我之前的介紹文章,“ 更容易介紹 CUDA C ++ ”介紹了 CUDA 編程的基本知識,它演示了如何編寫一個簡單的程序,在內存中分配兩個可供 GPU 訪問的數字數組,然后將它們加在 GPU 上。為此,我向您介紹了統一內存,這使得分配和訪問系統中任何處理器上運行的代碼都可以使用的數據變得非常容易, CPU 或 GPU 。
為此,我向您介紹了統一內存,它可以非常輕松地分配和訪問可由系統中任何處理器、CPU 或 GPU 上運行的代碼使用的數據。
首先,因為 NVIDIA Titan X 和 NVIDIA Tesla P100 等 Pascal GPU 是第一批包含頁面遷移引擎的 GPU,該引擎是統一內存頁面錯誤和頁面遷移的硬件支持。 第二個原因是它提供了一個很好的機會來了解更多關于統一內存的信息。
Fast GPU, Fast Memory… Right?
對! 但是讓我們看看。 首先,我將重新打印在兩個 NVIDIA Kepler GPU 上運行的結果(一個在我的筆記本電腦上,一個在服務器上)。
| ? | Laptop (GeForce GT 750M) | Laptop (GeForce GT 750M) | Server (Tesla K80) | Server (Tesla K80) |
|---|---|---|---|---|
| Version | Time | Bandwidth | Time | Bandwidth |
| 1 CUDA Thread | 411ms | 30.6 MB/s | 463ms | 27.2 MB/s |
| 1 CUDA Block | 3.2ms | 3.9 GB/s | 2.7ms | 4.7 GB/s |
| Many CUDA Blocks | 0.68ms | 18.5 GB/s | 0.094ms | 134 GB/s |
現在讓我們嘗試在基于 Pascal GP100 GPU 的非常快的 Tesla P100 加速器上運行。
> nvprof ./add_grid
...
Time(%) Time Calls Avg Min Max Name
100.00% 2.1192ms 1 2.1192ms 2.1192ms 2.1192ms add(int, float*, float*)
嗯,低于 6 GB/s:比在我的筆記本電腦的基于 Kepler 的 GeForce GPU 上運行要慢。 不過,不要氣餒; 我們可以解決這個問題。 為了理解如何,我將不得不告訴你更多關于統一內存的信息。
下面是參考,這是上次 add_grid.cu 的完整代碼。
#include <iostream>
#include <math.h>
// CUDA kernel to add elements of two arrays
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory -- accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Launch kernel on 1M elements on the GPU
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
分配和初始化內存的代碼在第 19-27 行。
什么是統一內存?
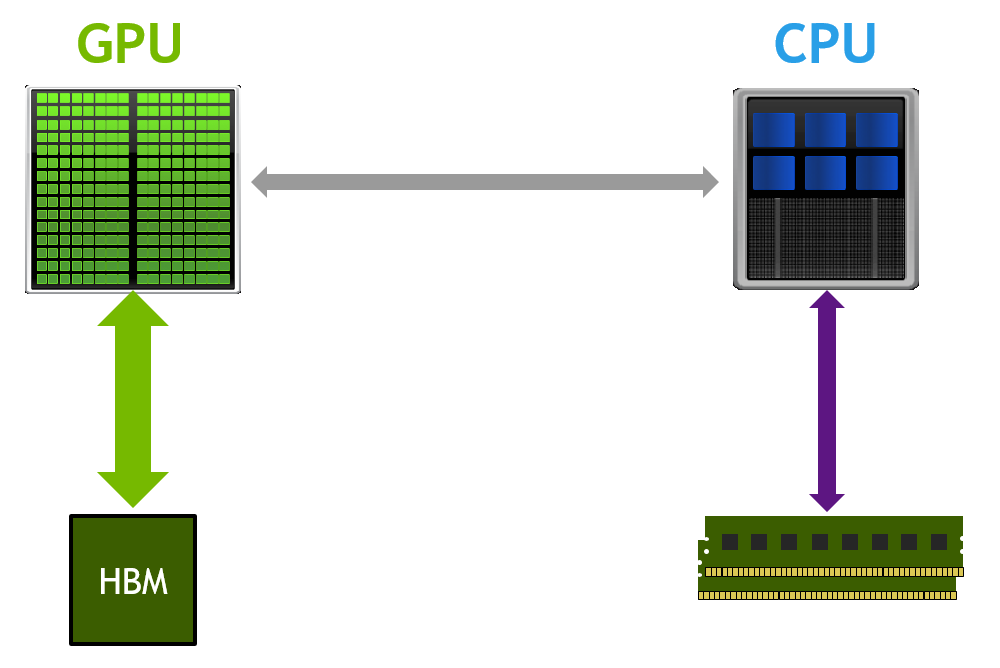
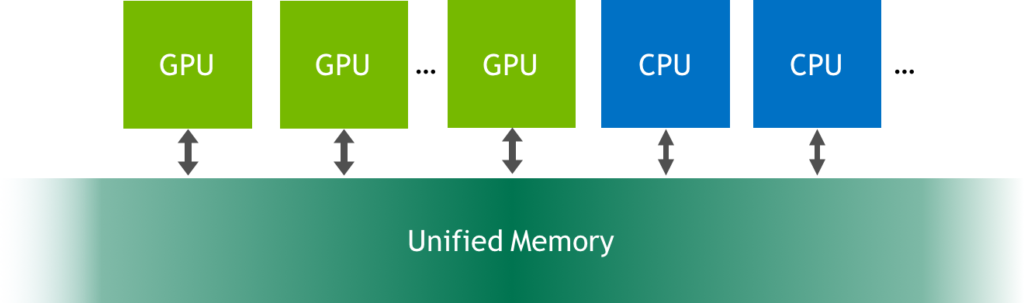
