本系列的第一篇文章介紹了在 NVIDIA 遷移學習工具箱中使用開源 COCO 數據集和 BodyPoseNet 應用程序的 如何訓練二維姿態估計模型 。
在本文中,您將學習如何在 NVIDIA 遷移學習工具箱中優化姿勢估計模型。它將引導您完成模型修剪和 INT8 量化的步驟,以優化用于推理的模型。
模型優化和導出
本節介紹模型優化和導出的幾個主題:
- 修剪
- INT8 量化
- 提高速度和準確性的最佳實踐
修剪
BodyPoseNet 支持模型修剪以刪除不必要的連接,從而將參數數量減少一個數量級。這將產生一個優化的模型體系結構。
修剪模型
要修剪模型,請使用以下命令:
tlt bpnet prune -m $USER_EXPERIMENT_DIR/models/exp_m1_unpruned/bpnet_model.tlt \
??????????????? -o $USER_EXPERIMENT_DIR/models/exp_m1_pruned/bpnet_model.pruned-0.05.tlt \
??????????????? -eq union \
??????????????? -pth 0.05 \
??????????????? -k $KEY
通常,您只需調整 -pth (閾值)以進行精度和模型大小的權衡。對于一些內部研究,我們注意到 pth 值介于[0 . 05 , 3 . 0]之間是 BodyPoseNet 模型的良好起點。
重新訓練修剪模型
在模型被刪減之后,由于一些以前有用的權值可能已經被刪除,因此 MIG 的精度可能會略有下降。為了重新獲得準確度,我們建議在相同的數據集上重新訓練這個修剪過的模型。您可以按照 列車試驗配置文件 部分中的相同說明進行操作。現在主要的更改是指定 pretrained_weights 作為修剪模型的路徑,并啟用 load_graph 。因為模型是用剪枝的模型權重初始化的,所以模型收斂得更快。
# Retraining using the pruned model as model graph
tlt bpnet train -e $SPECS_DIR/bpnet_retrain_m1_coco.yaml \
??????????????? -r $USER_EXPERIMENT_DIR/models/exp_m1_retrain \
??????????????? -k $KEY \
??????????????? --gpus $NUM_GPUS
您可以按照 Evaluation 和 模型驗證 部分中的類似說明來評估和驗證修剪后的模型。在用 pth 0.05 重新訓練修剪后的模型之后,您可以觀察到多尺度推理的精度為 56 . 1% 的 AP 。以下是 COCO 驗證集的指標:
Average Precision? (AP) @[ IoU=0.50:0.95 | area=?? all | maxDets= 20 ] = 0.561
Average Precision? (AP) @[ IoU=0.50????? | area=?? all | maxDets= 20 ] = 0.776
Average Precision? (AP) @[ IoU=0.75????? | area=?? all | maxDets= 20 ] = 0.609
Average Precision? (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.567
Average Precision? (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.556
...
導出. etlt 模型
推理吞吐量和創建有效模型的速度是部署深度學習應用程序的兩個關鍵指標,因為它們直接影響到上市時間和部署成本。 TLT 包含一個 export 命令,用于導出和準備 TLT 模型以進行部署。
模型將導出為. etlt (加密的 TLT )文件。 TLT CV 推斷可以使用該文件,它解密模型并將其轉換為 TensorRT 引擎。導出模型將訓練過程與推理分離,并允許轉換到 TLT 環境之外的 TensorRT 引擎 TensorRT 引擎特定于每個硬件配置,應該為每個獨特的推理環境生成。下面的代碼示例顯示了經過修剪、重新訓練的模型的導出。
tlt bpnet export -m $USER_EXPERIMENT_DIR/models/exp_m1_retrain/bpnet_model.tlt \
???????????????? -e $SPECS_DIR/bpnet_retrain_m1_coco.yaml \
???????????????? -o $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.etlt \
??????? ?????????-k $KEY \
???????????????? -t tfonnx
export 命令可以選擇生成校準緩存,以便以 INT8 精度運行推斷。這將在后面的章節中詳細描述。
INT8 量化
BodyPoseNet 模型支持 TensorRT 中的 int8 推理模式。為此,首先對模型進行校準,以運行 8 位推斷。要校準模型,需要一個目錄,其中包含用于校準的一組采樣圖像。
我們提供了一個助手腳本,可以解析注釋并根據指定的標準(如圖像中的人數、每人的關鍵點數量等)隨機抽取所需數量的圖像。
# Number of calibration samples to use
export NUM_CALIB_SAMPLES=2000
?
