
高性能計算(HPC)為模擬和建模、醫療健康、生命科學、工業和工程等領域的應用提供支持。在現代數據中心,HPC 與 AI 協同工作,以變革性的新方式利用數據。
新一代 HPC 應用程序對性能和吞吐量的需求催生了一個能夠處理多種工作負載并在 CPU 和 GPU 之間實現緊密協作的加速計算平臺。NVIDIA Grace CPU 和 NVIDIA Hopper GPU 構成了用于 HPC 開發的行業領先硬件生態系統。
NVIDIA 提供了一系列工具、庫和編譯器,幫助開發者充分利用 NVIDIA Grace 和 NVIDIA Grace Hopper 架構的潛力。這些資源支持創新,并助力應用程序最大化地利用加速計算的優勢。此基礎軟件堆棧不僅提供了 GPU 加速的方法,還包括在基于 NVIDIA Grace 的系統上移植和優化應用程序的策略。了解更多關于 NVIDIA Grace 編譯器、工具、庫等信息,請訪問 Grace 開發者產品頁面。
NVIDIA HPC SDK 23.11
NVIDIA GPU 在硬件方面的新進展,NVIDIA Grace Hopper 系統能夠顯著改變開發者的 GPU 編程方式。最值得注意的是,CPU 和 GPU 顯存之間的雙向、高帶寬和緩存一致性連接,意味著用戶可以在使用單個統一地址空間的同時,為兩個處理器開發應用程序。
每個處理器都保留自己的物理內存,該內存的帶寬、延遲和容量特性與最適合每個處理器的工作負載相匹配。為現有的獨立顯存 GPU 系統編寫的代碼可以繼續高性能運行,而無需針對新的 Grace Hopper 架構進行修改。
所有應用程序線程(GPU 或 CPU)都可以直接訪問應用程序的系統分配顯存,從而無需在處理器之間復制數據。這種直接讀取或寫入整個應用程序顯存地址空間的新功能顯著提高了程序員使用基于 GPU 或 CPU 的所有編程模型構建程序的工作效率,包括 NVIDIA CUDA:CUDA C++、CUDA Fortran、ISO C++ 中的標準并行度、ISO Fortran、OpenACC、OpenMP 等。
