VILA 是 NVIDIA Research 和麻省理工學院共同開發的一系列高性能視覺語言模型。這些模型的參數規模從 ~3B 到 ~40B 不等。值得注意的是,VILA 是完全開源的,包括模型檢查點、訓練代碼和訓練數據。
在這篇文章中,我們描述了 VILA 在交付邊緣 AI 2.0 時如何與其他模型進行比較。
邊緣人工智能的初始版本涉及將壓縮的人工智能模型部署到邊緣設備上。這個階段被稱為 Edge AI 1.0,專注于特定任務的模型。這種方法的挑戰在于需要用不同的數據集訓練不同的模型,在這些數據集中,負樣本很難收集,異常情況也很難處理。這一過程非常耗時,凸顯了對適應性更強、通用性更強的人工智能解決方案的需求。
?邊緣人工智能 2.0:生成人工智能的崛起?
Edge AI 2.0 標志著由基礎視覺語言模型(VLM)推動的向增強泛化的轉變。
像 VILA 這樣的 VLM 表現出令人難以置信的多功能性,能夠理解復雜的指令并快速適應新的場景。這種靈活性使它們成為廣泛應用程序中的重要工具。它們可以優化自動駕駛汽車的決策,在物聯網和 AIoT 環境中創建個性化交互,事件檢測,并增強智能家居體驗。
VLM 的核心優勢在于它們在語言預訓練中獲得的世界知識,以及用戶用自然語言查詢它們的能力。這為人工智能智能相機帶來了動態處理能力,而無需對定制的視覺管道進行硬編碼。
邊緣的 VLM:VILA 和 NVIDIA Jetson Orin
要實現邊緣 AI 2.0,VLM 必須具有高性能且易于部署。VILA 通過以下方式實現這兩個目標:
- 精心設計的訓練管道,具有高質量的數據混合
- AWQ 4 位量化,精度損失可忽略不計
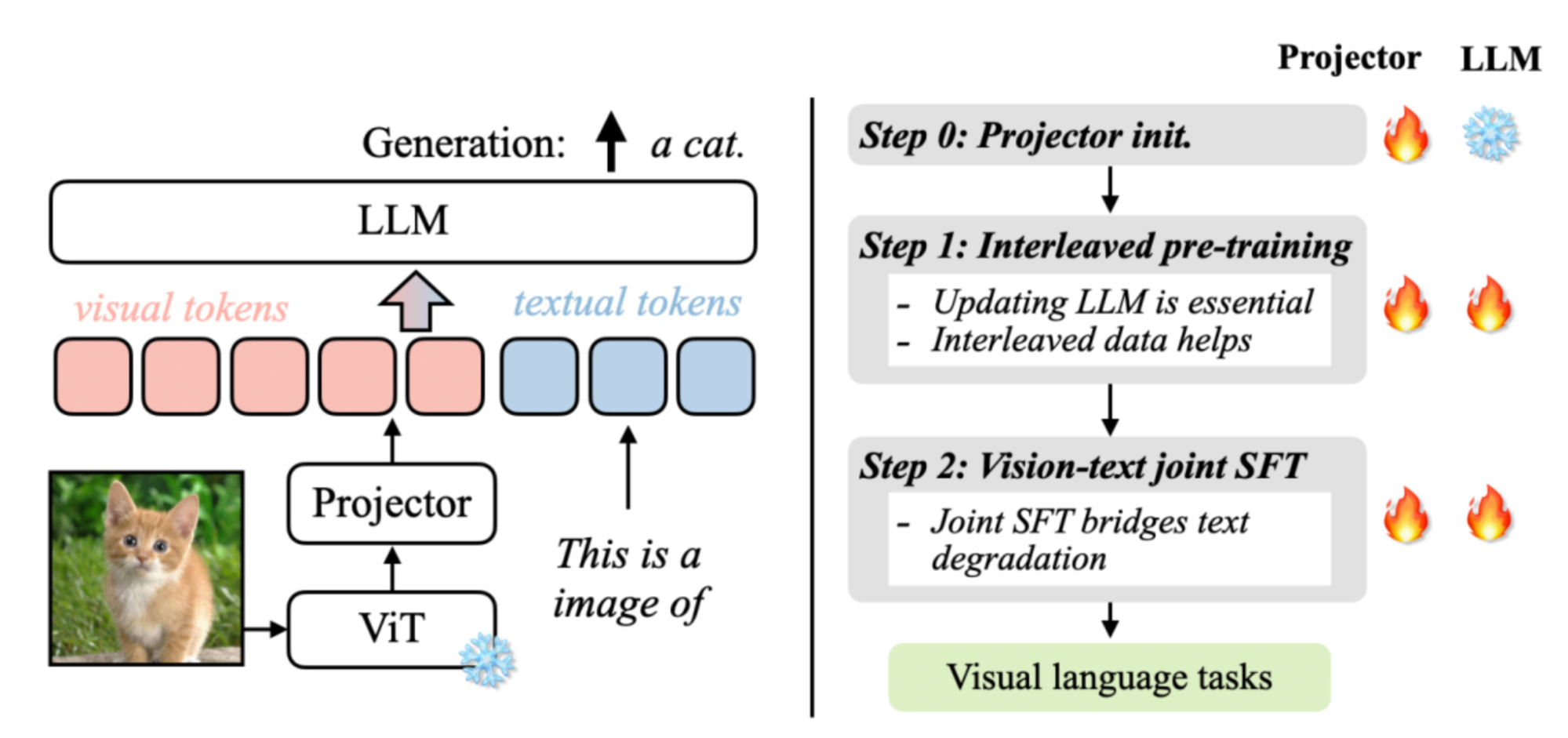
VILA 是一種將視覺信息引入 LLM 的視覺語言模型。VILA 模型由視覺編碼器、LLM 和投影儀組成,它們橋接了來自兩種模態的嵌入。為了利用強大的 LLM,VILA 使用視覺編碼器將圖像或視頻編碼為視覺標記,然后將這些視覺標記輸入 LLM,就好像它們是外語一樣。這種設計可以處理任意數量的交錯圖像文本輸入。
VILA 的成功源于其強化的預訓練配方。在對視覺語言模型預訓練選擇進行深入研究后,我們觀察到了三個主要發現:
- 在預訓練期間凍結 LLM 可以獲得不錯的零樣本表現,但缺乏上下文學習能力,這需要解凍 LLM。
- 交錯的預訓練數據是有益的,而單獨的圖像-文本對不是最佳的。
- 在指令微調過程中,將純文本指令數據與圖像文本數據重新混合不僅解決了純文本任務的退化問題,而且提高了 VLM 任務的準確性。
我們觀察到,預訓練過程為模型解鎖了幾個有趣的功能:
- 多圖像推理,盡管模型在 SFT(監督微調)期間只看到單個圖像-文本對
- 更強的情境學習能力
- 增強了世界知識
有關更多信息,請參閱 基于 VILA 的 NVIDIA 硬件可視化語言模型 這個 VILA:關于視覺語言模型的預訓練 論文,以及 Efficient-Large-Model/VILA GitHub 倉庫。
