
隨著人工智能和模擬的融合加速了科學發現,需要一種方法來衡量和排名構建世界超級計算機人工智能模型的速度和吞吐量。 MLPerfHPC 現在已經進入第三次迭代,它已經成為使用傳統上在超級計算機上執行的工作負載來衡量系統性能的行業標準。
同行評審的行業標準基準是評估 HPC 平臺的關鍵工具, NVIDIA 相信,獲得可靠的性能數據將有助于指導未來 HPC 架構師的設計決策。 MLPerf 基準測試由 MLCommons 開發,使組織能夠在傳統上在超級計算機上執行的一組重要工作負載上評估 AI 基礎設施的性能。
MLPerfHPC 基準測試測量了三種采用機器學習技術的高性能仿真的訓練時間和吞吐量。
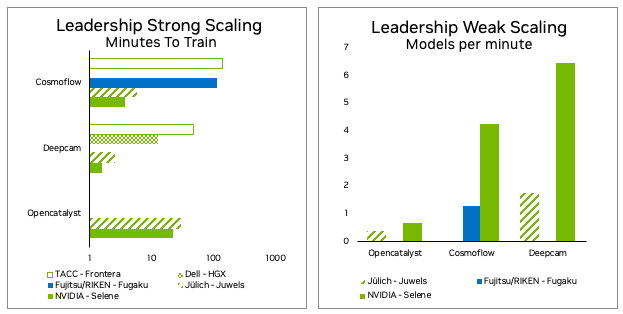
這篇文章介紹了 NVIDIA MLPerf 團隊為優化每個基準和度量以獲得最佳性能所采取的步驟。除了 MLPerf HPC v1.0 中的優化之外,我們還將重點關注 MLPerfHPC v2.0 中的優化。
CosmoFlow
CosmoFlow 訓練應用程序基準測試的每個實例加載約 8 TB 的訓練數據和約 1 TB 的驗證數據。這些包括 512K 個訓練樣本和 64K 個驗證樣本。每個示例都有一個 16 MB 的數據文件和一個 144 個字符的小標簽文件。總共有 100 多萬個小文件需要在培訓開始之前加載到節點本地非易失性內存快車( NVMe )中。
在 MLPerf HPC v1.0 中,這導致數據分級對于強規模和弱規模的情況都需要大量時間。對于弱規模的情況,每個實例從文件系統加載超過 100 萬個文件會給共享磁盤系統帶來額外的壓力。
對于用于弱規模提交的實例數量,這會導致相對于實例數量的分段性能的非線性降級。這些問題以多種方式解決,概述如下。
NVMe 上的數據暫存
對于 NVIDIA MLPerf HPC v1.0 提交的單個強訓練實例分析表明,僅使用了 Selene Lustre 文件系統最大理論讀取帶寬的一小部分。轉移輸入數據集時,節點上的存儲網絡接口卡( NIC )也是如此。
在培訓的階段階段,分配的 CPU 資源完全用于從共享文件系統向節點本地 NVMe 存儲源數據。增加專用于分段的線程,并并行分段訓練和驗證數據,將分段時間減少了約 75% 。這相當于分段的速度提高了約 4 倍,并使端到端的總時間減少了 40% ,從而實現了強大的規模。
數據壓縮
加載許多小文件本質上是低效的。在 CosmoFlow 中,有超過 100 萬個文件,每個文件有 144 個字節。為了進一步提高暫存性能,將關聯的數據和標簽提前脫機合并到一個壓縮文件中。
