
深度學習( Deep learning , DL )是解決計算機視覺或自然語言等機器學習問題的最新方法,它的性能優于其它方法。最近的趨勢包括將 DL 技術應用于推薦引擎。許多大型公司,如 AirBnB 、 Facebook 、 Google 、 Home Depot 、 LinkedIn 和 Pinterest ,都分享了他們將 DL 用于推薦系統的經驗。
最近, NVIDIA 和 RAPIDS . AI 團隊與 DL 贏得了三場比賽: VZX1 、 信號和日期挑戰 和 ACM WSDM2021 Booking . com 挑戰賽 。
推薦系統的領域是復雜的。在這篇文章中,我將重點介紹神經網絡體系結構及其組件,例如嵌入層和完全連接層、遞歸神經網絡單元( LSTM 或 GRU )和變壓器塊。我討論了流行的網絡架構,比如 Google 的 Wide & Deep 和 Facebook 的 Deep Learning Recommender Model ( DLRM )。
DL 推薦系統的優點
有許多不同的技術來設計推薦系統,例如關聯規則、基于內容或協同過濾、矩陣分解或訓練線性或基于樹的模型來預測交互可能性。
使用神經網絡的優點是什么?一般來說, DL 模型可以獲得更高的精度。首先, DL 可以利用額外的數據。許多傳統的機器學習技術需要更多的數據。但是,當您增加神經網絡的容量時,該模型可以使用更多的數據來提高性能。
第二,神經網絡的設計是靈活的。例如,您可以針對多個目標(多任務學習)訓練 DL 模型,例如“用戶是否將項目添加到購物車中?”、“使用項目開始結賬?”、或“購買項目?”。每個目標都有助于模型從數據中提取信息,并且目標可以相互支持。
其他設計方法包括向推薦模型中添加多模態數據。您可以通過使用卷積神經網絡處理產品圖像或使用 NLP 模型處理產品描述來實現這一點。神經網絡應用于許多領域。您可以將新開發(如優化器或新層)轉移到推薦系統。
最后, DL 框架經過了高度優化,可以處理各種域的數 TB 到數 PB 的數據。下面是如何為推薦系統設計神經網絡。
基本構造塊:嵌入層
嵌入層用密集向量表示類別。這種技術在自然語言處理中非常流行,可以嵌入具有密集表示的單詞。具有相似意義的詞具有相似的嵌入向量。
您可以將相同的技術應用于推薦系統。最簡單的推薦系統是基于用戶和項目的:您應該向用戶推薦哪些項目?您有用戶 ID 和項目 ID 。單詞是 users 和 items ,因此使用兩個嵌入表(圖 1 )。
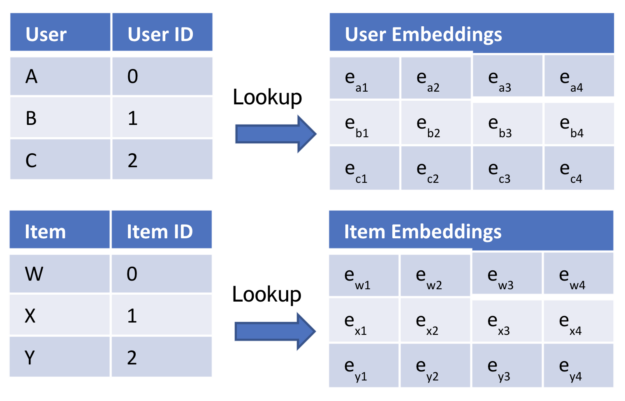
計算用戶嵌入和項目嵌入之間的點積,得到最終分數,即用戶與項目交互的可能性。最后一步可以應用 sigmoid 激活函數將輸出轉換為 0 到 1 之間的概率。
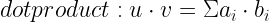