NVIDIA Jetson Orin 提供無與倫比的人工智能計算能力、大型統一內存和全面的人工智能軟件堆棧,使其成為在能效邊緣設備上部署 VILA 的完美平臺。借助 transformer 架構提供支持,Jetson Orin 能夠快速推理任何生成人工智能模型,在 MLPerf 基準測試中展現出色的性能。
AWQ 量化?
為了在 Jetson Orin 上部署 VILA,我們集成了 激活感知權重量化(AWQ),以實現 4 比特量化。通過 AWQ,我們能夠以可忽略的精度損失將 VILA 量化到 4 位精度,從而為 VLM 在維護性能標準的同時轉換邊緣計算鋪平了道路。
盡管像 AWQ 這樣的進步,在邊緣設備上部署大型語言和視覺模型仍然是一項復雜的任務。四位權重缺乏字節對齊,并且需要專門的計算以獲得最佳效率。
TinyChat 是一款專門為邊緣設備上的大語言模型(LLM)和視覺語言模型(VLM)設計的高效推理框架。其出色的適應性使其能夠在各種硬件平臺上運行,從 NVIDIA RTX 4070 筆記本電腦的 GPU 到 NVIDIA Jetson Orin,吸引了開源社區的極大興趣。
現在,TinyChat 擴大了支持范圍,實現了對視覺數據的重要理解和推理,通過支持 VILA。TinyChat 在結合文本和視覺處理方面提供了卓越的效率和靈活性,使邊緣設備能夠執行尖端的多模式任務。
基準?
下表顯示了 VILA 1.5-3B 的基準結果。鑒于其規模,它在圖像質量保證和視頻質量保證基準測試中表現出色。另外,您還可以看到,AWQ 4 位量化不會失去準確性,并且通過與 按比例縮放(S2),它能夠感知更高分辨率的圖像,從而進一步提高性能。
| 模型 | 精確 | VQA-V2 | VizWiz | GQA | VQA–T | 科學 QA–I | MME | 種子-I | MMMU 值 | MMMU 測試 |
| VILA-1.5-3B-S2 | fp16 | 79.8 | 61.3 | 61.4 | 63.4 | 69.6 | 1432 | 66.5 | 33.1 | 31.3 |
| VILA 1.5-3B | fp16 | 80.4 | 53.5 | 61.5 | 60.4 | 69 | 1442 | 67.9 | 33.3 | 30.8 |
| VILA 1.5-3B | int4 | 80 | 53.8 | 61.1 | 60.4 | 67.8 | 1437 | 66.6 | 32.7 | 31.1 |
| 模型 | ActivityNet | MSVD | MSR-VTT | TGIF | 感知測試 |
| 維拉 1.5-3B | 50.2 | 76.6 | 57.5 | 51.7 | 39.3 |
在 Jetson Orin 和 NVIDIA RTX 上部署?