統一內存是可從系統中的任何處理器訪問的單個內存地址空間(參見上圖)。 這種硬件/軟件技術允許應用程序分配可以從 CPU 或 GPU 上運行的代碼讀取或寫入的數據。 分配統一內存就像用調用?cudaMallocManaged()?替換對?malloc()?或?new?的調用一樣簡單,這是一個分配函數,它返回一個可從任何處理器訪問的指針(下文中的 ptr)。
cudaError_t cudaMallocManaged(void** ptr, size_t size);
當在 CPU 或 GPU 上運行的代碼訪問以這種方式分配的數據(通常稱為 CUDA 托管數據)時,CUDA 系統軟件和/或硬件負責將內存頁面遷移到訪問處理器的內存。 這里重要的一點是,Pascal GPU 架構是第一個通過其頁面遷移引擎為虛擬內存頁面錯誤和頁面遷移提供硬件支持的架構。 基于 Kepler 和 Maxwell 架構的舊 GPU 也支持更有限的統一內存形式。
當我在Kepler平臺上調用cudaMallocManaged()時會發生什么?
在具有 pre-Pascal GPU (如?Tesla K80)的系統上,調用?cudaMallocManaged()?會在調用時處于活動狀態的 GPU 設備上分配?size?字節的托管內存。 在內部,驅動程序還為分配覆蓋的所有頁面設置頁表條目,以便系統知道這些頁面駐留在該 GPU 上。
因此,在我們的示例中,在?Tesla K80 GPU(Kepler?架構)上運行時,x 和 y 最初都完全駐留在 GPU 內存中。 然后在從第 6 行開始的循環中,CPU 遍歷兩個數組,將它們的元素分別初始化為?1.0f?和?2.0f。 由于頁面最初駐留在設備內存中,因此對于它寫入的每個數組頁面,CPU 都會發生頁面錯誤,并且 GPU 驅動程序會將頁面從設備內存遷移到 CPU 內存。 循環之后,兩個數組的所有頁面都駐留在 CPU 內存中。
在 CPU 上初始化數據后,程序啟動?add()?內核將 x 的元素添加到 y 的元素中。
add<<<1, 256>>>(N, x, y);
在 pre-Pascal GPU 上,在啟動內核時,CUDA 運行時必須將之前遷移到主機內存或另一個 GPU 的所有頁面遷移回運行內核的設備的設備內存。 由于這些較舊的 GPU 不能出現頁面錯誤,因此所有數據都必須駐留在 GPU 上,以防內核訪問它(即使它不會訪問)。 這意味著每次內核啟動都有潛在的遷移開銷。
這就是我在 K80 或我的 Macbook Pro 上運行程序時發生的情況。 但是請注意,分析器將內核運行時間與遷移時間分開顯示,因為遷移發生在內核運行之前。
==15638== Profiling application: ./add_grid
==15638== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 93.471us 1 93.471us 93.471us 93.471us add(int, float*, float*)
==15638== Unified Memory profiling result:
Device "Tesla K80 (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
6 1.3333MB 896.00KB 2.0000MB 8.000000MB 1.154720ms Host To Device
102 120.47KB 4.0000KB 0.9961MB 12.00000MB 1.895040ms Device To Host
Total CPU Page faults: 51
當我在Pascal平臺上調用cudaMallocManaged()時會發生什么?