與從磁盤轉移數據并行,文件將在本地解壓縮到計算節點磁盤上。這將從磁盤讀取的文件數量減少了 50% ,從磁盤傳輸的總數據減少了約 85% ,最終為強規模場景提供了額外的 13% 的暫存速度。這將使大規模提交的總體培訓時間提高 7% 。
這種方法實現了超過 900 GB / s 的讀取帶寬,用于大規模場景的數據分段。
在運行多個實例時增加有效帶寬
有關其他算法詳細信息,請參閱 2021 MLPerf HPC 提交文件 MLPerf HPC v1.0: Deep Dive into Optimizations Leading to Record-Setting NVIDIA Performance 中的 DeepCam 解釋。
當同時運行多個實例時,對于弱伸縮性,每個實例必須在其本地節點上存儲訓練和驗證數據的副本。今年, NVIDIA 提交的文件為 CosmoFlow 實施了分布式分級機制。
所有節點,無論與哪個實例關聯,都會從共享文件系統加載一部分總數據( 1 / N ,其中 N 是節點總數,在本例中為 512 )。考慮到已經討論過的優化,這只需要幾秒鐘。
然后,每個節點使用MPI_Allgather將從遠程存儲加載的數據分發給需要數據的其他節點。這種分布發生在較高帶寬上 InfiniBand Fabric 。換句話說,通過此優化,以前通過存儲網絡進行的大部分數據傳輸被卸載到 InfiniBand Fabric 。由于分布了分段,對于弱規模場景,分段時間隨實例數量(至少多達 128 個實例)線性擴展。
對于 1.0 版的提交,運行了 32 個實例,每個實例的數據量約為 9 TB 。這需要 10.76 分鐘才能獲得約 460 GB / s 的有效帶寬。
在今年的提交中,運行了 128 個實例,每個實例的數據量約為 9 TB ,總的數據量需要 6.7 分鐘。這意味著在 1.6 倍的時間內將輸入數據分段為 4 倍的實例數,從而產生約 2900 GB / s 的有效帶寬,有效帶寬增加 6.5 倍。有效帶寬假設從文件系統轉移的總數據量與給定數量實例的非分布式算法相同。
較小的實例大小用于弱規模訓練
所有的分段改進都使單個實例的大小得以減小,從而實現了弱擴展(因此并行實例的數量更大),而在實施優化之前存在的存儲訪問瓶頸是不可能實現的。在 v1.0 中, 32 個實例(每個實例有 128 個 GPU )導致了分段時間的非線性擴展。實例數量的增加導致了轉移時間的超線性增加。
如果沒有對許多實例進行有效分段的改進,分段時間將繼續隨著實例的數量呈超線性增長,導致數據分段所花費的時間比實際訓練的時間更長。
通過上述優化,弱規模提交的實例數量從 32 個增加到 128 個,每個實例使用四個節點,而不是 MLPerf HPC v1.0 中的 16 個節點。在 v2.0 中,分段在更短的時間內完成,同時將弱規模提交同時運行的模型數量增加了 4 倍。