隨著相機和視覺系統在現實世界環境中的使用越來越普遍,推斷邊緣設備上的 VILA 是一項重要任務。根據型號大小,您可以從七個 Jetson Orin 模塊中進行選擇,從入門級 AI 到高性能。這為您提供了為智能家居設備、醫療器械、自主機器人和視頻分析構建生成人工智能應用程序的終極靈活性,用戶可以動態重新配置和查詢這些應用程序。
圖 3 顯示了在 Jetson AGX Orin 和 Jetson Orin Nano 上運行 VILA 的端到端多模式管道性能,兩者都實現了視頻流的交互速率。
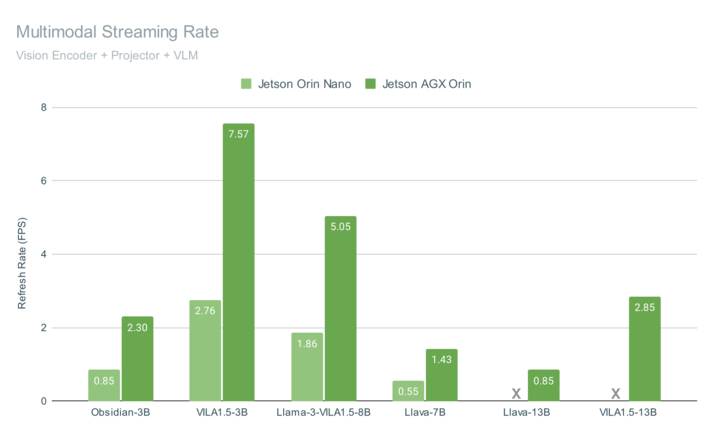
這些基準包括查詢幀的總時間,包括視覺編碼(使用 CLIP 或 SigLIP)、多模式投影、聊天嵌入的組裝以及使用 4 位量化生成語言模型輸出。VILA-1.5 模型包括一種新穎的自適應,將用于表示每個圖像嵌入的令牌數量從 729 個減少到 196 個,這提高了性能,同時在視覺編碼器中提高了空間分辨率的情況下保持了準確性。