該方法等價于矩陣分解或交替最小二乘法( ALS )。
具有完全連接層的較深模型
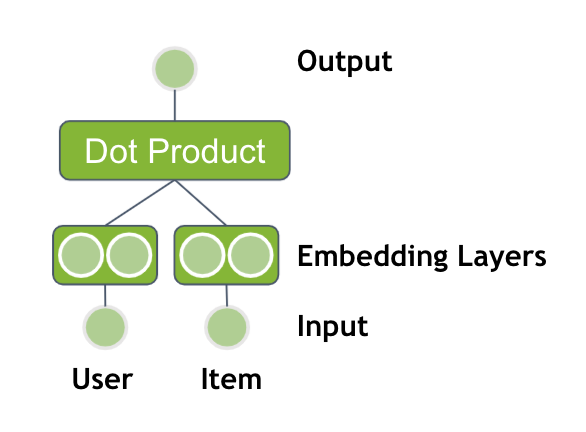
神經網絡的性能是基于具有多個非線性層的深層結構。通過將嵌入層的輸出通過多個具有 ReLU 激活的完全連接層提供,可以擴展先前的模型。
一個設計選擇是如何組合兩個嵌入向量。您可以僅串聯嵌入向量,也可以將向量逐元素相乘,類似于點積。輸出之后是多個隱藏層。
向神經網絡中添加元數據信息
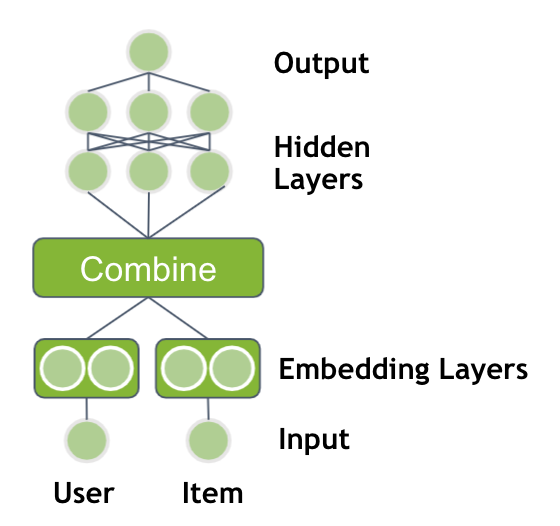
到目前為止,您只使用了用戶 ID 和產品 ID 作為輸入,但是您通常可以獲得更多的信息。其他用戶信息可以是性別、年齡、城市(地址)、自上次訪問以來的時間或用于支付的信用卡。一件商品通常有一個品牌、價格、類別或在過去 7 天內售出的數量。這些信息有助于模型更好地推廣。修改神經網絡以使用附加特征作為輸入。
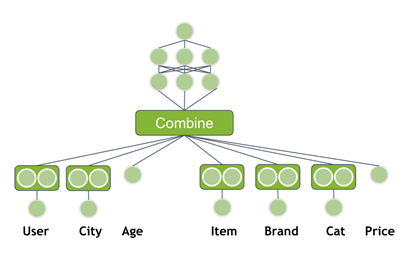
流行建筑
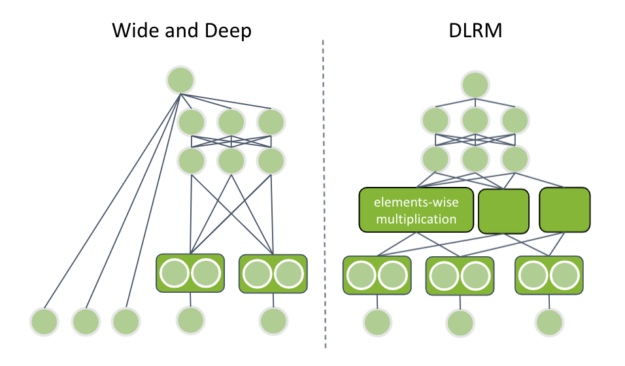
嵌入層和完全連接層是理解一些最新出版的神經網絡結構的主要組成部分。在這篇文章中,我將從 2016 年開始報道谷歌的廣度和深度,從 2019 年開始報道 Facebook 的 DLRM 。
谷歌的廣度和深度
谷歌的廣度和深度包含兩個部分:
- 記憶共同特征組合的寬塔
- 用來概括罕見或未觀察到的特征組合的深塔
創新之處在于,這兩個組件同時訓練,這是可能的,因為神經網絡是靈活的。深塔通過嵌入層提供分類特征,并將輸出與數字輸入特征連接起來。級聯向量通過多個完全連接的層饋送。
你聽上去熟悉嗎?是的,那是你以前的神經網絡設計。新的組成部分是寬塔,它只是輸入特征的線性組合,具有類似的線性/邏輯回歸。每個塔的輸出相加,得到最終的預測值。
Facebook 的 DLRM
Facebook 的 DLRM 與帶有元數據的神經網絡結構類似,但有一些特定的差異。數據集可以包含多個分類特征。 DLRM 要求所有的分類輸入都通過一個具有相同維數的嵌入層。稍后,我將討論這一點的重要性。
接下來,將連續的輸入串聯起來并通過稱為底部多層感知器( MLP )的多個完全連接的層饋送。底層 MLP 的最后一層具有與嵌入層向量相同的維數。
DLRM 使用了一個新的組合層。它在所有嵌入向量對和底部 MLP 輸出之間應用按元素相乘。這就是為什么每個向量都有相同的維數。所得到的向量被串聯并饋送到另一組完全連接的層(頂部 MLP )。
基于會話的推薦系統
當我為推薦系統分析不同的基于 DL 的體系結構時,我假設輸入具有表格數據結構,而忽略了用戶交互的本質。但是,用戶在訪問網站時,在一個會話中有多個交互。例如,他們訪問一家商店并查看多個產品頁面。您可以使用用戶交互序列作為輸入來提取模式嗎?
