在 本系列的第 1 部分 中,我們引入了新的 API 函數 cudaMallocAsync 和 cudaFreeAsync ,它們使內存分配和釋放成為流順序操作。在這篇文章中,我們通過分享一些大數據基準測試結果來強調這一新功能的好處,并為修改現有應用程序提供代碼 MIG 定量指南。我們還介紹了在多 GPU 訪問和 IPC 使用環境中利用流順序內存分配的高級主題。這一切都有助于提高現有應用程序的性能。
GPU 大數據基準
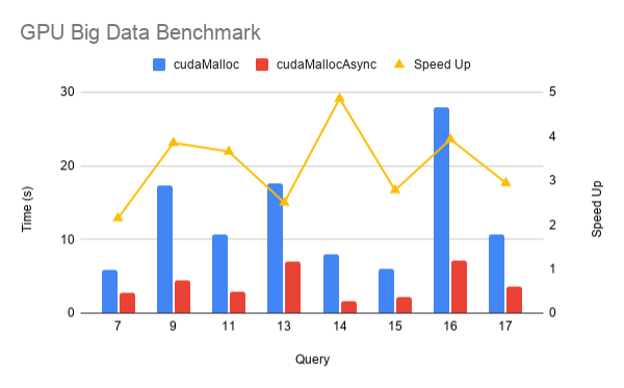
為了衡量新的流式有序分配器在實際應用程序中的性能影響,以下是來自 RAPIDS GPU 大數據基準 ( GPU -bdb]的結果。 GPU -bdb 是 30 個查詢的基準,這些查詢以各種比例因子表示現實世界的數據科學和機器學習工作流: SF1000 是 1 TB 的數據, SF10000 是 10 TB 的數據。事實上,每個查詢都是一個模型工作流,可以包括 SQL 、用戶定義函數、仔細的子集和聚合以及機器學習。
圖 1 顯示了在 SF1000 上在 NVIDIA DGX-2 上跨 16 個 V100 GPU 執行的 gpu-bdb 查詢子集的 cudaMallocAsync 與 cudaMalloc 的性能比較。如您所見,由于內存重用和消除無關同步,使用 cudaMallocAsync 時端到端性能提高了 2-5 倍。
與 CUDA Malloc 和 CUDA Free 的互操作性
應用程序可以使用 cudaFreeAsync 釋放 cudaMalloc 分配的指針。在下一次同步傳遞到 cudaFreeAsync 的流之前,不會釋放基礎內存。
cudaMalloc(&ptr, size); kernel<<<..., stream>>>(ptr); cudaFreeAsync(ptr, stream); cudaStreamSynchronize(stream); // The memory for ptr is freed at this point
類似地,應用程序可以使用 cudaFree 釋放使用 cudaMallocAsync 分配的內存。但是,在這種情況下, cudaFree 不會隱式同步,因此應用程序必須插入適當的同步,以確保對要釋放的內存的所有訪問都已完成。任何有意或無意依賴 cudaFree 的隱式同步行為的應用程序代碼都必須更新。
cudaMallocAsync(&ptr, size, stream); kernel<<<..., stream>>>(ptr); cudaStreamSynchronize(stream); // Must synchronize first cudaFree(ptr);
多 – GPU 訪問
默認情況下,可以從與指定流關聯的設備訪問使用 cudaMallocAsync 分配的內存。從任何其他設備訪問內存需要啟用從該其他設備訪問整個池。正如 cudaDeviceCanAccessPeer 所報告的,它還要求這兩個設備具有對等功能。與 cudaMalloc 分配不同, cudaDeviceEnablePeerAccess 和 cudaDeviceDisablePeerAccess 對從內存池分配的內存沒有影響。
例如,考慮啟用設備 4Access 到設備 3 的內存池:
cudaMemPool_t mempool;
cudaDeviceGetDefaultMemPool(&mempool, 3);
cudaMemAccessDesc desc = {};
desc.location.type = cudaMemLocationTypeDevice;
desc.location.id = 4;
desc.flags = cudaMemAccessFlagsProtReadWrite;
cudaMemPoolSetAccess(mempool, &desc, 1 /* numDescs */);
調用 cudaMemPoolSetAccess 時,可以使用 cudaMemAccessFlagsProtNone 撤銷對內存池所在設備以外的設備的訪問。無法撤消對內存池自身設備的訪問。
進程間通信支持
