
在當今的全球化世界中,AI 系統理解和溝通不同語言的能力變得越來越重要。大型語言模型 (LLMs) 徹底改變了自然語言處理領域,使 AI 能夠生成類似人類的文本、回答問題和執行各種語言任務。然而,大多數主流 LLM 都在主要由英語組成的數據語料庫上進行訓練,從而限制了它們對其他語言和文化語境的適用性。
這就是 多語種 LLM 的價值所在:縮小語言差距,并釋放 AI 的潛力,使其惠及更廣泛的受眾。
特別是,由于訓練數據有限以及東南亞 (SEA) 語言的獨特語言特性,當前最先進的 LLM 經常難以與這些語言進行交流。這導致與英語等高資源語言相比,性能較低。雖然一些 LLM 在一定程度上可以處理某些 SEA 語言,但仍然存在不一致、幻覺和安全問題。
與此同時,人們對在東南亞開發本地化的多語種 LLM 有著濃厚的興趣和決心。一個值得注意的例子是,新加坡啟動了一項 7000 萬新元的計劃,以開發國家多模態大型語言模型計劃 (NMLP)。
這項為期兩年的國家層面計劃旨在打造東南亞首個區域 LLM,專注于了解該地區獨特的語言和文化細微差別。隨著東南亞地區對 AI 解決方案的需求不斷增長,開發本地化的多語種 LLM 成為戰略需要。
在其他地區也可以看到類似的趨勢,目前先進的 LLM 不足以支持復雜的區域語言。這些模型可以幫助企業和組織更好地服務客戶、實現流程自動化,并創建更具吸引力的內容,與該地區的多元化人口產生共鳴。
NVIDIA NeMo 是一個端到端平臺,旨在隨時隨地開發自定義生成式 AI。它包括用于訓練的工具、檢索增強生成(RAG)、護欄和工具包、數據管護工具以及預訓練模型,為企業提供了一種簡單、經濟高效且快速的方法來采用生成式 AI。
在本系列中,我們將探索使用 Omniverse Create 向基礎語言模型(LLM)添加新語言支持的最佳實踐。本教程將指導您完成 NeMo 的關鍵步驟,包括分詞器訓練和合并、模型架構修改和模型持續預訓練等。
在本文中,我們使用泰文維基百科數據對 GPT-1.3 B 模型進行持續預訓練。我們在第 1 部分中著重介紹了訓練和合并多語種分詞器,然后討論了在 NeMo 模型中采用自定義分詞器的方法,并將在 第 2 部分 中繼續探討。
通過遵循這些指南,您可以為多語種 AI 的發展做出貢獻,并讓更廣泛的全球受眾受益于 LLM。
本地化多語種 LLM 訓練概述
多語種 LLM 面臨的一個重大挑戰是,理解目標語言的預訓練基礎 LLM 不足。要構建多語種 LLM,您有以下幾種選擇:
- 使用多語種數據集從頭開始預訓練 LLM。
- 使用目標語言的數據集對英語基礎模型進行持續預訓練。
在低資源語言的情況下,后一種選擇更可行。根據定義,低資源語言的可用訓練數據有限。通過利用從最初訓練模型所基于的高資源語言進行遷移學習,持續預訓練可以有效地使模型適應新語言,即使數據量相對較少。
從頭開始預訓練需要使用低資源語言處理更大量的數據,才能達到相同的性能水平。
在嘗試使用低資源數據進行持續預訓練時,我們面臨的一個挑戰是次優分詞器。大多數基礎模型都采用字節對編碼 (BPE) 分詞器。原始分詞器無法充分涵蓋低資源語言的獨特字符、子詞和形態。
如果沒有足夠富有表現力的分詞器,模型將難以高效地表示低資源語言,從而導致性能欠佳。有必要構建自定義分詞器,使模型能夠在持續預訓練期間更有效地處理和學習低資源語言數據。
為解決這些問題,我們建議通過以下工作流程為 LLM 添加新的語言支持。
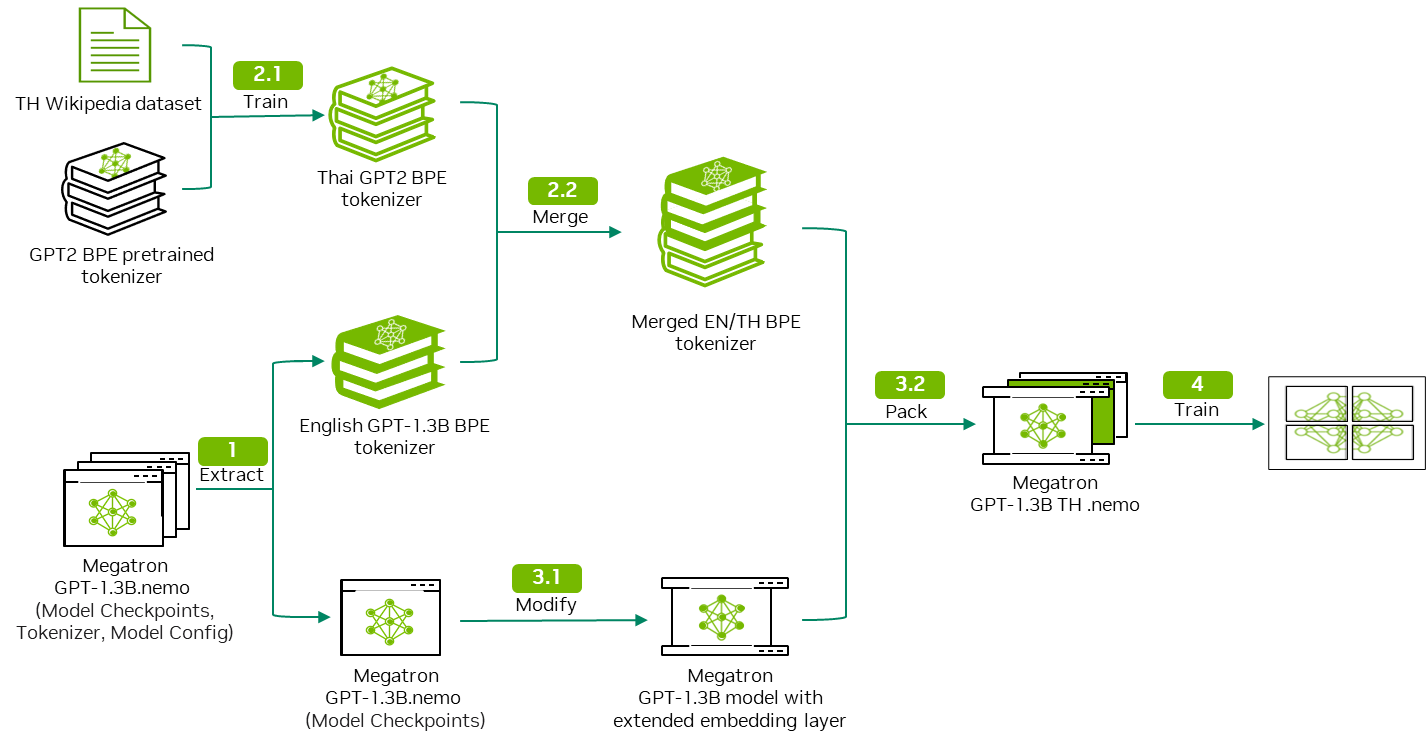
此工作流程將泰文維基百科數據用作以下步驟中的輸入示例:
- 下載并解壓縮 GPT 模型以獲取模型權重和模型分詞器。
- 自定義分詞器訓練并合并以輸出雙語分詞器。
- 修改 GPT 模型架構以適應雙語言分詞器。
- 使用泰文維基百科數據執行持續預訓練。
該工作流程具有通用性,可以應用于不同的語言數據集。本博文詳細介紹了步驟 1 和 2。欲了解步驟 3 和 4 的詳細信息,請參閱 第 2 部分。
教程預備知識
如需持續預訓練 GPT-1.3 B 模型,我們建議使用以下硬件設置:
- 配備至少 30 GB GPU 顯存的 NVIDIA GPU
- CUDA 和 NVIDIA 驅動:帶驅動 535.154.05 的 CUDA 12.2
- Ubuntu 22.04
- NVIDIA Container Toolkit 版本 1.14.6:安裝指南
- 我們使用了 NeMo 框架容器 24.01.01 版本。
我們通過 NGC 目錄 提供對 GPU 加速軟件的訪問,旨在通過性能優化的容器、預訓練的 AI 模型以及可在本地、云端或邊緣部署的行業特定 SDK,以加速端到端工作流程。
第一步,從 NGC 目錄中下載 NeMo 框架容器,并在容器鏡像中運行 JupyterLab:
docker pull nvcr.io/nvidia/nemo:24.01.01.frameworkdocker run -it --gpus all -v : --workdir -p 8888:8888/ nvcr.io/nvidia/nemo:24.01.01.framework bash -c "jupyter lab" |
數據收集和清理
在本教程中,我們使用 NVIDIA NeMo Curator 的 GitHub 存儲庫,用于下載和整理高質量的泰文維基百科數據。NVIDIA NeMo Curator 由一系列可擴展的數據挖掘模塊組成,旨在整理用于訓練 LLM 的 NLP 數據。NeMo Curator 中的模塊使 NLP 研究人員能夠從大量未整理的網絡語料庫中大規模挖掘高質量文本。
對于管線,請按照以下步驟操作:
- 使用不同的語言篩選非泰語內容。
- 重新格式化文檔以校正任何 Unicode。
- 執行文檔級精確重復數據刪除和模糊重復數據刪除,以刪除重復的數據點。
- 執行文檔級啟發式過濾,以刪除低質量文檔。
通過使用 NVIDIA NeMo Curator 中演示的相同流程,可以復制其他語言的策展過程。
模型下載和提取
在這篇博文中,我們使用 nemo-megatron-gpt-1.3B 模型,該模型基于英語單語數據集 Pile 數據集。您可以直接從 HuggingFace 下載模型,或者運行以下命令下載模型:
!wget -P './model/nemo_gpt_megatron_1pt3b_fb16/' https://huggingface.co/nvidia/nemo-megatron-gpt-1.3B/resolve/main/nemo_gpt1.3B_fp16.nemo |
驗證下載文件的 MD5 校驗和,以確保其完整性:
!md5sum nemo_gpt1.3B_fp16.nemo |
您應獲得以下內容作為輸出:
38f7afe7af0551c9c5838dcea4224f8a nemo_gpt1.3B_fp16.nemo |
下載模型后,解壓模型中的文件:vocab.json 和 merge.txt:
!tar -xvf ./model/nemo_gpt_megatron_1pt3b_fb16/nemo_gpt1.3B_fp16.nemo -C ./model/nemo_gpt_megatron_1pt3b_fb16/ |
執行該命令后,將生成以下輸出。現在,您可以訪問 vocab.json 和 merge.txt 文件,這些文件稍后將用于 tokenizer 的合并。
././50284f68eefe440e850c4fb42c4d13e7_merges.txt./c4aec99015da48ba8cbcba41b48feb2c_vocab.json./model_config.yaml./model_weights.ckpt |
分詞器訓練
要訓練能夠將其他語言和英語標記化的分詞器,您可以采用以下兩種方法之一:
- 多語種數據集:使用包含英語的多語言數據集,從頭開始訓練分詞器,其優點在于您可以獲得多語言數據集的真實分布。
- 單語言數據集:首先訓練單語分詞器,然后將其與原始英語分詞器合并。這樣做的優點是,可以保留英語分詞的原始分詞映射,并重復使用基礎模型的嵌入層,從而縮短分詞器訓練的時間。
本教程使用單語言數據集方法來保留預訓練 GPT Megatron 模型的嵌入層。