在 Pascal 和更高版本的 GPU 上,當?cudaMallocManaged()?返回時,托管內存可能不會被物理分配;它只能在訪問(或預取)時填充。換句話說,頁面和頁表條目可能不會被創建,直到它們被 GPU 或 CPU 訪問。頁面可以隨時遷移到任何處理器的內存,驅動程序采用啟發式方法來維護數據局部性并防止過多的頁面錯誤。 (注意:應用程序可以使用?cudaMemAdvise()?引導驅動程序,并使用?cudaMemPrefetchAsync()?顯式遷移內存,如這篇博文所述)。
與pre-Pascal GPU 不同,Tesla P100 支持硬件頁面錯誤和頁面遷移。因此在這種情況下,運行時不會在運行內核之前自動將所有頁面復制回 GPU。內核在沒有任何遷移開銷的情況下啟動,當它訪問任何缺少的頁面時,GPU 會停止訪問線程的執行,并且頁面遷移引擎會在恢復線程之前將頁面遷移到設備。
這意味著當我在 Tesla P100 (2.1192 ms) 上運行我的程序時,遷移的成本包含在內核運行時間中。在這個內核中,數組中的每一頁都是由 CPU 寫入,然后由 GPU 上的 CUDA 內核訪問,導致內核等待大量的頁面遷移。這就是為什么分析器測量的內核時間在像 Tesla P100 這樣的 Pascal GPU 上更長的原因。讓我們看看 P100 上程序的完整 nvprof 輸出。
==19278== Profiling application: ./add_grid
==19278== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 2.1192ms 1 2.1192ms 2.1192ms 2.1192ms add(int, float*, float*)
==19278== Unified Memory profiling result:
Device "Tesla P100-PCIE-16GB (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
146 56.109KB 4.0000KB 988.00KB 8.000000MB 860.5760us Host To Device
24 170.67KB 4.0000KB 0.9961MB 4.000000MB 339.5520us Device To Host
12 - - - - 1.067526ms GPU Page fault groups
Total CPU Page faults: 36
如您所見,有許多主機到設備的頁面錯誤,降低了 CUDA 內核實現的吞吐量。
我該怎么辦?
在實際應用程序中,GPU 可能會在 CPU 不接觸數據的情況下對數據執行更多計算(可能很多次)。 這段簡單代碼中的遷移開銷是由 CPU 初始化數據而 GPU 只使用一次數據造成的。 有幾種不同的方法可以消除或更改遷移開銷,以更準確地測量vector add內核性能。
- 將數據初始化移動到另一個 CUDA 內核中的 GPU。
- 多次運行內核并查看平均和最小運行時間。
- 在運行內核之前將數據預取到 GPU 內存。
讓我們來看看這三種方法中的每一種。
初始化內核中的數據
如果我們將初始化從 CPU 轉移到 GPU,則添加內核不會出現頁面錯誤。 這是一個用于初始化數據的簡單 CUDA C++ 內核。 我們可以通過啟動這個內核來替換初始化 x 和 y 的主機代碼。
__global__ void init(int n, float *x, float *y) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride) {
x[i] = 1.0f;
y[i] = 2.0f;
}
}
當我這樣做時,我在 Tesla P100 GPU 的配置文件中看到了兩個內核:
==44292== Profiling application: ./add_grid_init
==44292== Profiling result:
Time(%) Time Calls Avg Min Max Name
98.06% 1.3018ms 1 1.3018ms 1.3018ms 1.3018ms init(int, float*, float*)
1.94% 25.792us 1 25.792us 25.792us 25.792us add(int, float*, float*)
==44292== Unified Memory profiling result:
Device "Tesla P100-PCIE-16GB (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
24 170.67KB 4.0000KB 0.9961MB 4.000000MB 344.2880us Device To Host
16 - - - - 551.9940us GPU Page fault groups
Total CPU Page faults: 12
add 內核現在運行得更快:25.8us,相當于近 500 GB/s。 這是計算帶寬的方法。