在一個會話中,用戶連續查看多條牛仔褲,您應該推薦另一條牛仔褲。在另一個會話中,同一個用戶連續查看多雙鞋,您應該推薦另一雙鞋。這就是基于會話的推薦系統背后的直覺。
謝天謝地,您可以將 NLP 中的一些技術應用于推薦系統域。用戶的交互具有順序結構。
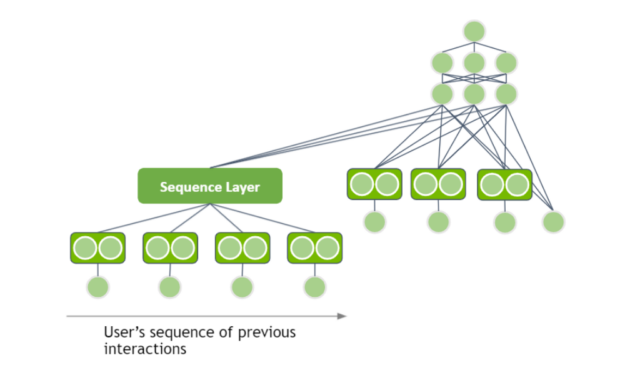
序列可以通過使用遞歸神經網絡( RNN )或基于變壓器的結構作為序列層來處理。用嵌入向量表示項目 ID ,并通過序列層提供輸出。序列層的隱藏表示可以添加為深度學習體系結構的輸入。
其他選擇
當我把這篇文章的重點放在將 DL 應用于推薦系統的理論上時,我沒有涉及到很多其他的挑戰。我在這里簡要介紹一下,以提供一個起點:
- 嵌入表可以超過 CPU 或 GPU 內存。由于在線服務可能有數百萬用戶,嵌入表可以達到數兆字節。 NVIDIA 提供了 HugeCTR 框架,可以將嵌入表擴展到 CPU 或 GPU 內存之外。
- 在培訓期間最大限度地利用 GPU 。基于 DL 的推薦系統有一個淺層的網絡結構,只有幾個完全連接的層。數據加載器有時是訓練管道中的瓶頸。為了抵消這一點, NVIDIA 為 PyTorch 和 TensorFlow 開發了一個 高度優化的 GPU 數據加載器 。
- 生成建議需要對用戶項對進行評分。最壞的情況是預測所有可用產品的可能性,并選擇最佳產品。在實踐中,這是不可行的,候選人產生了一個低開銷的模型,如近似近鄰。
概括
這篇文章向您介紹了基于 DL 的推薦系統。我首先介紹了基于兩個輸入的基本矩陣分解,然后介紹了使用 transformer 層的最新基于會話的體系結構。
您可以使用遞歸神經網絡( RNN )或基于轉換器的體系結構作為序列層來處理序列。用嵌入向量表示項目 ID ,并通過序列層提供輸出。添加序列層的隱藏表示作為 DL 架構的輸入。
有興趣學習更多關于推薦系統的知識嗎 NVIDIA Merlin 是一個開源框架,用于在 GPU 上端到端加速推薦系統。 NVIDIA 不斷開發更多資源,以便輕松地訓練和部署基于 DL 的推薦系統。以下是一些可以提供幫助的資源:
- NVIDIA/NVTabular GitHub repo 中的示例
- 7 月 29 日深度學習推薦峰會 , NVIDIA 和特邀演講者將討論他們在部署推薦系統和克服挑戰方面的經驗
?







