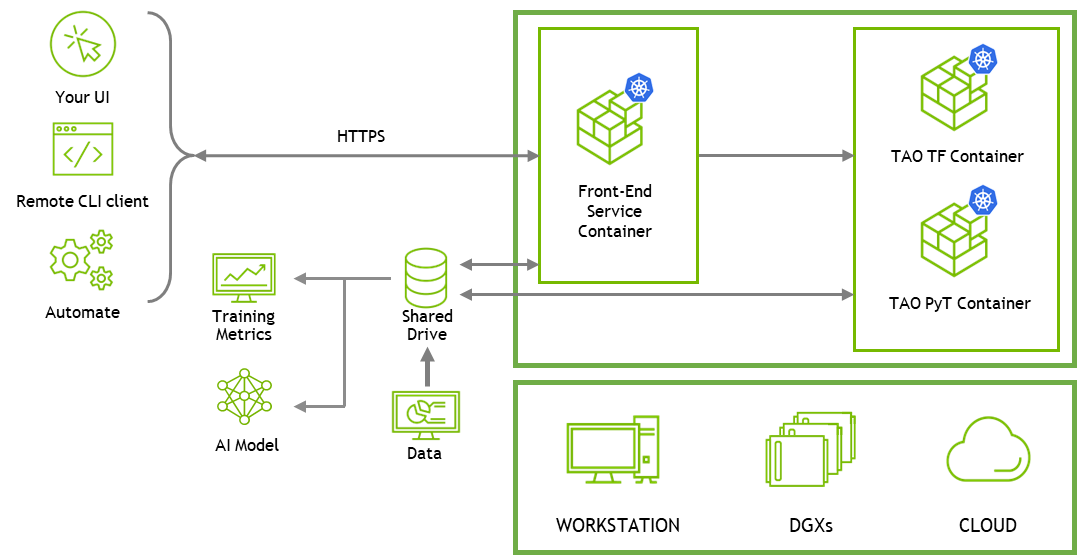
API 服務可以輕松地將 TAO 集成到您自己的自定義應用程序中,或在 TAO 之上構建 web UI 應用程序。要開始使用 REST API 構建自定義應用程序,請參閱 API guide 和 TAO Toolkit Getting Started 中的 API 筆記本。有關更多信息,請參閱本文后面的筆記本部分。
要使用 CLI 進行培訓,請使用可以安裝在客戶端系統上的輕量級 CLI 客戶端應用程序來訪問 TAO 服務和 CLI 筆記本。 NGC 的 TAO getting started resources 中提供了 CLI 筆記本。
AutoML 需要在訓練運行的基礎上提供更高級別的服務,以確定和管理一組實驗。 TAO 服務跟蹤他們用 KPI 進行的所有實驗,并構建下一組實驗以改進 KPI 。您可以通過遠程 CLI 應用程序或直接使用 REST API 使用 TAO API 服務運行 AutoML 。提供兩種類型的 Jupyter 筆記本。有關詳細信息,請參閱筆記本部分。
如果您在 TAO 之上構建自己的應用程序或 UI , RESTAPI 筆記本主要用作參考。
設置 TAO 服務
Amazon API 服務可以在任何 Kubernetes 平臺上運行。為了簡化 TAO 服務的部署,我們提供了一個一鍵部署腳本。這簡化了在裸機設置或 TAO EKS 上部署 TAO 服務。在本文中,我們使用裸機設置,但 API 指南中提供了在云上部署的說明。
先決條件
- NVIDIA GPU (內部或云端):
- NVIDIA Volta 架構
- NVIDIA 圖靈架構
- NVIDIA Ampere 架構
- NVIDIA Hopper 架構
- TAO 工具包 4.0
- Ubuntu 18.04 或 20.04
使用 NGC CLI 下載一鍵部署文件夾:
ngc registry resource download-version "nvidia/tao/tao-getting-started:4.0.0"
更改當前目錄:
cd tao-getting-started_v4.0.0/cv/resource/setup/quickstart_api_bare_metal
在hosts文件中添加主機 IP 地址和登錄憑據。這是您計劃運行 TAO 服務的系統。它可以是本地或遠程系統,但您必須具有sudo權限。
對于憑據,可以使用密碼(ansible_ssh_pass)或 SSH 私鑰文件(ansible_ssh_private_key_file)。對于單節點群集,只能列出主節點。
File name: hosts: [master] <IP Address> ansible_ssh_user='<username>' ansible_ssh_pass='<password>' [nodes] <IP Address> ansible_ssh_user='<username>' ansible_ssh_pass='<password>'
您可以使用以下命令驗證遠程計算機的 SSH 憑據。正確的答案應該是根。
ssh <username>@<IP Address> 'sudo whoami'
接下來,修改tao-toolkit-api-ansible-values.yml文件以添加 NGC 憑證和 Helm 圖表。這將從 NGC 注冊表中提取 Helm 圖。有關詳細信息,請參見 Generating Your NGC API Key 。
File name: tao-toolkit-api-ansible-values.yml ngc_api_key: <NGC API Key> ngc_email: <NGC email> api_chart: https://helm.ngc.nvidia.com/nvidia/tao/charts/tao-toolkit-api-4.0.0.tgz api_values: ./tao-toolkit-api-helm-values.yml cluster_name: tao-automl-demo
安裝依賴項并部署 TAO 服務。在安裝之前,首先通過運行check-inventory.yml檢查是否滿足所有依賴項。如果一切正常,您應該會看到一條消息,顯示 0 失敗。然后,運行install,這需要 10 – 15 分鐘。
bash setup.sh check-inventory.yml bash setup.sh install
下載 AutoML 筆記本
從 NGC 上的 TAO Toolkit Getting Started 下載計算機視覺訓練資源。
wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tao/getting_started/versions/4.0.0/zip -O getting_started_v4.0.0.zip unzip -u getting_started_v4.0.0.zip -d ./getting_started_v4.0.0 && rm -rf getting_started_v4.0.0.zip && cd ./getting_started_v4.0.0
所有與 AutoML 相關的筆記本都位于 TAO API 目錄中。筆記本以目錄結構提供:
notebooks
|--> tao_api_starter_kit
|--> API
|--> automl
|--> end2end
|--> dataset_prepare
|--> client
|--> automl
|--> classification.ipynb
|--> object_detection.ipynb
|--> segmentation.ipynb
|--> lprnet.ipynb
|--> end2end
|--> dataset_prepare
對于這篇文章,請使用對象檢測筆記本(TAO API Starter Kit/Notebooks/client/automl/object_detection.ipynb),但您也可以在其他計算機視覺任務上執行 AutoML 。
使用 AutoML 使用 TAO 微調對象檢測模型
以下是使用對象檢測 AutoML 筆記本快速演練 AutoML 工作流。在本演練中,將使用前面顯示的層次結構中的client/automl/object_detection.ipynb筆記本。我們在這里強調了關鍵步驟,但所有步驟都記錄在 Jupyter 筆記本中。

選擇模型拓撲
選擇為該筆記本列出的任何一種可用型號。每個筆記本都有該域的默認模型。在此示例中,默認模型為 DetectNet V2 ,但您可以將其更改為 FasterRCNN 、 SSD 、 DSSD 、 Retinanet 、 EfficientDet 、 Yolo V3 、 Yolo V4 或 YoloV4 tiny 。
model_name = "detectnet-v2"
創建數據集
下一步是使用筆記本中給出的數據集作為示例,或者使用自己的數據集。筆記本中提供了數據集要求的文件夾結構。
train_dataset_id = subprocess.getoutput(f"tao-client {model_name} dataset-create --dataset_type object_detection --dataset_format {ds_format}")
print(train_dataset_id)
eval_dataset_id = subprocess.getoutput(f"tao-client {model_name} dataset-create --dataset_type object_detection --dataset_format {ds_format}")
print(eval_dataset_id)
上載數據集
準備好數據集后,通過用于 TAO 客戶端筆記本的 Unix rsync命令將其上載到 TAO Toolkit REST API 部署的計算機。您必須上傳培訓和驗證數據的圖像和標簽。
rsync -ah --info=progress2 {TRAIN_DATA_DIR}/images ~/shared/users/{os.environ['USER']}/datasets/{train_dataset_id}/
rsync -ah --info=progress2 {TRAIN_DATA_DIR}/labels ~/shared/users/{os.environ['USER']}/datasets/{train_dataset_id}/
rsync -ah --info=progress2 {VAL_DATA_DIR}/images ~/shared/users/{os.environ['USER']}/datasets/{eval_dataset_id}/
rsync -ah --info=progress2 {VAL_DATA_DIR}/labels ~/shared/users/{os.environ['USER']}/datasets/{eval_dataset_id}/
轉換數據集