我們提供了一種高度優化的、開源的 VLM 管道,它集成了多種高級功能,包括多模式 RAG 和一次拍攝圖像標記,以及圖像嵌入在整個系統中用于其他視覺相關任務的有效重用。
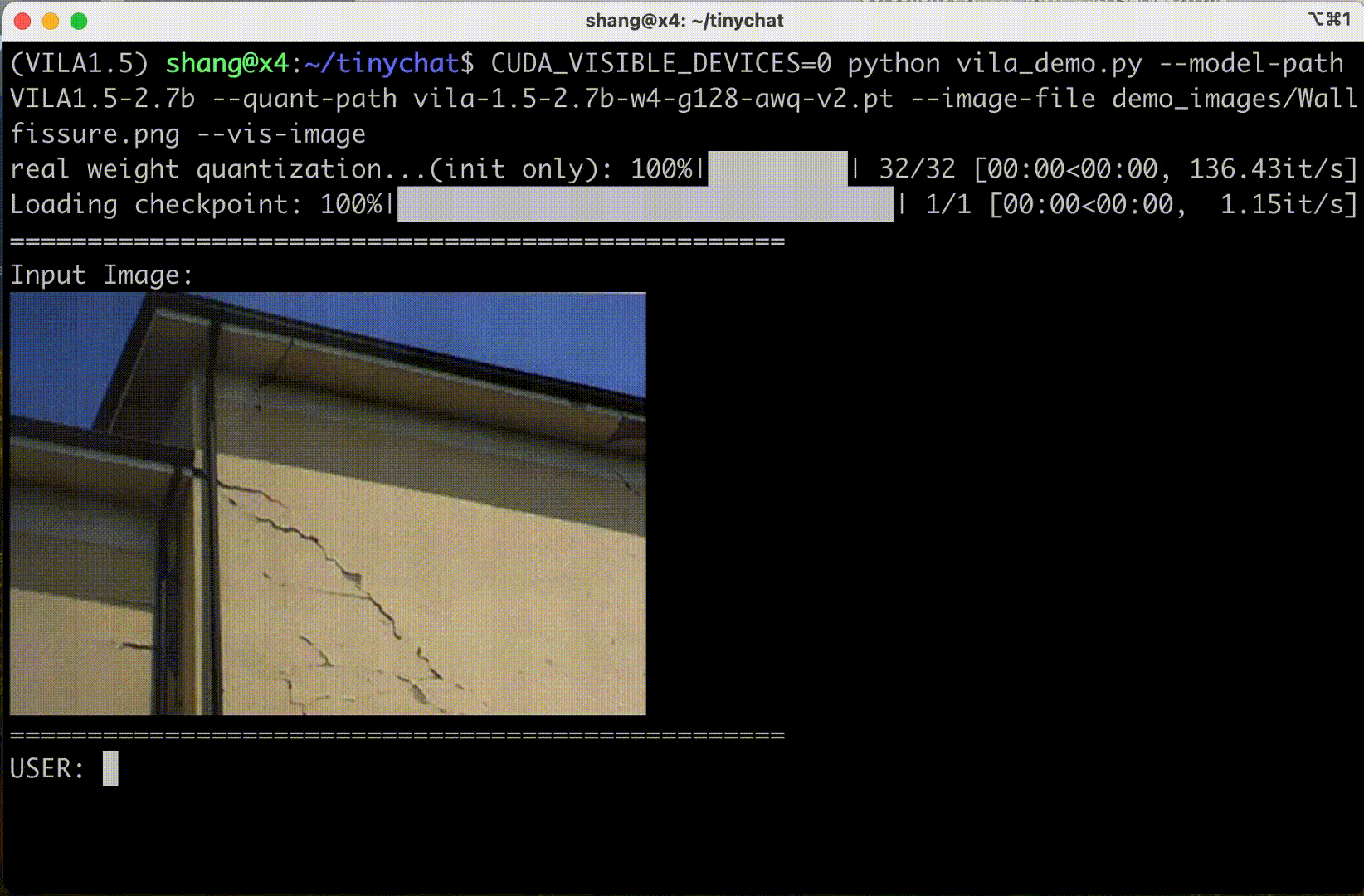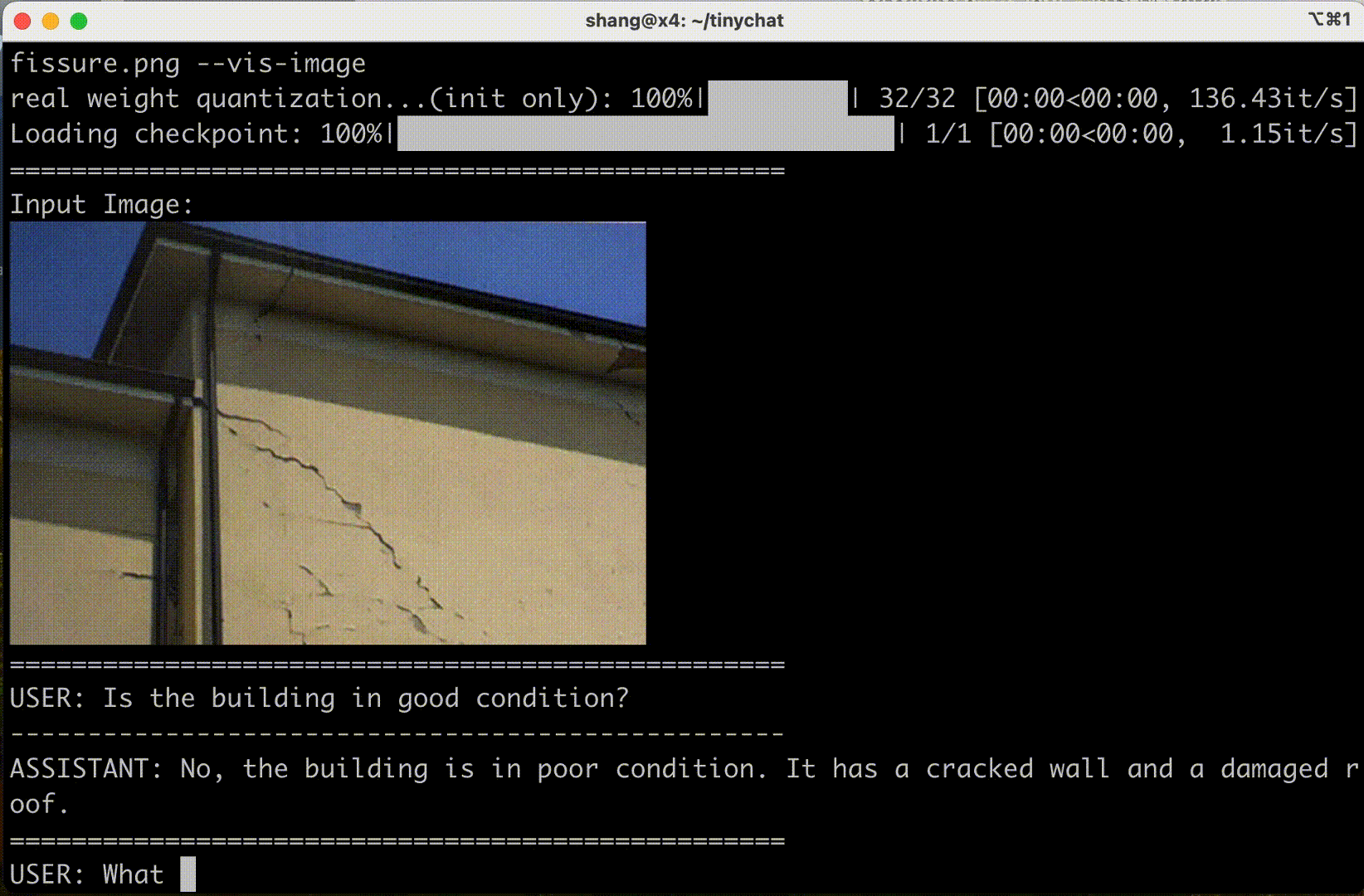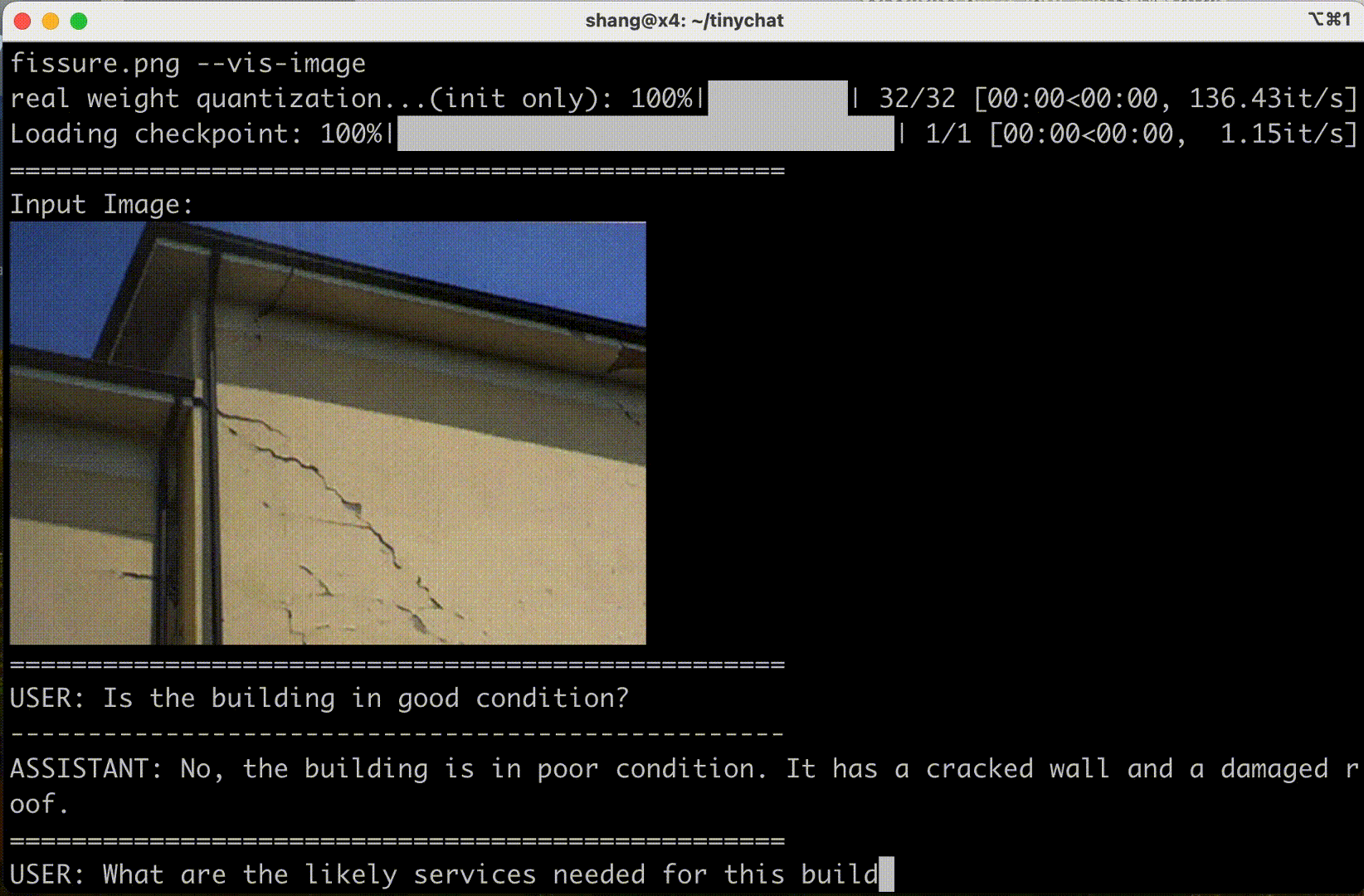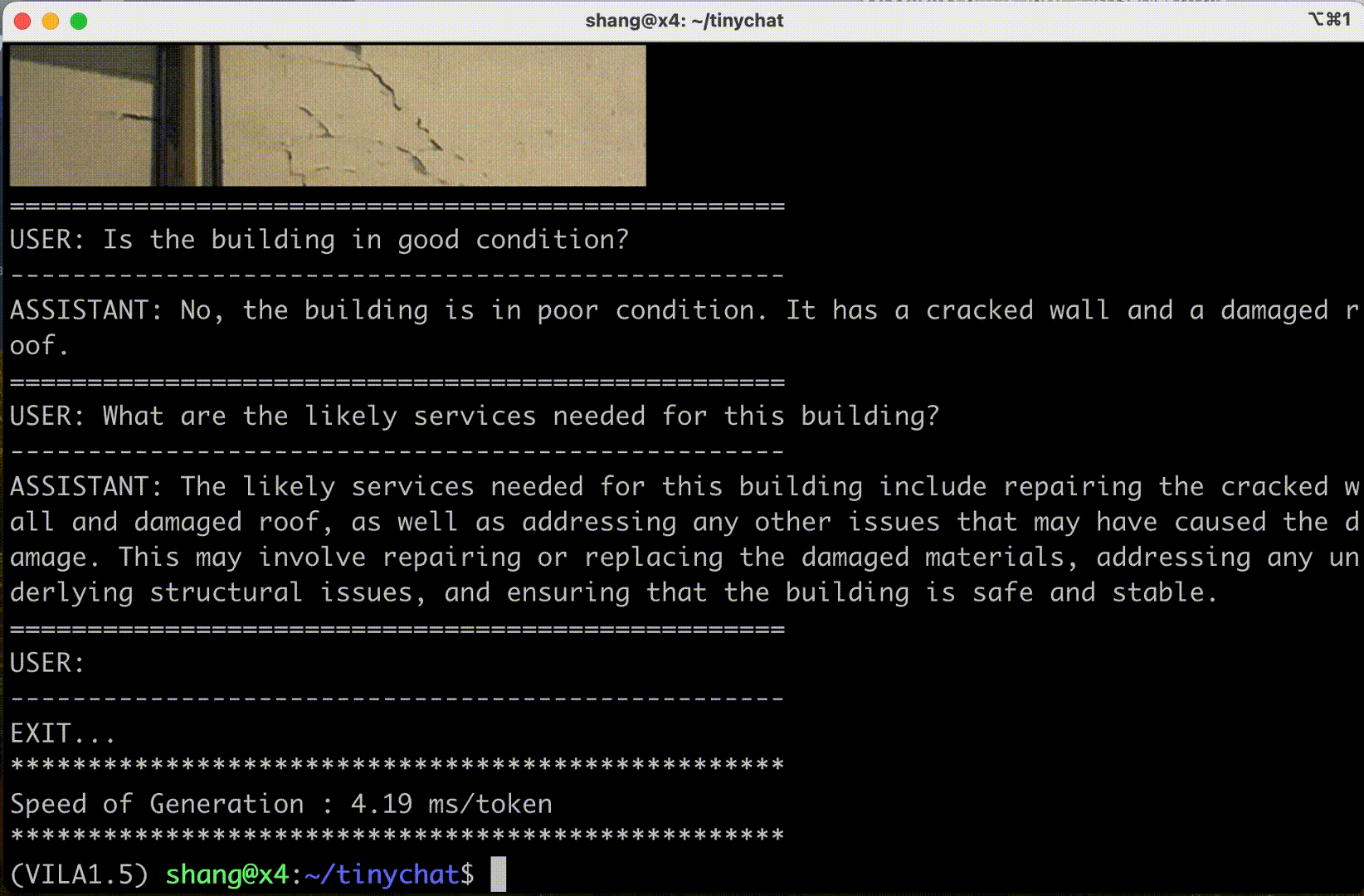
消費級 GPU 體驗?
