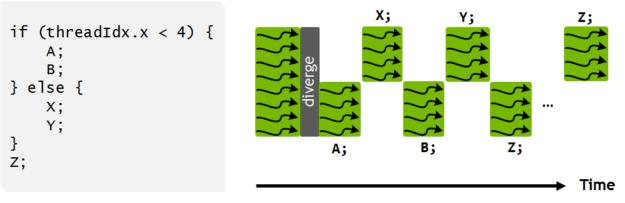
NVIDIA GPUs 以 SIMT (單指令,多線程)方式執行稱為 warps? 的線程組。許多 CUDA 程序通過利用 warp 執行來獲得高性能。在這個博客中,我們將展示如何使用 CUDA 9 中引入的原語,使您的 warp 級編程安全有效。
扭曲級別基本體
NVIDIA GPUs 和 CUDA 編程模型采用一種稱為 SIMT (單指令,多線程)的執行模型。 SIMT 擴展了計算機體系結構的 弗林分類學 ,它根據指令和數據流的數量描述了四類體系結構。作為 Flynn 的四個類之一, SIMD (單指令,多數據)通常用于描述類似 GPUs 的體系結構。但是 SIMD 和 SIMT 之間有一個微妙但重要的區別。在 SIMD 體系結構中,同一個指令中有多個并行操作。 SIMD 通常使用帶有向量寄存器和執行單元的處理器來實現;標量線程發出以 SIMD 方式執行的向量指令。在 SIMT 體系結構中,多線程向任意數據發出通用指令,而不是單線程發出應用于數據向量的向量指令。
SIMT 對于可編程性的好處使得 NVIDIA 的 GPU 架構師為這種架構命名,而不是將其描述為 SIMD 。 NVIDIA GPUs 使用 SIMT 執行 32 個并行線程的 warp ,這使得每個線程能夠訪問自己的寄存器,從不同的地址加載和存儲,并遵循不同的控制流路徑。 CUDA 編譯器和 GPU 一起工作,以確保 warp 的線程盡可能頻繁地一起執行相同的指令序列,從而最大限度地提高性能。
雖然通過 warp 執行獲得的高性能發生在場景后面,但是許多 CUDA 程序可以通過顯式 warp 級編程獲得更高的性能。并行程序通常使用集體通信操作,例如并行縮減和掃描。 CUDA C ++通過提供扭曲級基元和合作群集合來支持這樣的集合運算。合作組 collectives ( 在上一篇文章中描述過 )是在本文關注的 warp 原語之上實現的。
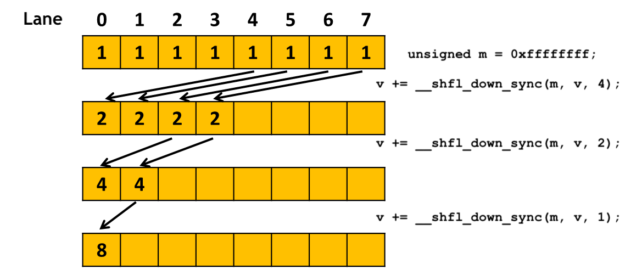
清單 1 顯示了一個使用 warp 級別原語的示例。它使用 __shfl_down_sync() 執行樹縮減來計算扭曲中每個線程持有的 val 變量的總和。在第一個環的末尾, val 包含第一個線程的和。
#define FULL_MASK 0xffffffff
for (int offset = 16; offset > 0; offset /= 2)
val += __shfl_down_sync(FULL_MASK, val, offset);
一個經線由 32 個 lanes 組成,每根線占據一個通道。對于曲速中位于 X 道的線程, __shfl_down_sync(FULL_MASK, val, offset) 從同一曲速的 X+offset 道上的線程獲取 val 變量的值。數據交換是在寄存器之間進行的,比通過共享內存更有效,共享內存需要加載、存儲和額外的寄存器來保存地址。
CUDA 9 引入了三類新的或更新的扭曲級原語。
- 同步數據交換:在 warp 中線程之間交換數據。
__all_sync,__any_sync,__uni_sync,__ballot_sync__shfl_sync,__shfl_up_sync,__shfl_down_sync,__shfl_xor_sync__match_any_sync,__match_all_sync
- 活動掩碼查詢:返回一個 32 位掩碼,指示扭曲中的哪些線程與當前正在執行的線程處于活動狀態。
__activemask
- 線程同步:同步扭曲中的線程并提供內存邊界。
__syncwarp
請看
同步數據交換
每個“同步數據交換”原語在一個 warp 中的一組線程之間執行一個集體操作。例如,清單 2 顯示了其中的三個。調用 __shfl_sync() 或 __shfl_down_sync() 的每個線程都從同一個 warp 中的線程接收數據,而調用 __ballot_sync() 的每個線程都會接收一個位掩碼,該掩碼表示 warp 中為謂詞參數傳遞真值的所有線程。