上傳數據集后,通過數據集轉換操作將數據集轉換為tfrecords。所有對象檢測模型都需要數據集轉換,但其他領域的一些模型(如分類)可以對上傳的原始數據進行操作。
train_convert_job_id = subprocess.getoutput(f"tao-client {model_name} dataset-convert --id {train_dataset_id} --action {convert_action} ")
配置 AutoML 參數
下一步是選擇要運行的 AutoML 算法。有一些選項可以調整某些特定于 AutoML 的參數。您可以查看默認情況下為模型的 AutoML 搜索啟用的參數,以及網絡可用的所有參數
tao-client {model_name} model-automl-defaults --id {model_id} | tee ~/shared/users/{os.environ['USER']}/models/{model_id}/specs/automl_defaults.json
這將輸出用于 AutoML 的超參數列表。對于這個實驗,您選擇了五個不同的超參數來掃描。
[ "bbox_rasterizer_config.deadzone_radius", "training_config.learning_rate.soft_start_annealing_schedule.min_learning_rate", "training_config.learning_rate.soft_start_annealing_schedule.annealing", "training_config.regularizer.type", "classwise_config.postprocessing_config.clustering_config.dbscan_confidence_threshold" ]
您可以添加其他參數或刪除現有的默認參數。例如,要掃描soft_start超參數,請在筆記本中添加以下內容:
additional_automl_parameters = [“training_config.learning_rate.soft_start_annealing_schedule.soft_start”]
也有調整算法特定參數的選項,但默認參數工作正常。有關詳細信息,請參見 AutoML 。
使用 AutoML 訓練
此時,您已經擁有啟動 AutoML 運行所需的所有工具。您還可以在觸發 AutoML 運行之前更改默認訓練規范,如圖像擴展或類映射:
train_job_id = subprocess.getoutput(f"tao-client {model_name} model-train --id " + model_id)
當 AutoML 運行開始時,您可以看到各種統計數據,例如當時的最佳準確度分數、已完成的實驗數量、估計完成時間等。您應該看到類似于以下內容的輸出日志。
{
"best_map": 0.59636,
"Estimated time for automl completion": "23.13 minutes remaining approximately",
"Current experiment number": 3,
"Number of epochs yet to start": 429.0,
"Time per epoch in seconds": 3.24
}
比較模型
在 AutoML 運行結束時,您可以看到所有實驗的結果。您將看到在 AutoML 掃描中實現最高精度的模型的等級庫文件和二進制權重文件。
Checkpoints for the best performing experiment
Folder: /home/nvidia/shared/users/95af85a9-805c-5680-b01a-3c85ed70f009/models/4f22c462-1d97-4537-99b2-15ee69eb2660/168d6149-6c47-40e6-b6a3-267867cea551/best_model/weights
Files: [epoch-80.tlt']
Results of all experiments
id result
0 0 0.43636
1 1 0.41818
2 2 0.53636
3 3 0.44545
4 4 0.33636
5 5 0.44545
6 6 0.53636
7 7 0.53636
8 8 0.61636
9 9 0.62727
10 10 0.593636
11 11 0.52727