VILA 還可以部署在筆記本電腦和 PC 工作站上的 NVIDIA RTX 等消費級 GPU 中,以提高用戶生產力和交互體驗。
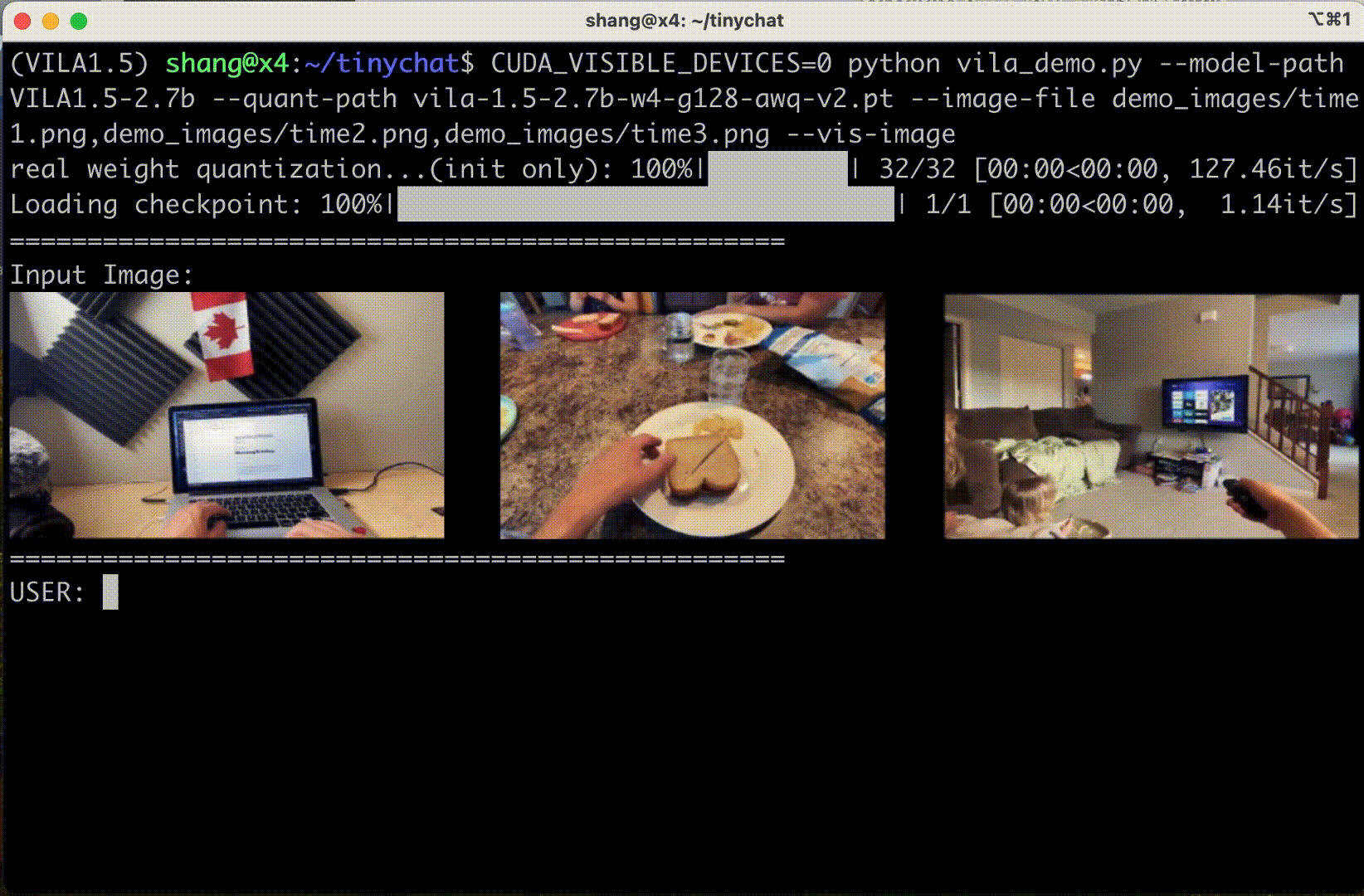