int __shfl_sync(unsigned mask, int val, int src_line, int width=warpSize);
int __shfl_down_sync(unsigned mask, int var, unsigned detla,
int width=warpSize);
int __ballot_sync(unsigned mask, int predicate);
參與調用每個原語的線程集是使用 32 位掩碼指定的,這是這些原語的第一個參數。所有參與線程必須同步,集體操作才能正常工作。因此,如果線程尚未同步,這些原語將首先同步線程。
一個常見的問題是“對于 mask 參數,我應該使用什么?”. 可以將遮罩視為扭曲中應參與集體操作的線程集。這組線程由程序邏輯決定,通常可以通過程序流中早期的某些分支條件來計算。以清單 1 中的縮減代碼為例。假設我們要計算一個數組 input[], 的所有元素的總和,該數組的大小 NUM_ELEMENTS 小于線程塊中的線程數。我們可以使用清單 3 中的方法。
unsigned mask = __ballot_sync(FULL_MASK, threadIdx.x < NUM_ELEMENTS);
if (threadIdx.x < NUM_ELEMENTS) {
val = input[threadIdx.x];
for (int offset = 16; offset > 0; offset /= 2)
val += __shfl_down_sync(mask, val, offset);
…
}
代碼使用條件 thread.idx.x < NUM_ELEMENTS 來確定線程是否將參與縮減。 __ballot_sync() 用于計算 __shfl_down_sync() 操作的成員掩碼。 __ballot_sync() 本身使用 FULL_MASK ( 0xffffffff 表示 32 個線程),因為我們假設所有線程都將執行它。
在 Volta 和更高版本的 GPU 架構中,數據交換原語可以用于線程發散的分支:在這種分支中, warp 中的一些線程采用不同于其他線程的路徑。清單 4 顯示了一個示例,其中一個 warp 中的所有線程都從第 0 行的線程獲得 val 的值。偶數和奇數編號的線程采用 if 語句的不同分支。
if (threadIdx.x % 2) {
val += __shfl_sync(FULL_MASK, val, 0);
…
}
else {
val += __shfl_sync(FULL_MASK, val, 0);
…
}
在最新(和將來 )的 Volta 的 GPU 上,您可以運行使用 warp 同步原語的庫函數,而不必擔心函數是否在線程發散分支中被調用。
活動掩碼查詢
__activemask() 返回調用扭曲中所有當前活動線程的 32 位 unsigned int 掩碼。換句話說,它顯示了在其 warp 中的線程也在執行相同的 __activemask() 的調用線程。這對于我們稍后解釋的:機會扭曲級編程”技術以及調試和理解程序行為非常有用。
但是,正確使用 __activemask() 很重要。清單 5 說明了一個不正確的用法。代碼嘗試執行與清單 4 中所示相同的總和縮減,但是它在分支內部使用了 __activemask() ,而不是在分支之前使用 __ballot_sync() 來計算掩碼。這是不正確的,因為這將導致部分和而不是總和。 CUDA 執行模型并不能保證將分支連接在一起的所有線程將一起執行 __activemask() 。正如我們將要解釋的那樣,不能保證隱式鎖步驟的執行。
//
// Incorrect use of __activemask()
//
if (threadIdx.x < NUM_ELEMENTS) {
unsigned mask = __activemask();
val = input[threadIdx.x];
for (int offset = 16; offset > 0; offset /= 2)
val += __shfl_down_sync(mask, val, offset);
…
}
翹曲同步