使用與設備關聯的默認內存池分配的內存不能與其他進程共享。應用程序必須顯式創建自己的內存池,以便與其他進程共享使用 cudaMallocAsync 分配的內存。以下代碼示例顯示如何創建具有進程間通信( IPC )功能的顯式內存池:
cudaMemPool_t exportPool;
cudaMemPoolProps poolProps = {};
poolProps.allocType = cudaMemAllocationTypePinned;
poolProps.handleTypes = cudaMemHandleTypePosixFileDescriptor;
poolProps.location.type = cudaMemLocationTypeDevice;
poolProps.location.id = deviceId;
cudaMemPoolCreate(&exportPool, &poolProps);
位置類型設備和位置 ID deviceId 指示必須在特定 GPU 上分配池內存。分配類型 pinted 表示內存應該是 non-migratable ,也稱為不可分頁。句柄類型 PosixFileDescriptor 表示用戶打算查詢池的文件描述符,以便與其他進程共享。
通過 IPC 共享此池中的內存的第一步是查詢表示該池的文件描述符:
int fd; cudaMemAllocationHandleType handleType = cudaMemHandleTypePosixFileDescriptor; cudaMemPoolExportToShareableHandle(&fd, exportPool, handleType, 0);
然后,應用程序可以與另一個進程共享文件描述符,例如通過 UNIX 域套接字。然后,另一個進程可以導入文件描述符并獲得進程本地池句柄:
cudaMemPool_t importPool; cudaMemAllocationHandleType handleType = cudaMemHandleTypePosixFileDescriptor; cudaMemPoolImportFromShareableHandle(&importPool, &fd, handleType, 0);
下一步是導出過程從池中分配內存:
cudaMallocFromPoolAsync(&ptr, size, exportPool, stream);
cudaMallocAsync 還有一個重載版本,它采用與 cudaMallocFromPoolAsync 相同的參數:
cudaMallocAsync(&ptr, size, exportPool, stream);
通過這兩個 API 中的任何一個從該池分配內存后,指針就可以與導入進程共享。首先,導出過程獲得一個表示內存分配的不透明句柄:
cudaMemPoolPtrExportData data; cudaMemPoolExportPointer(&data, ptr);
然后,可以通過任何標準 IPC 機制(例如通過共享內存、管道等)與導入進程共享此不透明數據。導入進程然后將不透明數據轉換為進程本地指針:
cudaMemPoolImportPointer(&ptr, importPool, &data);
現在,兩個進程共享對相同內存分配的訪問。在導出過程中釋放內存之前,必須先在導入過程中釋放內存。這是為了確保在導出過程中,當導入過程仍在訪問以前的共享內存分配時,內存不會重新用于另一個 cudaMallocAsync 請求,從而可能導致未定義的行為。
現有函數 cudaIpcGetMemHandle 僅適用于通過 cudaMalloc 分配的內存,不能用于通過 cudaMallocAsync 分配的任何內存,無論該內存是否從顯式池分配。
更改設備池
如果應用程序期望大部分時間使用顯式內存池,則可以考慮通過 cudaDeviceSetMemPool 將其設置為設備的當前池。這使應用程序可以避免每次必須從池中分配內存時都必須指定池參數。
cudaDeviceSetMemPool(device, pool); cudaMallocAsync(&ptr, size, stream); // This now allocates from the earlier pool set instead of the device’s default pool.