NVIDIA HPC SDK 23.11 引入了新的統一內存編程支持,這使得原本受限于主機到設備或設備到主機傳輸的工作負載能夠實現高達 7 倍的速度提升,得益于 Grace Hopper 系統中的芯片到芯片 (C2C) 互連技術。此外,由于系統會自動處理數據的位置和遷移,應用程序開發過程得以大幅簡化。
閱讀《借助 NVIDIA Grace Hopper 超級芯片簡化 HPC 的 GPU 編程》,深入了解 NVIDIA 如何利用HPC 編譯器和這些新的硬件功能,通過 ISO C++、ISO Fortran、OpenACC 和 CUDA Fortran 來簡化 GPU 編程。
立即免費開始使用 NVIDIA HPC SDK,下載版本 23.11。
NVIDIA 性能庫
NVIDIA 現已發展成為一家全棧企業平臺提供商,不僅提供 GPU,還提供 CPU 和 DPUs。除了現有以 GPU 為中心的解決方案外,NVIDIA 的數學軟件產品現在還支持僅依賴 CPU 的工作負載。
NVIDIA 性能庫 (NVPL) 是針對 Arm 64 位架構優化的基本數學庫的集合。許多 HPC 應用程序都依賴于數學 API (例如 BLAS 和 LAPACK),這對其性能至關重要。NVPL 數學庫是這些標準化數學 API 的直接替代品。
它們針對 NVIDIA Grace CPU 進行了優化。在基于 Grace 的平臺上移植或構建的應用程序可以充分利用高性能和高效率的架構。NVPL 的一個主要目標是為開發者和系統管理員提供非常流暢的體驗,將現有 HPC 應用程序移植和部署到 Grace 平臺無需更改源代碼,以在使用基于 CPU 的標準化數學庫時實現更高的性能。
NVPL 測試版現已推出,其中包括 BLAS、LAPACK、FFT、RAND 和 SPARSE,可在 NVIDIA Grace CPU 上加速應用程序。
了解詳情并下載 NVPL 測試版。
NVIDIA CUDA Direct 稀疏求解器