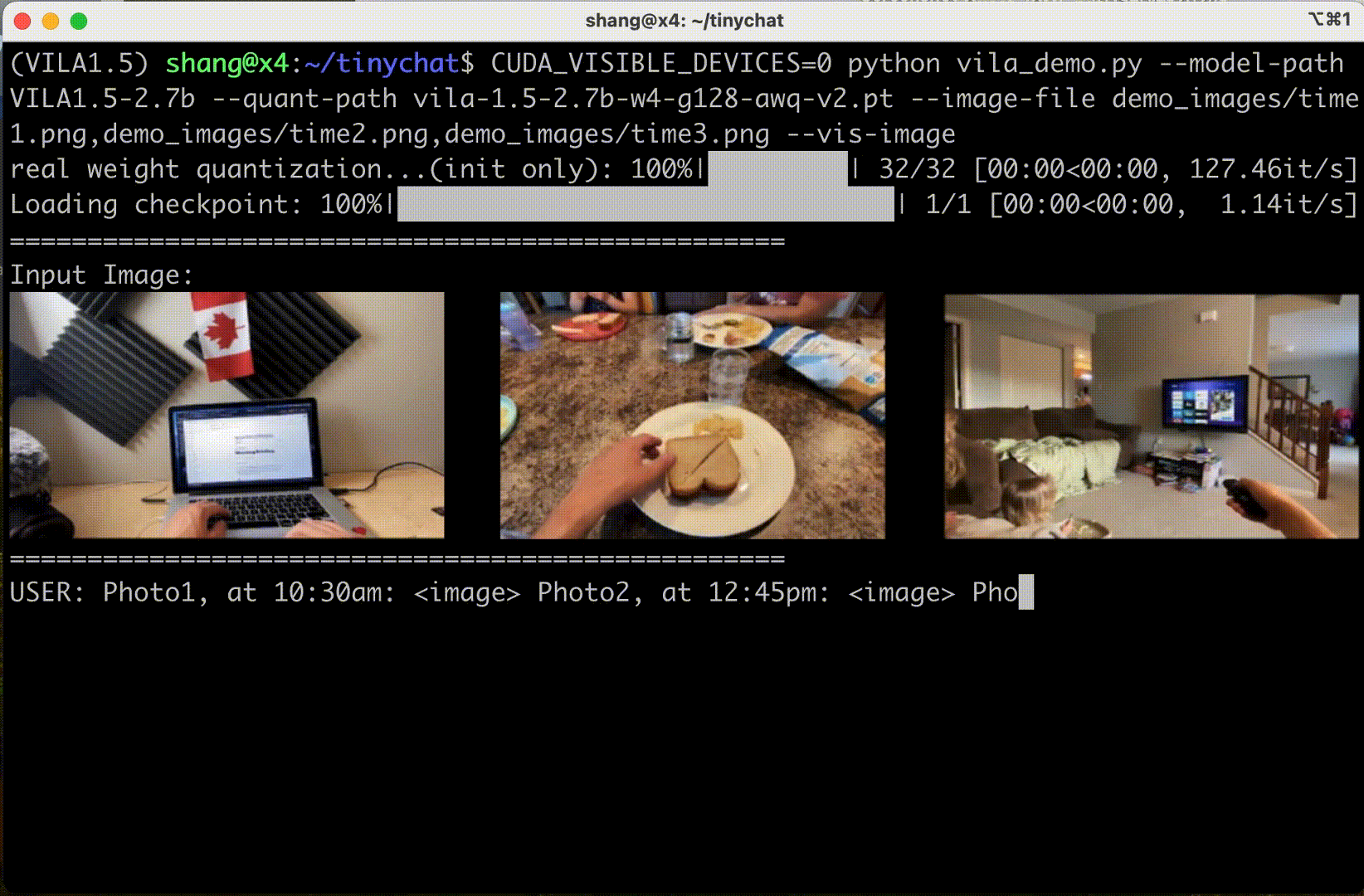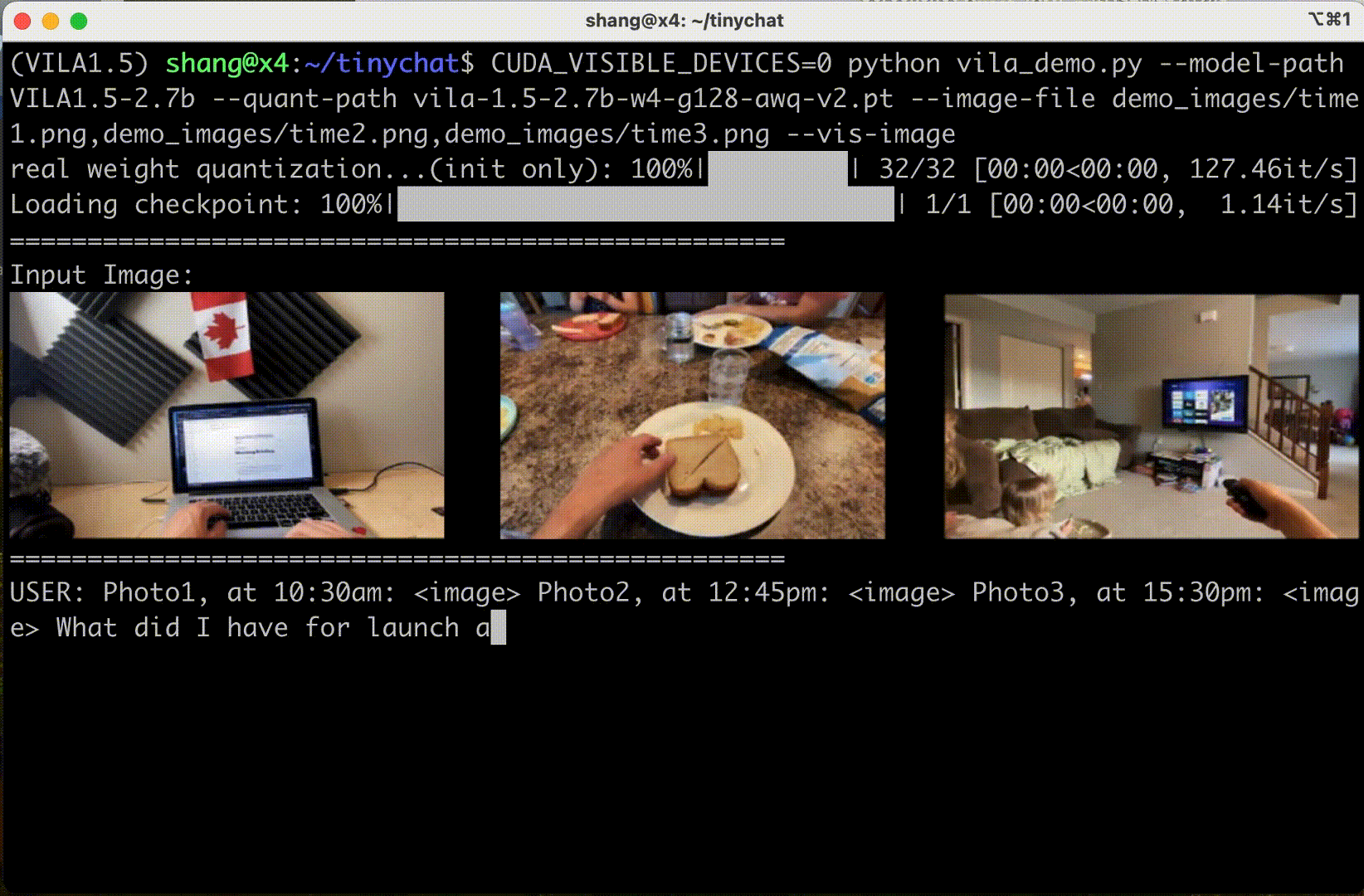