這樣做的好處是,使用 cudaMallocAsync 分配的任何其他函數現在都會自動使用新池作為默認池。可以使用 cudaDeviceGetMemPool 查詢與設備關聯的當前池。
庫可組合性
通常,庫不應該更改設備的池,因為這樣做會影響整個頂級應用程序。如果庫必須分配具有不同于默認設備池屬性的內存,它可以創建自己的池,然后使用 cudaMallocFromPoolAsync 從該池進行分配。該庫還可以使用 cudaMallocAsync 的重載版本,該版本將池作為參數。
為了使應用程序的互操作更容易,庫應該考慮為頂級應用程序提供 API 以協調所使用的池。例如,庫可以提供 set 或 get API ,使應用程序能夠以更明確的方式控制池。庫還可以將池作為單個 API 的參數。
代碼遷移指南
當將使用 cudaMalloc 或 cudaFree 的現有應用程序移植到新的 cudaMallocAsync 或 cudaFreeAsync API 時,考慮以下準則。
確定適當人才庫的指南:
- 初始默認池適用于許多應用程序。
- 今天,顯式構造的池只需要在與 CUDA IPC 的進程之間共享池內存。這可能會隨著將來的功能而改變。
- 為了方便起見,考慮將顯式創建池設置為設備的當前池,以確保進程內的所有
cudaMallocAsync調用都使用該池。這必須由頂級應用程序而不是庫來完成,以避免與頂級應用程序的目標沖突。
為所有內存池設置釋放閾值的準則:
- 設備的共享和釋放方式取決于:
- 對單個進程是獨占的 :使用最大釋放閾值。
- 在合作進程之間共享 :通過 IPC 協調使用相同的池,或將每個進程池設置為適當的值,以避免任何一個進程獨占所有設備內存。
- 在未知進程之間共享: 如果已知,請將閾值設置為應用程序的工作集大小。否則,在使用非零值之前,請將其保留為零,并使用探查器確定分配性能是否是瓶頸。
用 cudaMallocAsync 替換 cudaMalloc 的指南:
- 確保所有內存訪問都是在流順序分配之后排序的。
- 如果需要對等訪問,請使用
cudaMemPoolSetAccess,因為cudaEnablePeerAccess和cudaDisablePeerAccesss對池內存沒有影響。 - 與
cudaMalloc分配不同,cudaDeviceReset不會隱式釋放池內存,因此必須顯式釋放。 - 如果使用
cudaFree釋放,請確保在釋放之前通過適當的同步完成所有訪問,因為在這種情況下沒有隱式同步。依賴隱式同步的任何后續代碼也可能需要更新。 - 如果內存通過 IPC 與另一個進程共享,請從顯式創建的支持 IPC 的池中進行分配,并刪除該指針對
cudaIpcGetMemHandle、cudaIpcOpenMemHandle和cudaIpcCloseMemHandle的所有引用。 - 如果該內存必須與 GPU 直接 RDMA 一起使用,請暫時繼續使用
cudaMalloc,因為通過cudaMallocAsync分配的內存目前不支持它。 CUDA 打算在將來支持它。 - 與使用
cudaMalloc分配的內存不同,使用cudaMallocAsync分配的內存與 CUDA 上下文不關聯。這有以下影響:- 使用屬性
CU_POINTER_ATTRIBUTE_CONTEXT調用cuPointerGetAttribute會為上下文返回 null 。 - 當使用至少一個使用
cudaMallocAsync分配的源或目標指針調用cudaMemcpy時,必須可以從調用線程的當前上下文/設備訪問該內存。如果無法從該上下文或設備訪問,請改用cudaMemcpyPeer。
- 使用屬性
將 cudaFree 替換為 cudaFree 的指南
- 確保所有內存訪問都是在按流排序的釋放之前排序的。
- 在下一次同步操作之前,可能無法將內存釋放回系統。如果釋放閾值設置為非零值,則在顯式修剪相應的池之前,可能無法將內存釋放回系統。
- 與
cudaFree不同,cudaFreeAsync不會隱式同步設備。任何依賴此隱式同步的代碼都必須更新為顯式同步。
結論
CUDA 11 . 2 中添加的流式有序分配器以及 cudaMallocAsync 和 cudaFreeAsync API 函數通過將內存分配和釋放作為流式有序操作引入 CUDA 流編程模型,擴展了 CUDA 流編程模型。這使得分配的范圍能夠限定到內核,內核使用它們,同時避免了傳統 cudaMalloc/cudaFree 可能發生的昂貴的設備范圍同步。
此外,這些 API 函數在 CUDA 中添加了內存池的概念,從而實現了內存的重用,從而避免了代價高昂的系統調用并提高了性能。使用指南 MIG 評估您現有的代碼,并查看您的應用程序性能有多大改進!
?