此方法的詳細步驟包括:
- 收集分詞器訓練數據:從預訓練數據集中進行子采樣,以獲取 tokenizer 訓練所需的數據。在本教程中,我們隨機采樣了 30% 的訓練數據用于該目的。
- 訓練自定義 GPT2 分詞器:使用預訓練的 HuggingFace 模型作為起點,我們可以使用您自己的數據語料庫來訓練自定義的 TH GPT2 分詞器。
- 合并兩個分詞器:手動合并
merges.txt和vocab.json兩個文件,以創建一個單一的分詞器。
在本教程中,請使用泰語作為目標語言。
導入必要的庫
開始之前,請先導入以下庫:
import os from transformers import GPT2Tokenizer, AutoTokenizer import random import json |
準備訓練語料庫
定義一個名為 convert_jsonl_to_txt 的函數,以從訓練文檔數據中采樣,并將其寫入 .txt 格式的輸出文件中。在本教程中,我們使用 'text' 作為訪問訓練文檔數據的 JSON 密鑰,根據需要可以更改該密鑰。
def convert_jsonl_to_txt(input_file, output_file, percentage, key='text'): with open(input_file, 'r', encoding='utf-8') as in_file, open(output_file, 'a', encoding='utf-8') as out_file: for line in in_file: if random.random() < percentage: data = json.loads(line) out_file.write(f"{data[key].strip()}\n") |
現在,您可以讀取輸入文件并形成分詞器訓練語料庫:
for file in os.listdir('./training_data'): if 'jsonl' not in file: continue input_file = os.path.join('./training_data',file) convert_jsonl_to_txt(input_file,'training_corpus.txt', 0.3)with open('training_corpus.txt', 'r') as file: training_corpus = file.readlines() |
當訓練語料庫過大,無法加載到一個目標中時,可以采用迭代器方法加載訓練語料庫。另外,如果您想了解更多相關信息,請參閱 根據舊的分詞器訓練新的分詞器。
訓練單語分詞器
首先加載預訓練的 GPT2 分詞器,然后調用 tokenizer.train_new_from_iterator 方法,以訓練新分詞器。
Vocab_size 是 tokenizer.train_new_from_iterator 的一個參數,它決定詞匯表中唯一令牌的最大數量。值越大,可實現更精細的令牌化,但會增加模型的復雜性;而值越小,則可實現更粗粒度的令牌化,且唯一令牌越少,模型越簡單。
old_tokenizer = AutoTokenizer.from_pretrained("gpt2")new_tokenizer = old_tokenizer.train_new_from_iterator(training_corpus, vocab_size=8000)new_tokenizer.save_pretrained('./new_monolingual_tokenizer/') |
現在,您已完成訓練新的單語分詞器,請檢查新分詞器在目標語言上的有效性。使用預訓練的 GPT2 分詞器和 TH 分詞器分別將泰語句子和英語句子分詞:
- 泰語句子:“????????????????????????????????” 是指“泰國的首都是曼谷”。
- 英語句子:“The capital of Thailand is Bangkok.”