當 warp 中的線程需要執行比數據交換原語提供的更復雜的通信或集體操作時,可以使用 __syncwarp() 原語來同步 warp 中的線程。它類似于 __syncthreads() 原語(同步線程塊中的所有線程),但粒度更細。
void __syncwarp(unsigned mask=FULL_MASK);
__syncwarp() 原語使執行線程等待,直到 mask 中指定的所有線程都執行了 __syncwarp() (使用相同的 mask ),然后再繼續執行。它還提供了一個 記憶柵欄 ,允許線程在調用原語之前和之后通過內存進行通信。
清單 6 顯示了一個在 warp 中的線程之間混亂矩陣元素所有權的示例。
float val = get_value(…); __shared__ float smem[4][8]; // 0 1 2 3 4 5 6 7 // 8 9 10 11 12 13 14 15 // 16 17 18 19 20 21 22 23 // 24 25 26 27 28 29 30 31 int x1 = threadIdx.x % 8; int y1 = threadIdx.x / 8; // 0 4 8 12 16 20 24 28 // 1 5 10 13 17 21 25 29 // 2 6 11 14 18 22 26 30 // 3 7 12 15 19 23 27 31 int x2= threadIdx.x / 4; int y2 = threadIdx.x % 4; smem[y1][x1] = val; __syncwarp(); val = smem[y2][x2]; use(val);
假設使用了一維線程塊(即 threadIdx . y 始終為 0 )。在代碼的開頭,一個 warp 中的每個線程都擁有一個 4 × 8 矩陣的元素,該矩陣具有行主索引。換句話說,第 0 車道擁有 [0][0] 車道,第 1 車道擁有 [0][1] 。每個線程將其值存儲到共享內存中 4 × 8 數組的相應位置。然后使用 __syncwarp() 來確保在每個線程從數組中的一個轉置位置讀取數據之前,所有線程都完成了存儲。最后, warp 中的每一個線程都擁有一個矩陣元素,列主索引為: lane0 擁有 [0][0] , lane1 擁有 [1][0] 。
確保 __syncwarp() 將共享內存讀寫分開,以避免爭用情況。清單 7 演示了共享內存中樹和縮減的錯誤用法。在每兩個 __syncwarp() 調用之間有一個共享內存讀取,然后是共享內存寫入。 CUDA 編程模型不能保證所有的讀操作都會在所有的寫操作之前執行,因此存在競爭條件。
unsigned tid = threadIdx.x; // Incorrect use of __syncwarp() shmem[tid] += shmem[tid+16]; __syncwarp(); shmem[tid] += shmem[tid+8]; __syncwarp(); shmem[tid] += shmem[tid+4]; __syncwarp(); shmem[tid] += shmem[tid+2]; __syncwarp(); shmem[tid] += shmem[tid+1]; __syncwarp();
清單 8 通過插入額外的 __syncwarp() 調用修復了競爭條件。 CUDA 編譯器可以在最終生成的代碼中省略一些同步指令,這取決于目標體系結構(例如,在預伏打體系結構上)。
unsigned tid = threadIdx.x; int v = 0; v += shmem[tid+16]; __syncwarp(); shmem[tid] = v; __syncwarp(); v += shmem[tid+8]; __syncwarp(); shmem[tid] = v; __syncwarp(); v += shmem[tid+4]; __syncwarp(); shmem[tid] = v; __syncwarp(); v += shmem[tid+2]; __syncwarp(); shmem[tid] = v; __syncwarp(); v += shmem[tid+1]; __syncwarp(); shmem[tid] = v;
