
人體姿態估計是一種流行的計算機視覺任務,用于估計人體上的關鍵點,如眼睛、手臂和腿部。這有助于對一個人的行為進行分類,如站立、坐下、走路、躺下、跳躍等。
了解一個人在一個場景中所做的事情的背景在許多行業都有廣泛的應用。在零售環境中,這些信息可用于了解客戶行為、增強安全性和提供更豐富的分析。在醫療保健領域,這可以用來監測病人,并在病人需要立即治療時提醒醫務人員。在工廠里,人體姿勢可以用來識別是否遵循了正確的安全協議。
一般來說,在需要了解人類活動的應用程序中,這是一種可靠的方法,通常用作更復雜任務(如手勢、跟蹤、異常檢測等)的關鍵組件之一。
?
存在開發姿態估計的開源方法,但在推理性能方面不是最優的,并且集成到生產應用程序中非常耗時。通過這篇文章,我們將向您展示如何開發和部署姿勢估計模型,這些模型易于跨設備配置文件使用,性能非常好,并且非常精確。
姿勢估計已與 NVIDIA 轉移學習工具包( TLT ) 3 . 0 集成,因此您可以利用 TLT 的所有功能(如模型修剪和量化)來創建精確和高性能的模型。經過訓練后,您可以部署此模型進行推理以獲得實時性能。
本系列文章將引導您完成培訓、優化、部署實時高性能姿勢估計模型的步驟。在第 1 部分中,您將學習如何使用開放源代碼 COCO 數據集訓練二維姿勢估計模型。在 第 2 部分 中,您將學習如何為推理吞吐量優化模型,然后使用 TLT-CV 推理管道部署模型。我們將 TLT 訓練模型與其他最先進的模型進行了比較。
用 TLT 訓練二維姿態估計模型
在本節中,我們將介紹有關使用 TLT 訓練 2D 姿勢估計模型的以下主題:
- Methodology
- 環境設置
- 數據準備
- 實驗配置文件
- Training
- Evaluation
- 模型驗證
Methodology
BodyPoseNet 模型的目標是預測給定輸入圖像中每個人的骨架,骨架由關鍵點和關鍵點之間的連接組成。
兩種常用的姿態估計方法是自頂向下和自下而上。自頂向下的方法通常使用對象檢測網絡來定位幀中所有人的邊界框,然后使用姿勢網絡來定位該邊界框內的身體部位。顧名思義,自下而上的方法從下到上構建骨架。它首先檢測一個框架內的所有人體部位,然后使用一種方法對屬于特定人的部位進行分組。
采用自下而上的方法有幾個原因。一是推理性能較高。與自頂向下的姿勢估計方法不同,自下而上的方法不需要單獨的人檢測器。計算不會隨場景中的人數線性縮放。這使您能夠實現擁擠場景的實時性能。此外,自底向上還具有全局上下文的優點,因為將整個圖像作為輸入提供給網絡。它可以更好地處理復雜的姿勢和擁擠。
鑒于這些原因,這種方法的目的是實現有效的單桿,自下而上的姿態估計,同時也提供競爭力的準確性。本文使用的默認模型是完全卷積模型,由主干網、初始預測階段組成,該階段對置信圖( heatmap )和部分親和場( PAF )進行像素級預測,然后對初始預測進行多級細化( 0 到 N 階段)。此解決方案簡化并抽象了自底向上方法的許多復雜性,同時允許針對特定應用程序調整必要的旋鈕。
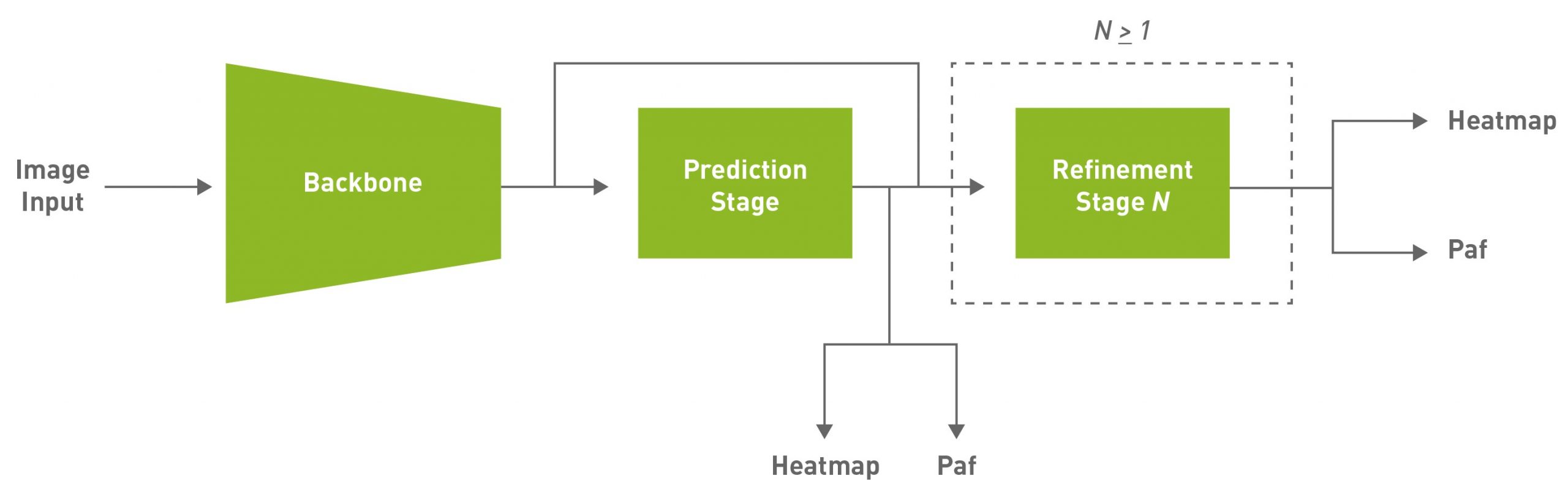
PAFs 是一種用自下而上的方法表示關聯分數的方法。有關詳細信息,請參閱 基于部分相似域的實時多人二維姿態估計 。它由一組二維向量場組成,對肢體的位置和方向進行編碼。這與熱圖相關聯,用于在后處理期間通過執行二部匹配和關聯身體部位候選來構建骨架。
環境設置
NVIDIA TLT 工具包有助于抽象出 AI / DL 框架的復雜性,并使您能夠更快地構建生產質量模型,而無需編碼。有關硬件和軟件要求、設置所需依賴項以及安裝 TLT 啟動器的更多信息,請參閱 TLT 快速入門指南 。
使用以下命令下載最新示例:
ngc registry resource download-version "nvidia/tlt_cv_samples:v1.1.0"
您可以在 tlt_cv_samples:v1.1.0/bpnet 找到示例筆記本,其中還包含所有詳細步驟。
為 cleaner 命令行命令設置 env 變量。更新以下變量值:
export KEY=<key> export NUM_GPUS=1 # Local paths # The dataset is expected to be present in $LOCAL_PROJECT_DIR/bpnet/data. export LOCAL_PROJECT_DIR=/home/<username>/tlt-experiments export SAMPLES_DIR=/home/<username>/tlt_cv_samples_vv1.1.0 # Container paths export USER_EXPERIMENT_DIR=/workspace/tlt-experiments/bpnet export DATA_DIR=/workspace/tlt-experiments/bpnet/data export SPECS_DIR=/workspace/examples/bpnet/specs export DATA_POSE_SPECS_DIR=/workspace/examples/bpnet/data_pose_config export MODEL_POSE_SPECS_DIR=/workspace/examples/bpnet/model_pose_config
要運行 TLT 啟動程序,請使用 ~/.tlt_mounts.json 文件將本地計算機上的~/ TLT-experiments 目錄映射到 Docker 容器。有關詳細信息,請參閱 TLT 發射器 。
創建 ~/.tlt_mounts.json 文件并更新其中的以下內容:
{
??? "Mounts": [
??????? {
??????????? "source": "/home/<username>/tlt-experiments",
??????????? "destination": "/workspace/tlt-experiments"
??????? },
??????? {
??????????? "source": "/home/<username>/tlt_cv_samples_vv1.1.0/bpnet/specs",
??????????? "destination": "/workspace/examples/bpnet/specs"
??????? },
??????? {
??????????? "source": "/home/<username>/tlt_cv_samples_vv1.1.0/bpnet/data_pose_config",
??????????? "destination": "/workspace/examples/bpnet/data_pose_config"
??????? },
??????? {
??????????? "source": "/home/<username>/tlt_cv_samples_vv1.1.0/bpnet/model_pose_config",
??????????? "destination": "/workspace/examples/bpnet/model_pose_config"
??????? }
??? ]
}
確保要裝載的源目錄路徑有效。這會將主機上的路徑 /home/<username>/tlt-experiments 裝載為容器內的路徑 /workspace/tlt-experiments 。它還將下載的規范裝載到主機上,使其成為容器內的路徑 /workspace/examples/bpnet/specs 、 /workspace/examples/bpnet/data_pose_config 和 /workspace/examples/bpnet/model_pose_config 。
通過運行以下命令,確保已安裝所需的依賴項:
# Install requirements pip3 install -r $SAMPLES_DIR/deps/requirements-pip.txt
下載預訓練模型
首先,設置一個 NGC 帳戶,然后下載預訓練模型。目前,只支持 vgg19 主干網。