我們正在將一個新的標準數學庫引入到 NVIDIA GPU 加速庫 中。NVIDIA CUDA Direct Sparse Solvers 庫(NVIDIA cuDSS)針對求解具有非常稀疏矩陣的線性系統進行了優化。雖然 cuDSS 的第一版支持在單個 GPU 上執行,但即將發布的版本將添加對多 GPU 和多節點的支持。
霍尼韋爾是 cuDSS 的早期采用者之一,目前正處于 UniSim Design 流程模擬產品性能基準測試的最后階段。
cuDNN 預覽版即將推出。點擊此處了解更多關于 CUDA 數學庫的信息:CUDA-X GPU 加速庫。
NVIDIA cuTENSOR 2.0
NVIDIA cuTENSOR 2.0 是一個高性能且靈活的庫,專為加速 HPC 和 AI 交叉路口的應用程序而設計。在這個主要版本更新中,cuTENSOR 2.0 引入了新功能和性能改進,特別是針對任意高維張量的優化。為了便于新優化能夠輕松地廣泛應用于所有張量運算,并同時保持高性能,cuTENSOR 2.0 的 API 進行了全面的重構,著重提升了靈活性和可擴展性。

基于計劃的多階段 API 通過一組共享 API 擴展到所有操作。新 API 可以將不透明堆分配的數據結構作為輸入,以傳遞為該執行定義的任何操作特定的問題描述符。
cuTENSOR 2.0 還增加了對即時 (JIT) 內核的支持。
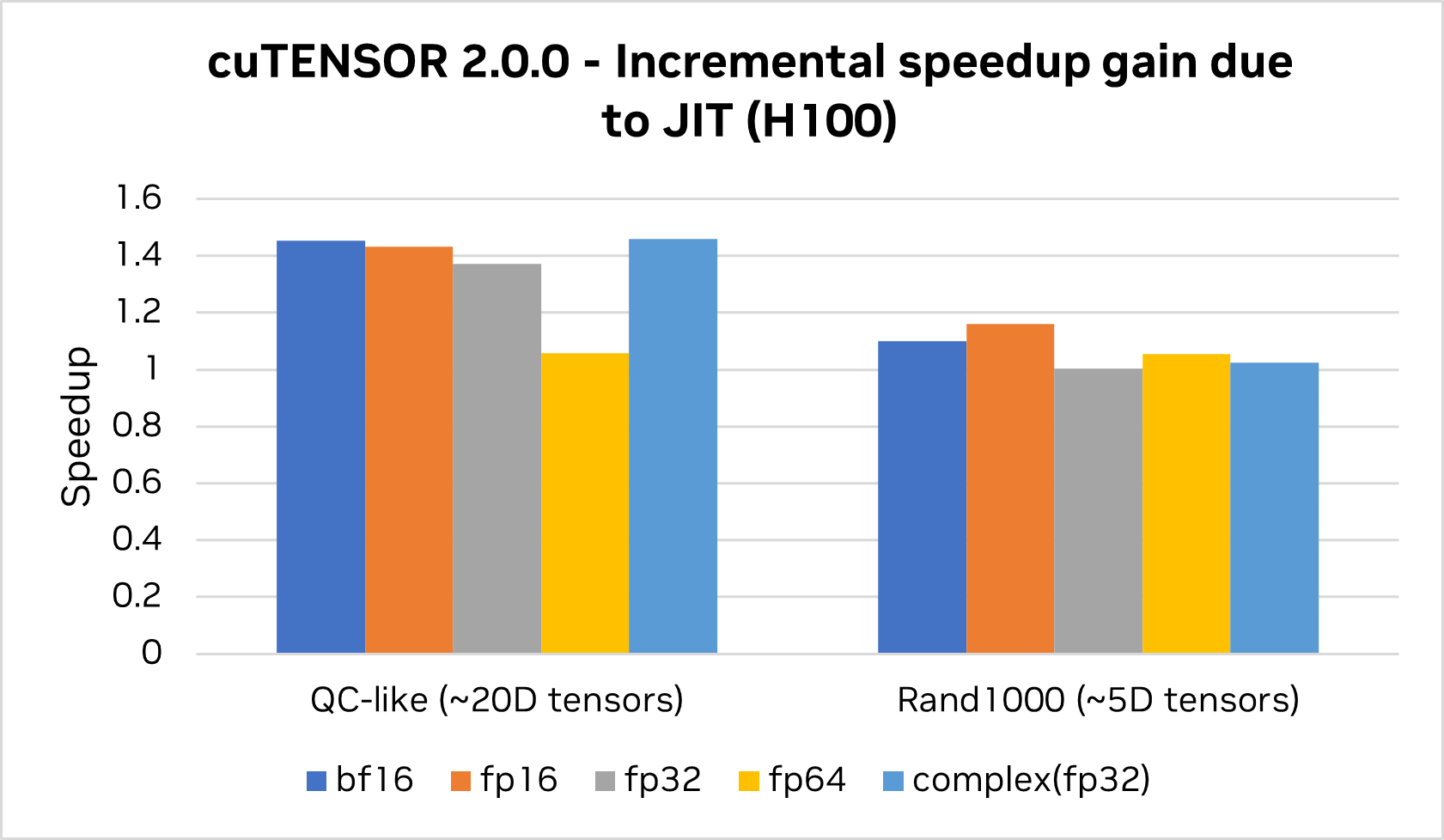
通過在運行時針對目標配置調整正確的配置和優化旋鈕,使用 JIT 內核有助于實現無與倫比的性能,同時支持大量高維張量,而這些張量無法通過庫可以提供的通用預編譯內核實現。
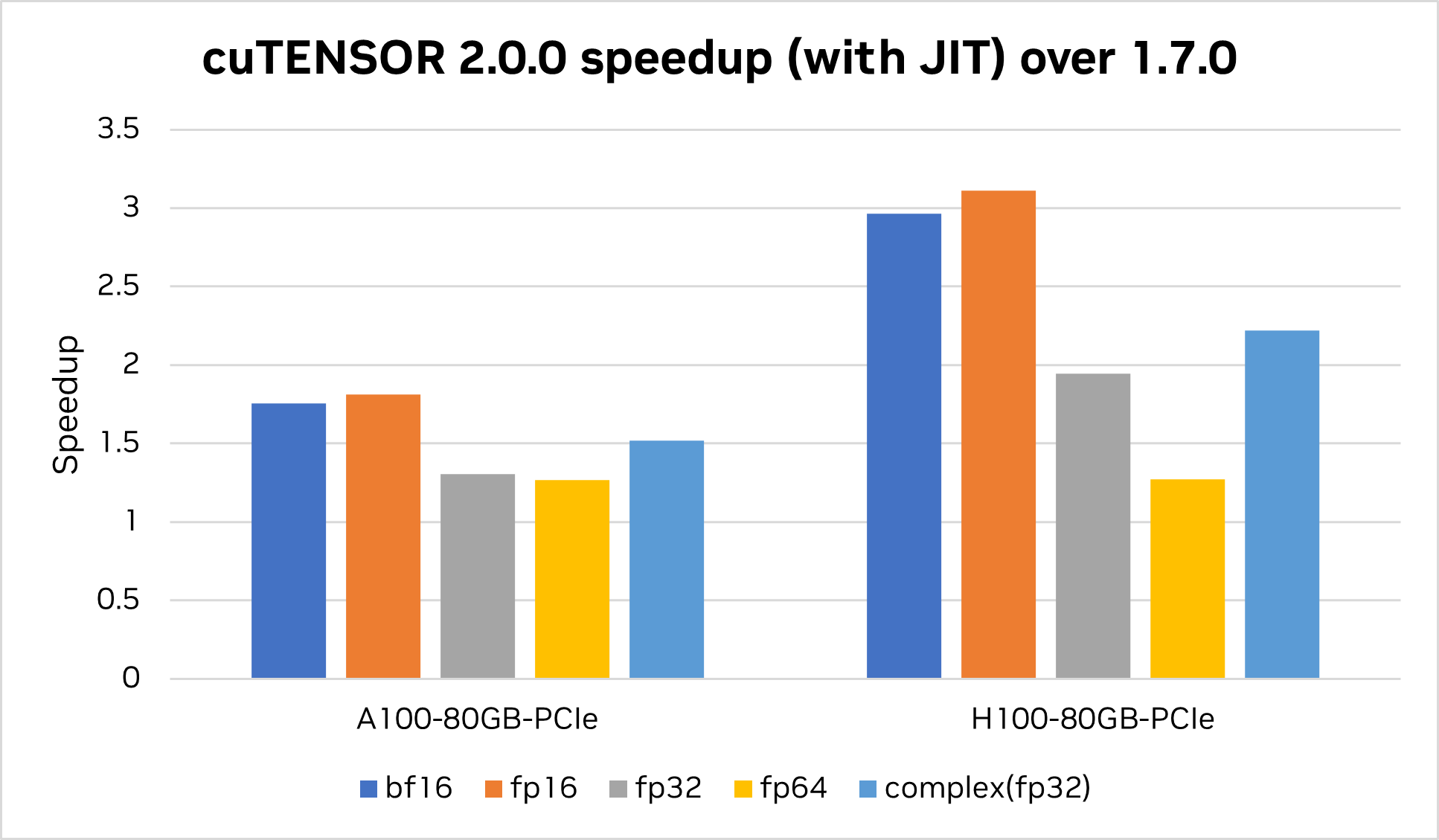
cuTENSOR 2.0 即將推出。
利用 NVIDIA Nsight Systems 2023.4 對 Grace CPU 進行性能調優