CUDA 圖形和圖形捕獲
CUDA 圖允許啟動由一系列內核組成的單個圖,而不是從 CPU 向 GPU 單獨啟動每個內核。該特性最大限度地減少了 CPU 在每次迭代中的參與,通過最小化延遲(尤其是對于強縮放場景)顯著提高了性能。
CUDA 圖形支持最近添加到 PyTorch 中。有關詳細信息,請參見 Accelerating PyTorch with CUDA Graphs 。 PyTorch 中的 CUDA 圖形支持導致 CosmoFlow 在強縮放場景中的端到端性能提高約 15% ,這對延遲和抖動最為敏感。
OpenCatalyst
GPU 負載平衡
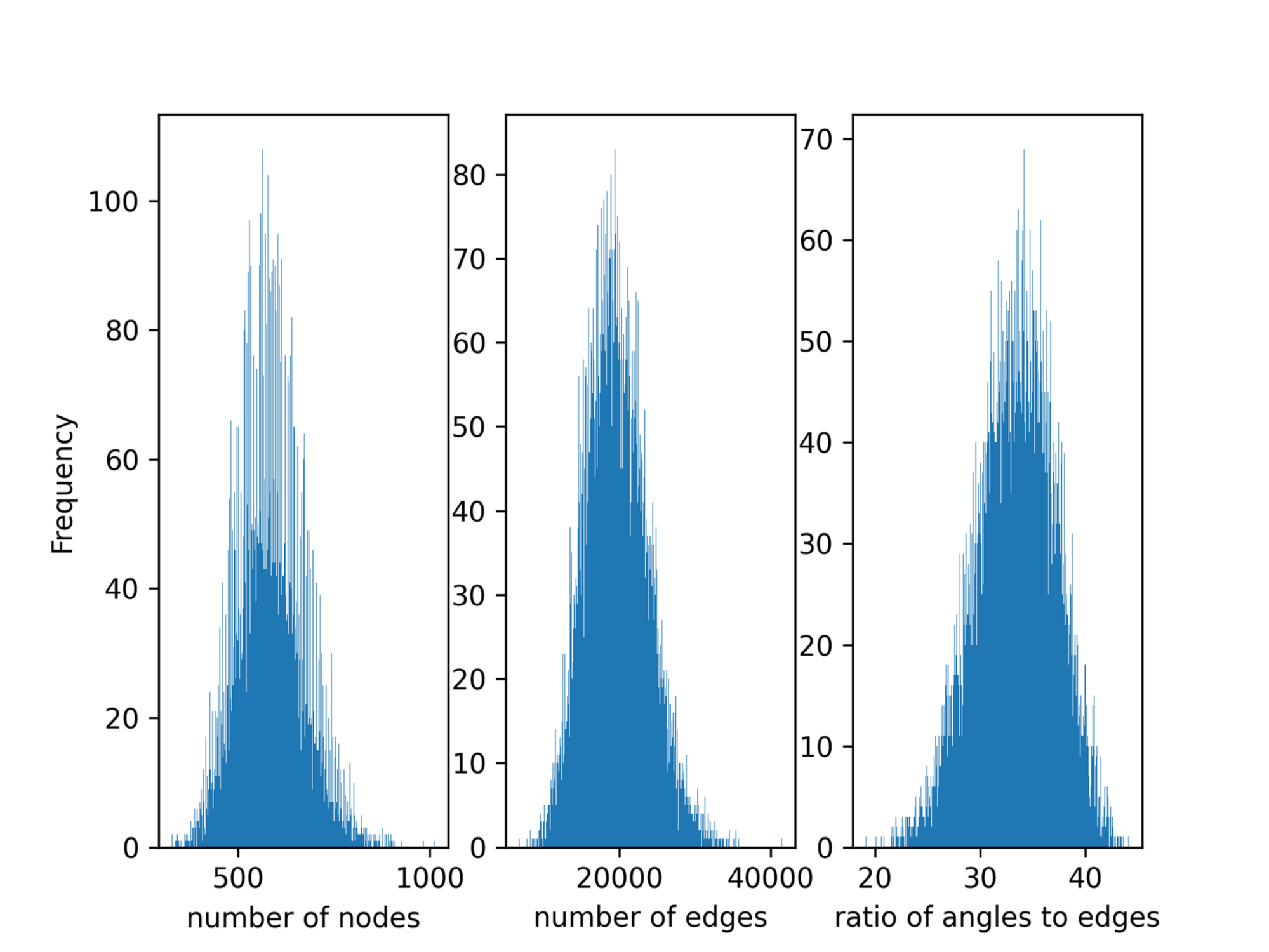
數據并行在每個 GPU 之間平均分割全局批處理。然而,默認情況下,數據并行任務分區不考慮批處理中的負載不平衡。由于不同分子的原子數、邊緣數和從分子中獲得的圖中的三重態有很大差異(圖 2 ),因此一批樣品之間的 Open Catalyst 中存在負載不平衡。
這種不平衡導致多 GPU 設置中的大同步開銷。對于強縮放場景,這導致 32% 的計算時間被浪費。勞倫斯伯克利國家實驗室( LBNL )在 MLPerf HPC v1.0 中引入了一種算法來平衡 GPU 上的負載,這在本輪 NVIDIA 提交的文件中被采用。
該算法首先對訓練數據進行預處理,以獲得每個樣本的邊緣數。在采樣階段,給每個 GPU 局部樣本的索引,并執行全局ALLgather以獲得全局樣本的索引。
然后,全局樣本按照邊的數量進行排序,并分布在工人之間,以便每個 GPU 處理盡可能接近相等數量的邊。該算法很好地平衡了工作負載,但引入了很大的通信開銷,特別是當應用程序擴展到更多時 GPU 。這與 LBNL 在 v1.0 中提交的 Open Catalyst 中使用的算法相同。
NVIDIA 還改進了 v2.0 中的采樣功能。負載平衡采樣器通過在開始時獲取全局批處理中所有樣本的索引,避免了全局( GPU 間)通信。如前所述,樣本按邊數排序,并劃分為不同的桶,以便每個桶具有相同的近似邊數。最后,每個工作人員都會得到一個包含與其全局排名相對應的樣本索引的桶。
使用 nvFuser 和 cuGraph 操作的內核融合
從 MLCommons GitHub 下載的原始 OpenCatalyst 模型中有超過 10K 個內核。 PyTorch 的深度學習編譯器 nvFuser 是一種常見的優化方法,它使用實時( JIT )編譯將多個操作融合到一個內核中。該方法減少了內核數量和全局內存事務。