# Create the target destination to download the model. mkdir -p $LOCAL_EXPERIMENT_DIR/pretrained_vgg19/ ? # Download the pretrained model from NGC ngc registry model download-version nvidia/tlt_bodyposenet:vgg19 \ ??? --dest $LOCAL_EXPERIMENT_DIR/pretrained_vgg19
數據準備
我們以本文中的 COCO ( context 上的公共對象) 2017 數據集為例。下載數據集并按照說明提取:
將 images 目錄解壓到 $LOCAL_DATA_DIR 目錄中,并將注釋解壓到 $LOCAL_DATA_DIR/annotations 中。
要準備用于訓練的數據,必須生成分段掩碼,用于掩蓋未標記人員和 TFR 記錄的丟失,以提供給訓練管道。掩碼文件夾基于 coco_spec.json 文件中提供的路徑[ mask_root_dir_path 目錄是 root_directory_path 的相對路徑, mask_root_dir_path 和 annotation_root_dir_path 也是如此。
# Generate TFRecords for training dataset tlt bpnet dataset_convert \ ??????? -m 'train' \ ??????? -o $DATA_DIR/train \ ??????? --generate_masks \ ??????? --dataset_spec $DATA_POSE_SPECS_DIR/coco_spec.json ? # Generate TFRecords for validation dataset tlt bpnet dataset_convert \ ??????? -m 'test' \ ??????? -o $DATA_DIR/val \ ??????? --generate_masks \ ??????? --dataset_spec $DATA_POSE_SPECS_DIR/coco_spec.json
要將此示例用于自定義數據集,請執行以下操作:
- 以類似于 COCO 數據集的格式準備數據和注釋。
- 在 data \ u pose \ u config 下創建一個數據集規范,類似于 coco \ u spec . json ,其中包括數據集路徑、姿勢配置、遮擋標記約定等。
- 將注釋轉換為 COCO 注釋格式。
有關更多信息,請參閱以下文檔:
列車試驗配置文件
下一步是為培訓配置 spec 文件。實驗規范文件是必不可少的,因為它編譯了實現良好模型所需的所有超參數。 BodyPoseNet 訓練的規范文件配置訓練管道的以下組件:
- Trainer
- Dataloader
- Augmentation
- 標簽處理機
- Model
- Optimizer
您可以在 $SPECS_DIR/bpnet_train_m1_coco.yaml 中找到默認規范文件。我們在規范文件的每個組件上展開,但這里不包括所有參數。有關詳細信息,請參閱 創建列車試驗配置文件 。
培訓師(頂級配置)
頂層實驗配置包括實驗的基本參數;例如,歷元數、預訓練權重、是否加載預訓練圖等。根據 checkpoint_n_epoch 值保存加密的檢查點。下面是一些頂級配置的代碼示例。
checkpoint_dir: /workspace/tlt-experiments/bpnet/models/exp_m1_unpruned checkpoint_n_epoch: 5 num_epoch: 100 pretrained_weights: /workspace/tlt-experiments/bpnet/pretrained_vgg19/tlt_bodyposenet_vvgg19/vgg_19.hdf5 load_graph: False use_stagewise_lr_multipliers: True ...