基于 Grace 的平臺上的應用程序受益于在 CPU 核心上調整指令執行,以及優化 CPU 與系統中其他硬件單元的交互。在將應用程序移植到 Grace 時,深入了解硬件級別的功能將幫助您為新平臺配置軟件。
NVIDIA Nsight Systems 是一個系統級性能分析工具,它能夠收集硬件和 API 的指標,并將這些指標在統一的時間軸上進行關聯。對于 Grace CPU 的性能調優,Nsight Systems 通過采樣指令指針和回溯來可視化 CPU 代碼的高負載區域,以及 CPU 如何利用整個系統的資源。此外,Nsight Systems 還能捕獲上下文切換,為所有 Grace CPU 核心構建利用率圖表。
Grace CPU 核心事件速率(如 CPU 周期和指令停用)顯示了 Grace 核心處理工作的方式。此外,回溯樣本的摘要視圖可幫助您快速確定哪些指令指針引起了熱點。
Grace CPU Uncore 事件速率現已在 Nsight Systems 2023.4 中推出,可用于監控 CPU 核心以外的活動,例如 NVLink-C2C 和 PCIe 活動。Uncore 指標能夠展示插槽間的活動如何支持 CPU 核心的工作,幫助您找到改善 Grace CPU 與系統其他部分集成的方法。
Nsight Systems 2023.4 中的 Grace CPU uncore 和 core 事件采樣可幫助您找到在 Grace 上運行的代碼的最佳優化。有關 Grace CPU 性能調整的更多信息,以及結合優化 CUDA 代碼的提示,請觀看以下視頻。
了解詳情并開始使用 Nsight Systems 2023.4。Nsight Systems 也可用于 HPC SDK 和 CUDA 工具包。
HPC 加速計算
NVIDIA 提供了一個由工具、庫和編譯器組成的生態系統,用于在 NVIDIA Grace 和 Hopper 架構上加速計算。HPC 軟件堆棧是 NVIDIA 數據中心芯片上研究和科學研究的基礎。
深入了解加速計算領域的 開發者論壇。
?