帶寬 = 字節/秒 = 3 * 4,194,304 bytes * 1e-9 bytes/GB) / 25.8e-6s = 488 GB/s
(要了解如何計算理論和實現的帶寬,請參閱這篇文章。)仍然存在設備到主機頁面錯誤,但這是由于程序末尾的循環檢查 CPU 上的結果。
多次運行
另一種方法是多次運行內核并查看分析器中的平均時間。 為此,我需要修改我的錯誤檢查代碼,以便正確報告結果。 以下是在 Tesla P100 上運行內核 100 次的結果:
==48760== Profiling application: ./add_grid_many
==48760== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 4.5526ms 100 45.526us 24.479us 2.0616ms add(int, float*, float*)
==48760== Unified Memory profiling result:
Device "Tesla P100-PCIE-16GB (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
174 47.080KB 4.0000KB 0.9844MB 8.000000MB 829.2480us Host To Device
24 170.67KB 4.0000KB 0.9961MB 4.000000MB 339.7760us Device To Host
14 - - - - 1.008684ms GPU Page fault groups
Total CPU Page faults: 36
最小內核運行時間僅為 24.5 微秒,這意味著它實現了超過 500GB/s 的內存帶寬。 我還包括了來自?nvprof?的統一內存分析輸出,它顯示了從主機到設備總共 8MB 的頁面錯誤,對應于第一次添加運行時通過頁面錯誤復制到設備的兩個 4MB 數組(x 和 y)。
預獲取
第三種方法是使用統一內存預取在初始化數據后將數據移動到 GPU。 CUDA 為此提供了?cudaMemPrefetchAsync()。 我可以在內核啟動之前添加以下代碼。
// Prefetch the data to the GPU
int device = -1;
cudaGetDevice(&device);
cudaMemPrefetchAsync(x, N*sizeof(float), device, NULL);
cudaMemPrefetchAsync(y, N*sizeof(float), device, NULL);
// Run kernel on 1M elements on the GPU
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
saxpy<<<numBlocks, blockSize>>>(N, 1.0f, x, y);
現在,當我在 Tesla P100 上進行分析時,我得到以下輸出。
==50360== Profiling application: ./add_grid_prefetch
==50360== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 26.112us 1 26.112us 26.112us 26.112us add(int, float*, float*)
==50360== Unified Memory profiling result:
Device "Tesla P100-PCIE-16GB (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
4 2.0000MB 2.0000MB 2.0000MB 8.000000MB 689.0560us Host To Device
24 170.67KB 4.0000KB 0.9961MB 4.000000MB 346.5600us Device To Host
Total CPU Page faults: 36
在這里,您可以看到內核只運行了一次,耗時 26.1us — 與之前顯示的 100 次運行中的最快速度相似。 您還可以看到不再報告任何 GPU 頁面錯誤,并且由于預取,主機到設備的傳輸僅顯示為四個 2MB 傳輸。
現在我們讓它在 P100 上快速運行,讓我們將它添加到上次的結果表中。
| ? | Laptop (GeForce GT 750M) | Laptop (GeForce GT 750M) | Server (Tesla K80) | Server (Tesla K80) | Server (Tesla P100) | Server (Tesla P100) |
|---|---|---|---|---|---|---|
| Version | Time | Bandwidth | Time | Bandwidth | Time | Bandwidth |
| 1 CUDA Thread | 411ms | 30.6 MB/s | 463ms | 27.2 MB/s | NA | NA |