所有路徑( checkpoint_dir 和 pretrained_weights )都是 Docker 容器的內部路徑。要驗證正確性,請選中 ~/.tlt_mounts.json 。有關這些參數的更多信息,請參閱 身體姿勢訓練器 部分。
Dataloader
本節幫助您定義數據路徑、圖像配置、目標姿勢配置、規范化參數等。 augmentation_config 部分提供了一些動態增強選項。它支持基本的空間增強,例如翻轉、縮放、旋轉和平移,這些都可以在訓練實驗之前配置。 label_processor_config 部分提供了配置地面實況要素圖生成所需的參數。
dataloader: ? batch_size: 10 ? pose_config: ??? target_shape: [32, 32] ??? pose_config_path: /workspace/examples/bpnet/model_pose_config/bpnet_18joints.json ? image_config: ??? image_dims: ????? height: 256 ????? width: 256 ????? channels: 3 ??? image_encoding: jpg ? dataset_config: ??? root_data_path: /workspace/tlt-experiments/bpnet/data/ ??? train_records_folder_path: /workspace/tlt-experiments/bpnet/data ??? train_records_path: [train-fold-000-of-001] ??? dataset_specs: ????? coco: /workspace/examples/bpnet/data_pose_config/coco_spec.json ? normalization_params: ??? ... ? augmentation_config: ??? spatial_augmentation_mode: person_centric ??? spatial_aug_params: ????? flip_lr_prob: 0.5 ????? flip_tb_prob: 0.0 ????? ... ? label_processor_config: ??? paf_gaussian_sigma: 0.03 ??? heatmap_gaussian_sigma: 7.0 ??? paf_ortho_dist_thresh: 1.0
target_shape值取決于image_dims和模型步幅值(target_shape=input_shape/model stride)。當前模型的步幅為 8 。- 確保使用與
dataset_spec中的root_directory_path相同的root_data_path值。dataset_spec中的掩碼和圖像數據目錄相對于root_data_path。 - 所有路徑,包括
pose_config_path、dataset_config和dataset_specs,都是 Docker 的內部路徑。 - 支持多種
spatial_augmentation_modes:person_centric:增強是圍繞一個對基本真相感興趣的人。
standard:增強是標準的(即,以圖像中心為中心),并且保留圖像的縱橫比。
standard_with_fixed_aspect_ratio:與標準相同,但縱橫比固定為網絡輸入縱橫比。
有關每個參數的詳細信息,請參閱 Dataloader 部分。
Model
BodyPoseNet 模型可以使用 spec 文件中的 model 選項進行配置。下面是一個示例模型配置,用于實例化基于 VGG19 主干網的自定義模型。
model: ?backbone_attributes: ? ?architecture: vgg ?stages: 3 ?heat_channels: 19 ?paf_channels: 38 ?use_self_attention: False ?data_format: channels_last ?use_bias: True ?regularization_type: l1 ?kernel_regularization_factor: 5.0e-4 ?bias_regularization_factor: 0.0 ?...
網絡中用于姿勢估計的總階段數(細化階段+ 1 )由 stages 參數捕獲,該參數取任何值>= 2 。我們建議在修剪前訓練網絡時使用 L1 正則化器,因為 L1 正則化使修剪網絡權重更容易。有關模型中每個參數的詳細信息,請參閱 Model 部分。
優化
本節介紹如何配置優化器和學習速率計劃:
optimizer: ? __class_name__: WeightedMomentumOptimizer ? learning_rate_schedule: ??? __class_name__: SoftstartAnnealingLearningRateSchedule ??? soft_start: 0.05 ??? annealing: 0.5 ??? base_learning_rate: 2.e-5 ??? min_learning_rate: 8.e-08 ? momentum: 0.9 ? use_nesterov: False
默認的 base_learning_rate 是為單個 GPU 訓練設置的。要使用多 GPU 訓練,可能需要修改“學習率”值以獲得類似的精度。在大多數情況下,將學習率提高一倍 $NUM_GPUS 將是一個良好的開端。例如,如果您使用兩個 GPU ,請在一個 GPU 設置中使用 2 * base_learning_rate ,如果您使用四個 GPU ,請使用 4 * base_learning_rate 。有關模型中每個參數的詳細信息,請參閱 Optimizer 部分。
訓練
在完成生成 TFRecords 和 mask 的步驟并設置了一個 train 規范文件之后,現在就可以開始訓練 body pose estimation 網絡了。使用以下命令啟動培訓:
tlt bpnet train -e $SPECS_DIR/bpnet_train_m1_coco.yaml \ ??????????????? -r $USER_EXPERIMENT_DIR/models/exp_m1_unpruned \ ??????????????? -k $KEY \ ??????????????? --gpus $NUM_GPUS
使用更多 GPU 進行培訓可以使網絡更快地接收更多數據,從而在開發過程中節省寶貴的時間。 TLT 支持多 GPU 訓練,因此可以使用多個 GPU 并行訓練模型。我們建議使用四個或更多的 GPU 來訓練模型,因為一個 GPU MIG ht 需要幾天才能完成。訓練時間大致減少了一個系數 $NUM_GPUS 。確保根據 Optimizer 一節中描述的線性縮放方法相應地更新學習速率。
BodyPoseNet 支持從檢查點重新啟動。如果訓練作業過早終止,只需重新運行相同的命令,就可以從上次保存的檢查點恢復訓練。重新啟動培訓時,請確保使用相同數量的 GPU 。
評估
從配置推斷和評估規范文件開始。下面的代碼示例是一個示例規范:
model_path: /workspace/tlt-experiments/bpnet/models/exp_m1_unpruned/bpnet_model.tlt
train_spec: /workspace/examples/bpnet/specs/bpnet_train_m1_coco.yaml
input_shape: [368, 368]
# choose from: {pad_image_input, adjust_network_input, None}
keep_aspect_ratio_mode: adjust_network_input
output_stage_to_use: null
output_upsampling_factor: [8, 8]
heatmap_threshold: 0.1
paf_threshold: 0.05
multi_scale_inference: False
scales: [0.5, 1.0, 1.5, 2.0]
此處的 input_shape 值可以不同于用于培訓的 input_dims 值。 multi_scale_inference 參數可在提供的比例上啟用多比例優化。因為您使用的是步幅 8 的模型, output_upsampling_factor 設置為 8 。
為了使評估與自底向上的人體姿勢估計研究保持一致,有兩種模式和規范文件來評估模型:
$SPECS_DIR/infer_spec.yaml:單刻度,非嚴格輸入。此配置對輸入圖像進行單比例推斷。通過固定網絡輸入的一側(高度或寬度),并調整另一側以匹配輸入圖像的縱橫比,來保持輸入圖像的縱橫比。$SPECS_DIR/infer_spec_refine.yaml:多尺度、非嚴格輸入。此配置對輸入圖像進行多尺度推斷。電子秤是可配置的。
還有一種模式主要用于驗證最終導出的 TRT 模型。在后面的章節中使用這個。
$SPECS_DIR/infer_spec_strict.yaml:單刻度,嚴格輸入。此配置對輸入圖像進行單比例推斷。當 TRT 模型的輸入尺寸固定時,根據需要在側面填充圖像以適應網絡輸入尺寸,從而保留輸入圖像的縱橫比。
--model_filename 參數重寫推理規范文件中的 model_path 變量。
要計算模型,請使用以下命令:
# Single-scale evaluation tlt bpnet evaluate --inference_spec $SPECS_DIR/infer_spec.yaml \ ?????????????????? --model_filename $USER_EXPERIMENT_DIR/models/exp_m1_unpruned/$MODEL_CHECKPOINT \ ?????????????????? --dataset_spec $DATA_POSE_SPECS_DIR/coco_spec.json \ ?????????????????? --results_dir $USER_EXPERIMENT_DIR/results/exp_m1_unpruned/eval_default \ ?????????????????? -k $KEY
模型驗證
現在您已經訓練了模型,運行推斷并驗證預測。要使用 TLT 直觀地驗證模型,請使用 tlt bpnet inference 命令。該工具支持對 .tlt 模型和 TensorRT .engine 模型運行推理。它在 detections.json 中生成帶注釋的圖像,在這些圖像上渲染骨架,并逐幀序列化關鍵點標簽和元數據。例如,要使用經過訓練的 .tlt 模型運行推理,請運行以下命令:
tlt bpnet inference --inference_spec $SPECS_DIR/infer_spec.yaml \ ??????????????????? --model_filename $USER_EXPERIMENT_DIR/models/exp_m1_unpruned/$MODEL_CHECKPOINT \ ?? ?????????????????--input_type dir \ ??????????????????? --input $USER_EXPERIMENT_DIR/data/sample_images \ ??????????????????? --results_dir $USER_EXPERIMENT_DIR/results/exp_m1_unpruned/infer_default \ ??????????????????? --dump_visualizations \ ?????????? ?????????-k $KEY
圖 1 顯示了原始圖像的一個示例,圖 2 顯示了渲染姿勢結果的輸出圖像。如您所見,該模型對不同于 COCO 訓練數據的圖像具有魯棒性。


結論
在這篇文章中,您學習了如何使用 TLT 中的 BodyPoseNet 應用程序訓練身體姿勢模型。這篇文章展示了從 NGC 獲取一個帶有預訓練主干的開源 COCO 數據集,用 TLT 訓練一個模型。要優化用于推理和部署的訓練模型,請參見 二維姿態估計模型的訓練與優化,第 2 部分 。
有關更多信息,請參閱以下參考資料:
?