在最新的 Volta (和 future ) GPUs 上,也可以在線程發散分支中使用 __syncwarp() 來同步兩個分支的線程,但是一旦它們從原語返回,線程就會再次發散。請參見清單 13 中的示例。
機會主義翹曲水平編程
正如我們在同步數據交換一節中所示,在同步數據交換原語中使用的成員關系 mask 通常是在程序流中的分支條件之前計算的。在許多情況下,程序需要沿著程序流傳遞掩碼;例如,在函數內部使用扭曲級原語時,作為函數參數。如果要在庫函數內使用 warp 級編程,但不能更改函數接口,則這可能很困難。
有些計算可以使用碰巧一起執行的任何線程。我們可以使用一種稱為機會主義翹曲級別編程的技術,如下例所示。(有關該算法的更多信息,請參見 這個帖子 中的 warp aggregated atomics ;有關協作組如何使實現更簡單的討論,請參見 這個帖子 。)
// increment the value at ptr by 1 and return the old value
__device__ int atomicAggInc(int *ptr) {
int mask = __match_any_sync(__activemask(), (unsigned long long)ptr);
int leader = __ffs(mask) – 1; // select a leader
int res;
if(lane_id() == leader) // leader does the update
res = atomicAdd(ptr, __popc(mask));
res = __shfl_sync(mask, res, leader); // get leader’s old value
return res + __popc(mask & ((1 << lane_id()) – 1)); //compute old value
}
atomicAggInc() 以原子方式將 ptr 指向的值遞增 1 并返回舊值。它使用 atomicAdd() 函數,這可能會引發爭用。為了減少爭用, atomicAggInc 用 per-warp atomicAdd() 替換了 per-thread atomicAdd() 操作。第 4 行中的 __activemask() 在 warp 中查找將要執行原子操作的線程集。[zx7]的傳入線程具有相同的值,這些線程的[zx7]與[ez3]的值相同。每個組選擇一個引導線程(第 5 行),該線程為整個組執行 atomicAdd() (第 8 行)。每個線程從 atomicAdd() 返回的前導(第 9 行)獲取舊值。第 10 行計算并返回當前線程調用函數而不是 atomicAggInc 時從 atomicInc() 獲得的舊值。
隱式 Warp 同步編程是不安全的
CUDA 版本 9 . 0 之前的工具箱提供了一個(現在是遺留的) warp 級別基本體版本。與 CUDA 9 原語相比,傳統原語不接受 mask 參數。例如, int __any(int predicate) 是 int __any_sync(unsigned mask, int predicate) 的舊版本。
如前所述, mask 參數指定扭曲中必須參與原語的線程集。如果掩碼指定的線程在執行過程中尚未同步,則新基元將執行扭曲線程級內同步。
傳統的 warp 級別原語不允許程序員指定所需的線程,也不執行同步。因此,必須參與翹曲級別操作的線程不是由 CUDA 程序顯式表示的。這樣一個程序的正確性取決于隱式 warp 同步行為,這種行為可能從一個硬件體系結構改變到另一個,從一個 CUDA 工具包版本到另一個(例如,由于編譯器優化的變化),甚至從一個運行時執行到另一個。這種隱式 warp 同步編程是不安全的,可能無法正常工作。
例如,在下面的代碼中,假設 warp 中的所有 32 個線程一起執行第 2 行。第 4 行的 if 語句導致線程發散,奇數線程在第 5 行調用 foo() ,偶數線程在第 8 行調用 bar() 。
// Assuming all 32 threads in a warp execute line 1 together.