Thai_text='????????????????????????????????'print(f"Sentence:{Thai_text}")print("Output of TH tokenizer: ",new_tokenizer.tokenize(Thai_text,return_tensors='pt'))print("Output of pretrained tokenizer: ", old_tokenizer.tokenize(Thai_text,return_tensors='pt'))Eng_text="The capital of Thailand is Bangkok."print(f"Sentence:{Eng_text}")print("Output of TH tokenizer: ",new_tokenizer.tokenize(Eng_text,return_tensors='pt'))print("Output of pretrained tokenizer: ", old_tokenizer.tokenize(Eng_text,return_tensors='pt')) |
您應該會得到以下幾行作為輸出:
Sentence:????????????????????????????????Output of TH tokenizer: ['à1?à??', 'à?·', 'à??à??à??à?¥à?§à??', 'à??à??à??à??à?£à?°à1?à??à?¨à1?à??à?¢', 'à??', 'à?·', 'à??à??à?£', 'à??', 'à??à1?à??à??à?ˉ']Output of pretrained tokenizer: ['à1', '?', 'à?', '?', 'à?', '·', 'à?', '?', 'à?', '?', 'à?', '?', 'à?', '¥', 'à?', '§', 'à?', '?', 'à?', '?', 'à?', '?', 'à?', '?', 'à?', '?', 'à?', '£', 'à?', '°', 'à1', '?', 'à?', '?', 'à?', '¨', 'à1', '?', 'à?', '?', 'à?', '¢', 'à?', '?', 'à?', '·', 'à?', '?', 'à?', '?', 'à?', '£', 'à?', '?', 'à?', '?', 'à1', '?', 'à?', '?', 'à?', '?', 'à?', 'ˉ']Sentence:The capital of Thailand is Bangkok.Output of TH tokenizer: ['The', '?c', 'ap', 'ital', '?of', '?Thailand', '?is', '?B', 'ang', 'k', 'ok', '.']Output of pretrained tokenizer: ['The', '?capital', '?of', '?Thailand', '?is', '?Bangkok', '.'] |
從輸出中可以看到,與泰語句子的英語標記器和英語句子的英語標記器相比,TH 標記器生成的標記列表更短。
原因是,許多泰文字符,尤其是那些表示元音和色調標記的字符,在英語分詞器中很可能被視為詞外音(OOV)。分詞器可以將這些字符拆分為單個字節,或將其替換為UNK token,從而增加 token 數量。
分詞器合并
要合并兩個分詞器,您必須處理vocab.json和merges.txt文件。以下是合并這兩個文件的方法。
對于 vocab.json 文件中:
- 維護預訓練的分詞器的
vocab.json文件中的 ID 令牌映射。 - 通過自定義的單語言分詞器迭代處理
vocab.json文件,以便在遇到新令牌時進行更新。 - 將其添加到原始文件
vocab.json中,該文件帶有累加令牌 ID。
關于merges.txt文件:
- 預訓練的分詞器的
merges.txt文件保持不變。 - 通過使用自定義的單語言分詞器來迭代
merges.txt文件。 - 當遇到新的合并規則時,請將其添加到原始規則文件
merges.txt中。
規則是,在合并時,不允許重新排列或修改vocab.json文件或merges.txt文件的原始順序。
對于vocab.json,您必須保持原始 ID 令牌映射相同,才能重用預訓練嵌入層。如果在將新合并的標記器加載到預訓練模型并嘗試獲取令牌的嵌入時,映射受到干擾,模型可能會輸出其他令牌的預訓練嵌入,例如將‘dog’的 token ID 更改為‘cat’,從而導致‘dog’在合并過程中發生更改。
例如,在merges.txt文件中,合并規則的順序對于讓 BPE 標記器在標記化新文本時以最佳狀態運行至關重要。標記化器將按順序應用這些規則,從第一個規則開始,一直向下列表,直到無法應用進一步的規則。因此,合并規則的順序更改將嚴重影響標記化器的性能,并導致次優標記化。
這是一個示例。假設您有一個令牌列表['N', 'VI', 'D', 'IA'],以及兩套不同的合并規則:
Set A: N VI D IA NVI DIASet B: D IA NVI DIA N VI |
在對令牌列表應用集 A 時,分詞器按給定順序遵循合并規則:
['N', 'VI', 'D', 'IA'] -> ['NVI', 'D', 'IA'](應用規則 1。)['NVI', 'D', 'IA'] -> ['NVI', 'DIA'](應用規則 2。)['NVI', 'DIA'] -> ['NVIDIA'](應用規則 3)
標記化的最終輸出結果為['NVIDIA'],這是我們所期望的結果。
但是,將集合 B 應用于同一令牌列表時,分詞器會遇到以下問題:
['N', 'VI', 'D', 'IA'] -> ['N', 'VI', 'DIA'](應用規則 1)。['N', 'VI', 'DIA'](從下一個合并規則中的第一個令牌開始,無法應用更多規則,因為'NVI'未找到。)
在這種情況下,分詞器無法合并 'N'和 'VI' ,因為合并規則 'N VI' 出現在 'NVI DIA' 中。因此,分詞器會生成次優輸出: ['N', 'VI', 'DIA'] ,而不是['NVIDIA']。
更改規則的順序會改變分詞器的行為,并可能降低其性能。
運行以下代碼以進行分詞器合并:
output_dir = './path_to_merged_tokenizer'# Make the directory if necessaryif not os.path.exists(output_dir ): os.makedirs(output_dir)#Read vocab filesold_vocab = json.load(open(os.path.join('./path_to_pretrained_tokenizer', 'vocab.json')))new_vocab = json.load(open(os.path.join('./path_to_cusotmized_tokenizer', 'vocab.json')))next_id = old_vocab[max(old_vocab, key=lambda x: int(old_vocab[x]))] + 1# Add words from new tokenizerfor word in new_vocab.keys(): if word not in old_vocab.keys(): old_vocab[word] = next_id next_id += 1# Save vocabwith open(os.path.join(output_dir , 'vocab.json'), 'w') as fp: json.dump(old_vocab, fp, ensure_ascii=False)old_merge_path = os.path.join('./path_to_pretrained_tokenizer', 'merges.txt')new_merge_path = os.path.join('./path_to_cusotmized_tokenizer', 'merges.txt')#Read merge fileswith open(old_merge_path, 'r') as file: old_merge = file.readlines()with open(new_merge_path, 'r') as file: new_merge = file.readlines()[1:] #Add new merge rules, the order of merge rule has to be maintainedold_merge_set = set(old_merge)combined_merge = old_merge + [merge_rule for merge_rule in new_merge if merge_rule not in old_merge_set] # Save merge.txtwith open(os.path.join(output_dir , 'merges.txt'), 'w') as file: for line in combined_merge: file.write(line) |
現在,您可以加載并測試組合的 tokenizer,并將其 tokenization 輸出與預訓練的 tokenizer 和自定義的單語言 tokenizer 進行比較。您應該能夠觀察到組合的 tokenizer 在將目標語言和英語標記化方面效果良好。
結束語
此時,您已成功自定義能夠將英語和目標語言標記化的 BPE 標記器。
在 下一篇文章 中,我們將修改預訓練模型的嵌入層,以便采用自定義分詞器,并開始將修改后的模型與自定義分詞器一起使用,以便在 NeMo 中進行持續預訓練。
要開始訓練多語種分詞器,請首先下載并設置開源語言數據集,以整理用于訓練的低資源語言數據集。NeMo 策展人 已在 GitHub 上發布。另外,您還可以通過 NeMo 微服務搶先體驗 請求訪問 NVIDIA NeMo Curator,以加速和簡化數據管護流程。
?