12 12 0.53636
13 13 0.54545
14 14 0.61636
15 15 0.60909
16 16 0.5636
17 17 0.54545
18 18 0.53636
19 19 0.53636
最佳實驗的規范文件存儲在以下目錄中:
{home}/shared/users/{os.environ['USER']}/models/{model_id}/{train_job_id}/{automl_job_dir}/best_model
該實驗的最佳模型是 mAP 為 0.627 的 ID 9 。這存儲在best_model/recommendataion_9.kitti文件中。
保存從 AutoML 獲得的最佳模型后,您可以將模型和規范文件插入到端到端筆記本中,然后修剪和優化模型以進行推斷。
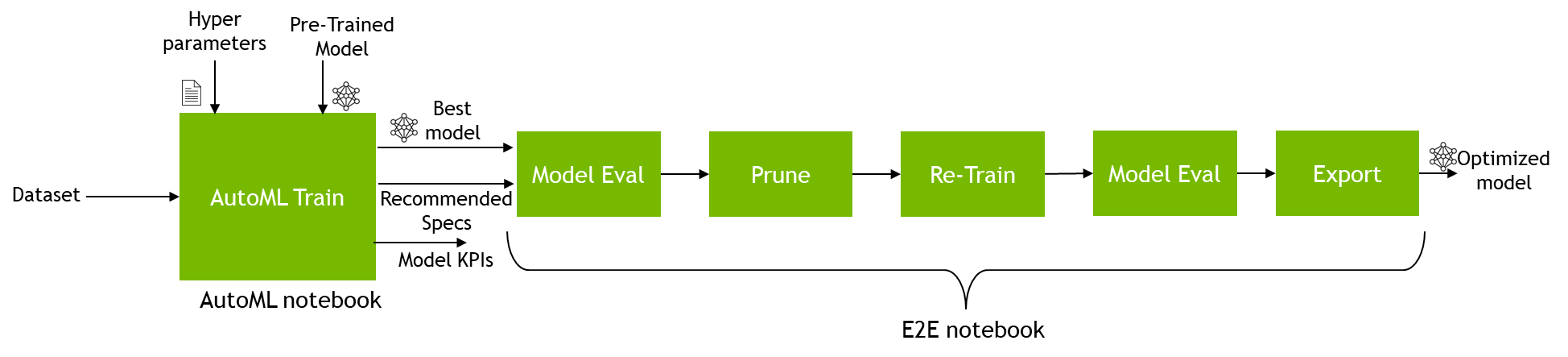
要將模型插入新筆記本,請從 AutoML 筆記本復制列車作業 ID 。運行培訓作業時會打印 AutoML 培訓作業 ID 。
train_job_id = subprocess.getoutput(f"tao-client {model_name} model-train --id " + model_id)
print(train_job_id)
當您具有培訓作業 ID 時,請從前面的筆記本層次結構中打開端到端筆記本。對于這篇文章,請使用TAO API Starter Kit/Notebooks/client/end2end/detectnet_v2.ipynb筆記本。由于您已經訓練了一個模型,只需在第一個單元格中運行import語句,然后一直跳到Run Evaluate部分。在本節中,在計算之前創建一個代碼單元。
train_job_id = “id_you_copied”
在添加job_map代碼單元后,您可以評估模型,修剪模型以進行壓縮,甚至可以對原始模型或修剪后的模型進行量化感知訓練,如端到端筆記本中所示
后果
我們在公共數據集上使用 AutoML 訓練了各種模型,以了解我們可以在準確性方面提高多少。我們將基于 AutoML 的最佳精度與包中提供的默認規范文件中的基線精度數字進行了比較。結果見表 2 。
- 對于物體檢測,我們在 FLIR dataset 上進行了訓練,其中包含來自熱傳感器和 RGB 傳感器的圖像。
- 對于圖像分類,我們使用 Pascal VOC 20 12 Dataset 。
- 對于語義分割,我們使用 ISBI dataset 。
為了準確度,我們使用 mAP (平均平均精度)進行對象檢測,使用所有類別和任務的平均精度進行圖像分類,使用平均 IoU (交集加聯合)得分進行語義分割。
| Task | Model | Baseline Accuracy (default spec) |
Best AutoML accuracy | Dataset |
| Object Detection | DetectNet_v2 – ResNet18 | 44.16 | 51.37 | FLIR |
| Object Detection | FasterRCNN – ResNet18 | 56.42 | 60.44 | FLIR |
| Object Detection | YOLOv4 – ResNet18 | 40.12 | 63.46 | FLIR |
| Object Detection | YOLOv3 – ResNet18 | 42.36 | 61.84 | FLIR |
| Object Detection | RetinaNet – ResNet18 | 50.54 | 63.09 | FLIR |
| Image Classification | ResNet18 | 53.95 | 66.28 | Pascal VOC |
| Semantic Segmentation | UNET | 71.64 | 76.65 | ISBI |
在我們測試的所有模型中,與靜態默認超參數相比,模型精度的提高是顯著的。改進的程度因模型而異,但我們通常看到 5% 到 20% 以上的改進。這表明 AutoML 可以在各種數據集上工作,以訓練給定 KPI 的最佳模型。
總結
隨著用例和定制數量的增長,加快人工智能創建過程變得勢在必行。 AutoML 可以消除手動調優的需要,為開發人員節省寶貴的時間。
有了 TAO AutoML ,您現在可以使用各種流行的模型架構自動調整模型以用于對象檢測、分類和分割用例。 TAO AutoML 為新手用戶入門提供了簡單性,也為專家選擇自己的超參數進行掃描提供了可配置性。