為了實現這一點, NVIDIA 修改了模型腳本,以在 PyTorch 中啟用 JIT 。優化的融合內核也在cuGraph-ops中實現,通過 RAPIDS framework 暴露。借助nvFuser和cuGraph-ops,內核總數可以減少 90% 以上。
融合小型 GEMM 以提高 GPU 利用率
在原始計算圖中,有許多小的通用矩陣乘法( GEMM ),它們是順序執行的,不能使 GPU 飽和。這些小的 GEMM 操作可以被融合以減少內核的數量并提高 GPU 的利用率。應用了三種 GEMM 融合——填充、配料和水平融合——如下所述。為了實現這些融合,對模型腳本進行了唯一的更改。
Packing – 多個線性層共享相同的輸入。一個大型 GEM 被用來替換一組小型 GEM 。

Batching – 幾個線性層彼此沒有依賴性。這些線性層被捆綁到批處理操作中,以提高并行度。
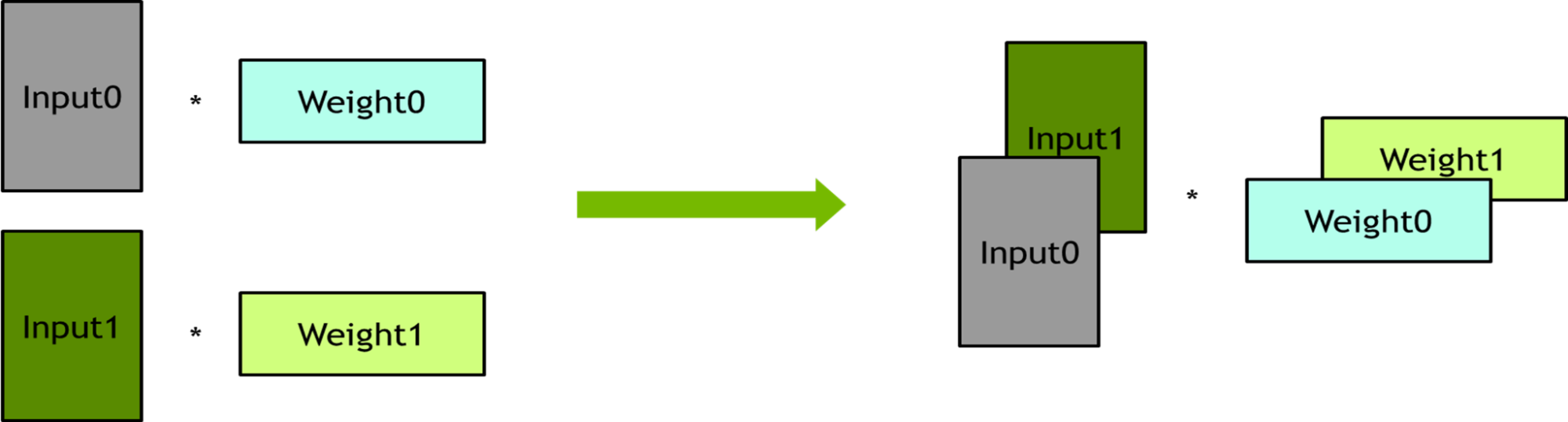
Horizontal fusion –
輸出減少的公式可以表示為w1 x 01 + w2 x 02 + w3 x 03 + w4 x 04 + w5 x 05,正好匹配矩陣的分塊乘法,可以將它們打包在一起。

消除三元組上的冗余計算
在原始計算圖中,每個邊緣特征被擴展為三元組,然后每個三元組執行元素乘法。三元組的數量大約是邊數的 30 倍,這會導致大量的冗余計算。為了去除多余的計算,首先對邊緣特征執行元素乘法,然后將其擴展為執行三元組的邊緣特征。
管道優化
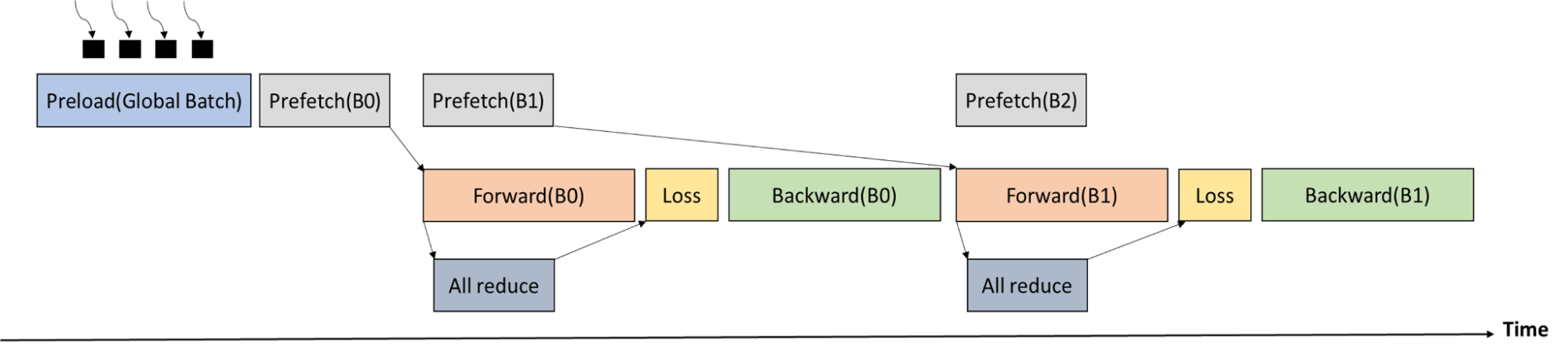
在丟失階段之前,需要在所有工作人員之間進行ALLReduce通信,以獲得當前全局批次中的原子總數。由于前向傳遞的執行時間比ALLReduce的執行時間長,因此可以很好地重疊通信。
圖 6 顯示了培訓過程時間表。全局批處理首先由多個進程加載到 CPU 內存中。Memcpy從 CPU 存儲器到 GPU 存儲器和ALLReduce(以獲得全局批中的原子數)與前向傳遞重疊。
數據暫存
Open Catalyst 基準測試的訓練數據為 300 GB ,一個 DGXA100 節點的系統內存為 2048 GB 和 256 個線程(每個套接字 128 個線程,每個節點兩個套接字)。結果,可以在開始時將整個訓練數據預加載到 CPU 存儲器中。無需在每個訓練步驟中將迷你批次從磁盤加載到 CPU 內存。
為了加速數據預加載, NVIDIA 啟動了 256 個進程,每個進程加載 300 / 256 (~ 1.2 ) GB 的訓練數據集。完成預加載大約需要 10s ~ 15s ,相對于端到端訓練時間而言,這是微不足道的。