python3 sample_calibration_images.py \
??? -a $LOCAL_EXPERIMENT_DIR/data/annotations/person_keypoints_train2017.json \
??? -i $LOCAL_EXPERIMENT_DIR/data/train2017/ \
??? -o $LOCAL_EXPERIMENT_DIR/data/calibration_samples/ \
??? -n $NUM_CALIB_SAMPLES \
??? -pth 1 \
??? --randomize
生成 INT8 校準緩存和引擎
下面的命令將經過修剪、重新訓練的模型導出為. etlt 格式,執行 INT8 校準,并為當前硬件生成 INT8 校準緩存和 TensorRT 引擎。
# Set dimensions of desired output model for inference/deployment
export IN_HEIGHT=288
export IN_WIDTH=384
export IN_CHANNELS=3
export INPUT_SHAPE=288x384x3
# Set input name
export INPUT_NAME=input_1:0
?
tlt bpnet export \
??? -m $USER_EXPERIMENT_DIR/models/exp_m1_retrain/bpnet_model.tlt \
??? -o $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.etlt \
??? -k $KEY \
??? -d $IN_HEIGHT,$IN_WIDTH,$IN_CHANNELS \
??? -e $SPECS_DIR/bpnet_retrain_m1_coco.yaml \
??? -t tfonnx \
??? --data_type int8 \
??? --engine_file $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.$IN_HEIGHT.$IN_WIDTH.int8.engine \
??? --cal_image_dir $USER_EXPERIMENT_DIR/data/calibration_samples/ \
??? --cal_cache_file $USER_EXPERIMENT_DIR/models/exp_m1_final/calibration.$IN_HEIGHT.$IN_WIDTH.bin? \
??? --cal_data_file $USER_EXPERIMENT_DIR/models/exp_m1_final/coco.$IN_HEIGHT.$IN_WIDTH.tensorfile \
??? --batch_size 1 \
??? --batches $NUM_CALIB_SAMPLES \
??? --max_batch_size 1 \
??? --data_format channels_last
確保 --cal_image_dir 中提到的目錄中至少有( batch_size * batches )個圖像。要為當前硬件生成 F16 引擎,請將 --data_type 指定為 FP16 。有關此處使用的參數的更多信息,請參閱 INT8 模型概述 。
評估 TensorRT 發動機
此評估主要用于對導出的 TRT ( INT8 / FP16 )模型進行健全性檢查。這并不能反映模型的真實準確性,因為這里的輸入縱橫比可能與驗證集中圖像的縱橫比有很大差異。這套設備有一組不同分辨率的圖像。在這里,您保留嚴格的輸入分辨率,并填充圖像以重新訓練縱橫比。因此,這里的精度 MIG ht 根據縱橫比和您選擇的網絡分辨率而變化。
您也可以在嚴格模式下運行 .tlt 模型的評估,以便與 INT8 / FP16 / FP32 模型的精度進行比較,以確定精度是否下降。在這一步中,與 .tlt 型號相比, FP16 和 FP32 型號的精度應無下降或下降最小。 INT8 模型的精度與 .tlt 模型相似(或在 2-3%AP 范圍內可比)。