| 1 CUDA Block | 3.2ms | 3.9 GB/s | 2.7ms | 4.7 GB/s | NA | NA |
| Many CUDA Blocks | 0.68ms | 18.5 GB/s | 0.094ms | 134 GB/s | 0.025ms | 503 GB/s |
關于并發的說明
請記住,您的系統有多個處理器同時運行您的 CUDA 應用程序的一部分:一個或多個 CPU 和一個或多個 GPU。即使在我們的簡單示例中,也有一個 CPU 線程和一個 GPU 執行上下文。因此,在訪問任一處理器上的托管分配時,我們必須小心,以確保沒有競爭條件。
無法從計算能力低于 6.0 的 CPU 和 GPU 同時訪問托管內存。這是因為 pre-Pascal GPU 缺乏硬件頁面錯誤,因此無法保證一致性。在這些 GPU 上,當內核運行時從 CPU 進行訪問將導致segmentation fault。
在 Pascal 和更高版本的 GPU 上,CPU 和 GPU 可以同時訪問托管內存,因為它們都可以處理頁面錯誤;但是,由應用程序開發人員來確保不存在由同時訪問引起的競爭條件。
在我們的簡單示例中,我們在內核啟動后調用了?cudaDeviceSynchronize()。這可確保內核在 CPU 嘗試從托管內存指針讀取結果之前運行完成。否則,CPU 可能會讀取無效數據(在 Pascal 和更高版本上),或出現segmentation fault(在pre-Pascal GPU 上)。
統一內存在 Pascal 和更高版本 GPU 上的優勢
從 Pascal GPU 架構開始,統一內存功能通過 49 位虛擬尋址和按需頁面遷移得到顯著改進。 49 位虛擬地址足以讓 GPU 訪問整個系統內存以及系統中所有 GPU 的內存。頁面遷移引擎允許 GPU 線程在非駐留內存訪問時出錯,因此系統可以根據需要將頁面從系統中的任何位置遷移到 GPU 的內存,以進行高效處理。
換句話說,統一內存透明地啟用了超額訂閱 GPU 內存,為任何使用統一內存進行分配的代碼啟用了核外計算(例如?cudaMallocManaged())。無論是在一個 GPU 上還是在多個 GPU 上運行,它都可以“正常工作”而無需對應用程序進行任何修改。
此外,Pascal 和 Volta GPU 支持系統范圍的原子內存操作。這意味著您可以從多個 GPU 對系統中任何位置的值進行原子操作。這對于編寫高效的多 GPU 協作算法很有用。
請求分頁對于以?稀疏?模式訪問數據的應用程序特別有益。在某些應用程序中,事先不知道特定處理器將訪問哪些特定內存地址。如果沒有硬件頁面錯誤,應用程序只能預加載整個陣列,或者承受高延遲的設備外訪問(也稱為“零復制”)的成本。但是頁面錯誤意味著只需要遷移內核訪問的頁面。
下一步?
我希望這篇文章幫助你繼續學習 CUDA 編程,并且你有興趣學習更多,并在你自己的計算中應用 CUDA C ++。如果您有任何問題或意見,請使用下面的評論部分聯系您。
有關統一內存預取和使用提示( cudaMemAdvise() )的更多信息,請參閱文章
在 Pascal 上使用統一內存超出 GPU 內存限制 。如果您想了解使用 cudaMemcpy 和 cudaMemcpy 在 CUDA 中進行顯式內存管理的信息,請參閱以前的文章 CUDA C / C ++的簡單介紹 。
我們計劃用更多的 CUDA 編程材料來跟進這篇文章,但是為了讓你現在忙得不可開交,你可以繼續閱讀一系列比較老的介紹性文章。
- 如何在 CUDA C ++中實現性能度量
- 如何查詢 CUDA C ++中的設備屬性和處理錯誤
- 如何優化 CUDA C ++中的數據傳輸
- 如何在 CUDA C ++中重疊數據傳輸
- 如何在 CUDA C ++中高效訪問全局內存
- 在 CUDA C ++中使用共享內存
- CUDA C ++中的一種高效矩陣轉置
- CUDA C ++中的有限差分方法,第 1 部分
- CUDA C ++中的有限差分方法,第 2 部分
還有一系列的儀器。
你也有興趣從 Udacity 和 NVIDIA 注冊 CUDA 編程在線課程 。
關于 CUDA C ++和其他 GPU 計算主題,這里有很多關于 NVIDIA Parallel Forall 開發者博客 的內容,所以環顧四周!
1從技術上講,這是一種簡化。在帶有 pre-Pascal GPUs 的 multi-GPU 系統上,如果某些 GPUs 禁用了對等訪問,則將分配內存,使其最初駐留在 CPU 上。
2嚴格地說,您可以使用 cudaStreamAttachMemAsync() 將分配的可見性限制到特定的 CUDA 流。這允許驅動程序 MIG 只對附加到啟動內核的流的頁面進行評級。默認情況下,托管分配附加到所有流,因此任何內核啟動都會觸發 MIG 配額。 請閱讀 CUDA 編程指南中的更多內容 。
3 設備屬性 concurrentManagedAccess 說明 GPU 是否支持硬件頁 MIG 比率以及它所啟用的并發訪問功能。值為 1 表示支持。目前,它只在運行 64 位 Linux 的 Pascal 和更新的 GPUs 上受支持。
?