深度攝像頭
正在加載數據
以前,透明內存數據加載器利用后臺進程將數據本地緩存在動態隨機存取存儲器( DRAM )中。這會導致較大的開銷,因此重新實現了加載程序以使用線程。
性能先前受到 Python 全局解釋器鎖( GIL )的限制。這次,基于 C ++的 IO 助手類被優化以釋放 GIL 。這種方法允許背景加載與其他 CPU 工作重疊。同樣的優化也應用于分布式數據分級器,以降低擴展分數,將端到端性能提高約 15% 。
完整迭代 CUDA 圖捕獲
與 MLPerf HPC v1.0 相比, CUDA 圖捕獲的范圍擴展到了完全迭代、正向和反向傳遞、優化器和學習速率調度器步驟。為此, NVIDIA APEX 包中的無同步優化器 FusedMixedPrecisionLAMB 和 DistributedLAMB 用于弱和強縮放基準。
此外,所有 DeepCAM 學習速率調度器都被移植到 GPU 。通過增加 CUDA 圖內執行的計算部分,減少了 CPU 執行可變性引起的設備之間的性能可變性。因此,橫向擴展性能提高。
分布式優化器
為了提高強大的擴展性能,使用了 DistributedLAMB 優化器。該優化器特別適合于小的每 GPU 局部批量大小和大的規模,因為優化器成本在這種設置中更為顯著。 DeepCAM 的端到端性能增量約為 3% 。
cuDNN 內核優化
DeepCAM 具有大量具有不同性能特征的計算內核。雖然 NVIDIA 在 v1.0 中改進了分組卷積的性能,但在 v2.0 中也改進了逐點卷積的性能。它們與分組卷積一起使用,以形成深度方向的可分離卷積。
MLPerf HPC v2.0 最終結果
人工智能正在改變高性能計算的科學方式。每年,都會建立新的、更精確的替代模型,并以足夠的準確度大大超過基于物理的模擬。蛋白質折疊和 OpenFold 、 RoseTTAFold 和 AlphaFold 2 的出現已經被這種基于 AI 的方法徹底改變,使基于蛋白質結構的藥物發現觸手可及。
MLPerfHPC 反映了超級計算行業需要一種客觀的、同行評審的方法來衡量和比較與 HPC 相關的用例的 AI 訓練性能。
自 2021 MLPerf HPC v1.0 提交以來, NVIDIA 已經取得了重大進展。 Selene 超級計算機顯示, NVIDI A A100 Tensor Core GPU 和 NVIDIA DGX-A100 SuperPOD 雖然已使用近三年,但仍然是 HPC 用例及以后 AI 培訓的最佳系統。
有關詳細信息,請參見 MLPerf HPC Benchmarks Show the Power of HPC+AI 。
?