您可以按照 Evaluation 和 模型驗證 部分中的類似說明來評估和驗證模型。一個改變就是你現在使用 $SPECS_DIR/infer_spec_retrained_strict.yaml as inference_spec 和要使用的模型將是經過修剪的 TLT 模型、 INT8 引擎或 FP16 引擎。
可部署模型導出
在驗證了 INT8 / FP16 / FP32 模型之后,您必須重新導出該模型,以便它可以用于在 TLT-CV 推理等推理平臺上運行。您使用的準則與前幾節中相同,但必須將 --sdk_compatible_model 標志添加到 export 命令中,這將向模型中添加一些不可訓練的后期處理層,以實現與推理管道的兼容性。重用前面步驟中生成的校準張量文件( cal_data_file )以保持一致,但必須重新生成 cal_cache_file 和 .etlt 模型。
tlt bpnet export
??? -m $USER_EXPERIMENT_DIR/models/exp_m1_retrain/bpnet_model.tlt
??? -o $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.deploy.etlt
??? -k $KEY
??? -d $IN_HEIGHT,$IN_WIDTH,$IN_CHANNELS
??? -e $SPECS_DIR/bpnet_retrain_m1_coco.txt
??? -t tfonnx
??? --data_type int8
??? --cal_image_dir $USER_EXPERIMENT_DIR/data/calibration_samples/
??? --cal_cache_file $USER_EXPERIMENT_DIR/models/exp_m1_final/calibration.$IN_HEIGHT.$IN_WIDTH.deploy.bin
??? --cal_data_file $USER_EXPERIMENT_DIR/models/exp_m1_final/coco.$IN_HEIGHT.$IN_WIDTH.tensorfile
??? --batch_size 1
??? --batches $NUM_CALIB_SAMPLES
??? --max_batch_size 1
??? --data_format channels_last
??? --engine_file $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.$IN_HEIGHT.$IN_WIDTH.int8.deploy.engine
??? --sdk_compatible_model
提高速度和準確性的最佳實踐
在本節中,我們將介紹一些用于提高模型性能和準確性的最佳實踐。
部署的網絡輸入分辨率
模型的網絡輸入分辨率是決定自底向上方法精度的主要因素之一。自下而上的方法必須一次提供整個圖像,從而使每個人的分辨率更小。因此,更高的輸入分辨率產生更好的精度,特別是在中小型人員的圖像比例方面。但是,隨著輸入分辨率的提高, CNN 的運行時間也會提高。因此,準確度/運行時權衡應該由目標用例的準確度和運行時需求來決定。
如果您的應用程序涉及到一個或多個靠近相機的人的姿勢估計,使得該人的比例相對較大,那么您可以使用較小的網絡輸入高度。如果你的目標是為相對規模較小的人使用網絡,比如擁擠的場景,你需要更高的網絡輸入高度。凍結網絡高度后,可以根據部署期間使用的輸入數據的縱橫比來決定寬度。
不同分辨率的精度/運行時變化說明
這些是筆記本中使用的默認體系結構和規范的近似運行時和精度。對架構或參數的任何更改都會產生不同的結果。這主要是為了更好地了解哪種解決方案適合您的需要。
| Input Resolution | Precision | Runtime (GeForce RTX 2080) |