assert(__ballot(1) == FULL_MASK);
int result;
if (thread_id % 2) {
result = foo();
}
else {
result = bar();
}
unsigned ballot_result = __ballot(result);
CUDA 編譯器和硬件將嘗試在第 10 行重新聚合線程,以獲得更好的性能。但這一重新收斂是不保證的。因此, ballot_result 可能不包含來自所有 32 個線程的投票結果。
在 __ballot() 之前的第 10 行調用新的 __syncwarp() 原語,如清單 11 所示,也不能解決這個問題。這又是隱式翹曲同步編程。它假設同一個扭曲中的線程一旦同步,將保持同步,直到下一個線程發散分支為止。盡管這通常是真的,但在 CUDA 編程模型中并不能保證它。
__syncwarp(); unsigned ballot_result = __ballot(result);
正確的修復方法是使用清單 12 中的 __ballot_sync() 。
unsigned ballot_result = __ballot_sync(FULL_MASK, result);
一個常見的錯誤是假設在舊的 warp 級別原語之前和/或之后調用 __syncwarp() 在功能上等同于調用原語的 sync 版本。例如, __syncwarp(); v = __shfl(0); __syncwarp(); 與 __shfl_sync(FULL_MASK, 0) 相同嗎?答案是否定的,有兩個原因。首先,如果在線程發散分支中使用序列,那么 __shfl(0) 不會由所有線程一起執行。清單 13 顯示了一個示例。第 3 行和第 7 行的 __syncwarp() 將確保在執行第 4 行或第 8 行之前, warp 中的所有線程都會調用 foo() 。一旦線程離開 __syncwarp() ,奇數線程和偶數線程將再次發散。因此,第 4 行的 __shfl(0) 將得到一個未定義的值,因為當第 4 行執行時,第 0 行將不活動。 __shfl_sync(FULL_MASK, 0) 可以在線程發散的分支中使用,沒有這個問題。
v = foo();
if (threadIdx.x % 2) {
__syncwarp();
v = __shfl(0); // L3 will get undefined result because lane 0
__syncwarp(); // is not active when L3 is executed. L3 and L6
} else { // will execute divergently.
__syncwarp();
v = __shfl(0);
__syncwarp();
}
第二,即使所有線程一起調用序列, CUDA 執行模型也不能保證線程在離開 __syncwarp() 后保持收斂,如清單 14 所示。不能保證隱式鎖步驟的執行。請記住,線程收斂只在顯式同步的扭曲級別原語中得到保證。
assert(__activemask() == FULL_MASK); // assume this is true __syncwarp(); assert(__activemask() == FULL_MASK); // this may fail
因為使用它們可能會導致不安全的程序,所以從 CUDA 9 . 0 開始就不推薦使用舊的 warp 級別原語。
更新舊版曲速級編程
如果您的程序使用舊的 warp 級原語或任何形式的隱式 warp 同步編程(例如在沒有同步的 warp 線程之間通信),您應該更新代碼以使用原語的 sync 版本。您可能還需要重新構造代碼以使用 Cooperative Groups ,這提供了更高級別的抽象以及諸如多塊同步等新功能。
使用翹曲級別原語最棘手的部分是找出要使用的成員掩碼。我們希望以上幾節能給你一個好主意,從哪里開始,注意什么。以下是建議列表:
- 不要只使用
FULL_MASK(即對于 32 個線程使用0xffffffff)作為mask值。如果不是所有的線程都能根據程序邏輯到達原語,那么使用FULL_MASK可能會導致程序掛起。 - 不要只使用
__activemask()作為掩碼值。__activemask()告訴您調用函數時哪些線程會收斂,這可能與您希望在集合操作中的情況不同。 - 分析程序邏輯并理解成員資格要求。根據程序邏輯提前計算掩碼。
- 如果您的程序執行機會主義 warp 同步編程,請使用“ detective ”函數,如
__activemask()和__match_all_sync()來找到正確的掩碼。 - 使用
__syncwarp()來分離與內部扭曲相關的操作。不要假設執行鎖步。
最后一個訣竅。如果您現有的 CUDA 程序在 Volta architecture GPUs 上給出了不同的結果,并且您懷疑差異是由 Volta 新的獨立線程調度 引起的,它可能會改變翹曲同步行為,您可能需要使用 nvcc 選項 -arch=compute_60 -code=sm_70 重新編譯程序。這樣的編譯程序選擇使用 Pascal 的線程調度。當有選擇地使用時,它可以幫助更快地確定罪魁禍首模塊,允許您更新代碼以避免隱式 warp 同步編程。