Runtime (Jetson AGX) |
? |
| 320×448 | INT8 | 1.80ms | 8.90ms | ? |
| 288×384 | INT8 | 1.56ms | 6.38ms | ? |
| 224×320 | INT8 | 1.33ms | 5.07ms | ? |
從 224 英鎊開始,預計 area=medium 類別的應付賬款將增長 7-10% × 320 至 288 × 384 和額外的 7-10%AP 當你選擇 320 × 448 .在這些分辨率中, area=large 的精度幾乎保持不變,所以如果需要的話,可以選擇較低的分辨率。根據 COCO 關鍵點評估 , medium 區域被定義為居住面積在 36 ^ 2 到 96 ^ 2 之間的人。居住面積在 36 ^ 2 到 96 ^ 2 之間的人被歸類為 large 。
我們使用默認大小 288 × 384 在這個崗位上。要使用不同的分辨率,需要進行以下更改:
- 用所需形狀更新 INT8 量化 中提到的 env 變量。
- 更新
infer_spec_retrained_strict.yaml中的input_shape,這使您能夠對導出的 TRT 模型進行健全性評估。默認設置為[288384]。
高度和寬度應為 8 的倍數,最好為 16 / 32 / 64 的倍數。
網絡中的細化階段數
圖 1 顯示了模型體系結構包括細化階段,每個階段細化前一階段的結果。您可以使用 model 部分下的 stages 參數來配置它 stages 包括初始預測階段和細化階段。我們建議使用最少一個細化階段,最多六個細化階段,對應于[2 , 7]范圍內的 stages 。
當您使用更多的細化階段時,這可能有助于提高準確性,但請記住,這將導致推理時間的增加。在這篇文章中,我們使用了默認的兩個細化階段( stages=3 ),這是為了獲得最佳的性能和準確性而進行的調整。要獲得更快的性能,請使用 stages=2 。
修剪和正則化
修剪有助于顯著減少參數數量,并在保持精度的同時最大限度地提高速度,或者以精度下降為代價。剪枝閾值越高,模型越小,推理速度越快,但 MIG ht 會導致精度下降。
要使用的閾值取決于數據集。如果再培訓的準確性是好的,你可以增加這個值得到更小的模型。否則,請降低此值以獲得更好的精度。我們建議使用 prune-retain 循環進行迭代,直到您滿意精度和速度的折衷。在修剪之前訓練模型時,也可以使用更高的 L1 正則化權重。它會將更多的權重推向零,從而更容易刪減網絡權重。
模型精度和性能
在本節中,我們將深入探討模型的準確性和性能,并將其與最新技術和跨平臺進行比較。
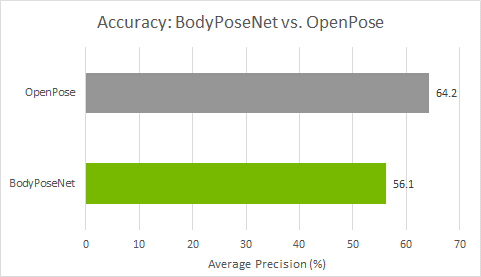
與 OpenPose 的比較
我們將此方法與 OpenPose 進行比較,因為此方法遵循類似的單次自底向上方法。圖 4 顯示,與 OpenPose 模型相比,您實現了更好的精度性能折衷。準確率較低約 8%AP ,而您實現了接近 9 倍的加速模型訓練與默認參數在這篇文章中提供。
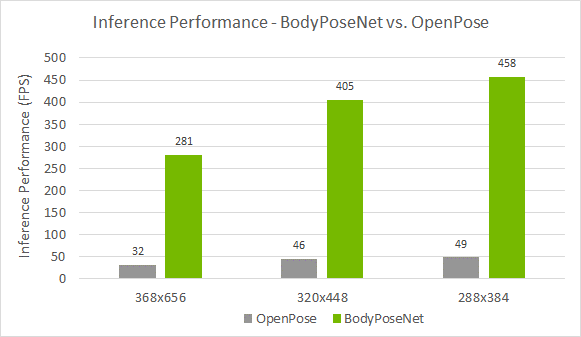
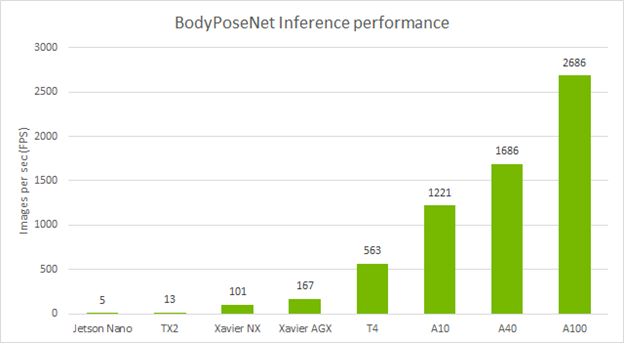
跨設備的獨立性能
下表顯示了使用默認參數使用 TLT 訓練的 BodyPoseNet 模型的推理性能。我們使用 TensorRT 的 trtexec 命令分析了模型推理。
結論
在本文中,您學習了如何使用 TLT 中的 BodyPoseNet 應用程序優化身體姿勢模型。文章展示了如何使用一個開源的 COCO 數據集和 NGC 的一個預訓練主干來訓練和優化一個 TLT 模型。有關模型部署的信息,請參閱 TLT CV 推斷管道 快速啟動腳本 和 Deployment 說明。
與 OpenPose 相比,使用此模型,您的推理性能可以提高 9 倍,甚至可以幫助您在嵌入式設備上實現實時性能。修剪加上 INT8 精度可以在邊緣設備上提供最高的推理性能。
有關更多信息,請參閱以下參考資料:
?