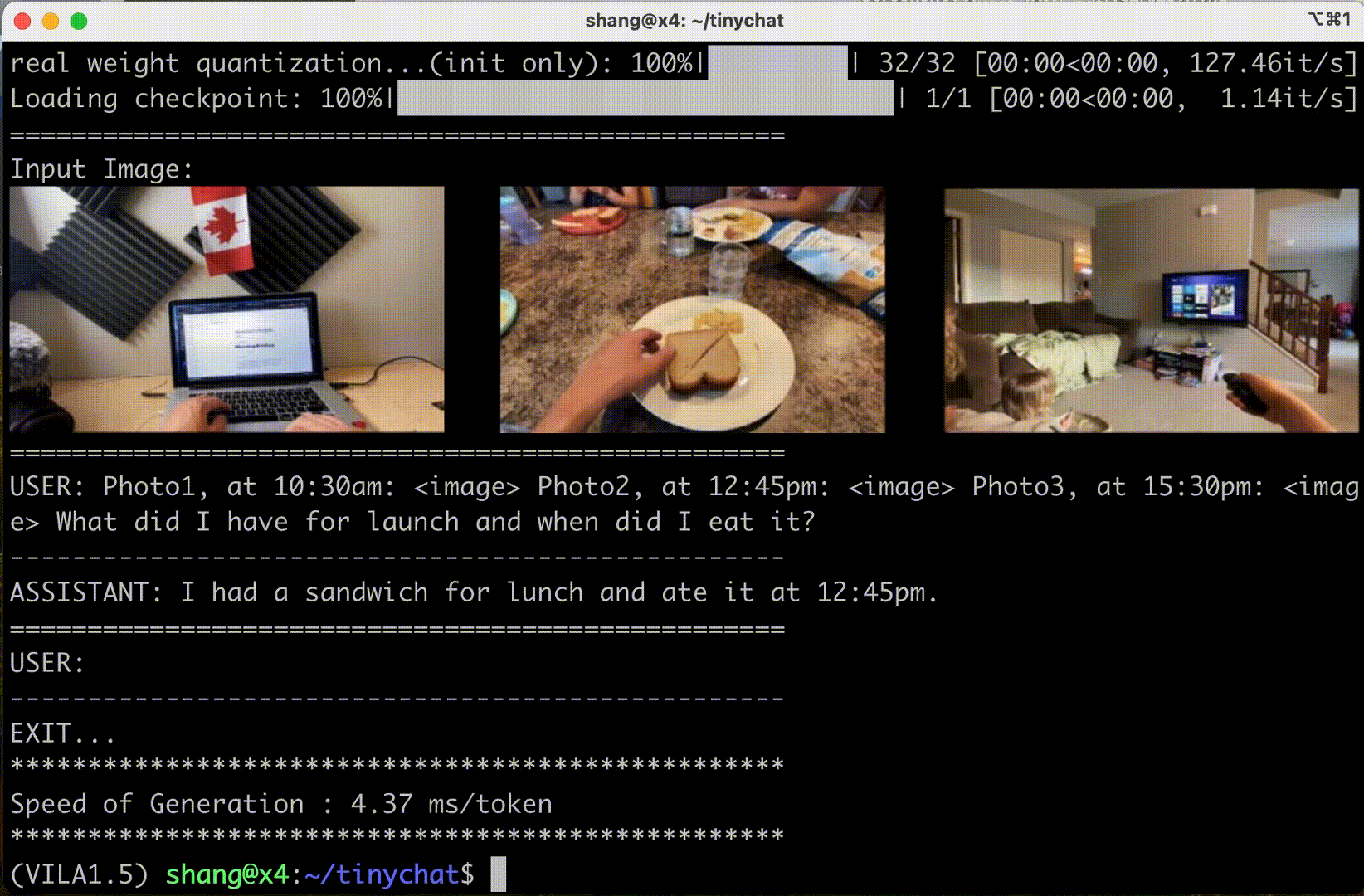
多圖像推理?
TinyChat 的最新版本使用了 VILA 令人印象深刻的多圖像推理功能,使您能夠同時上傳多個圖像以增強交互。這開啟了令人興奮的可能性。
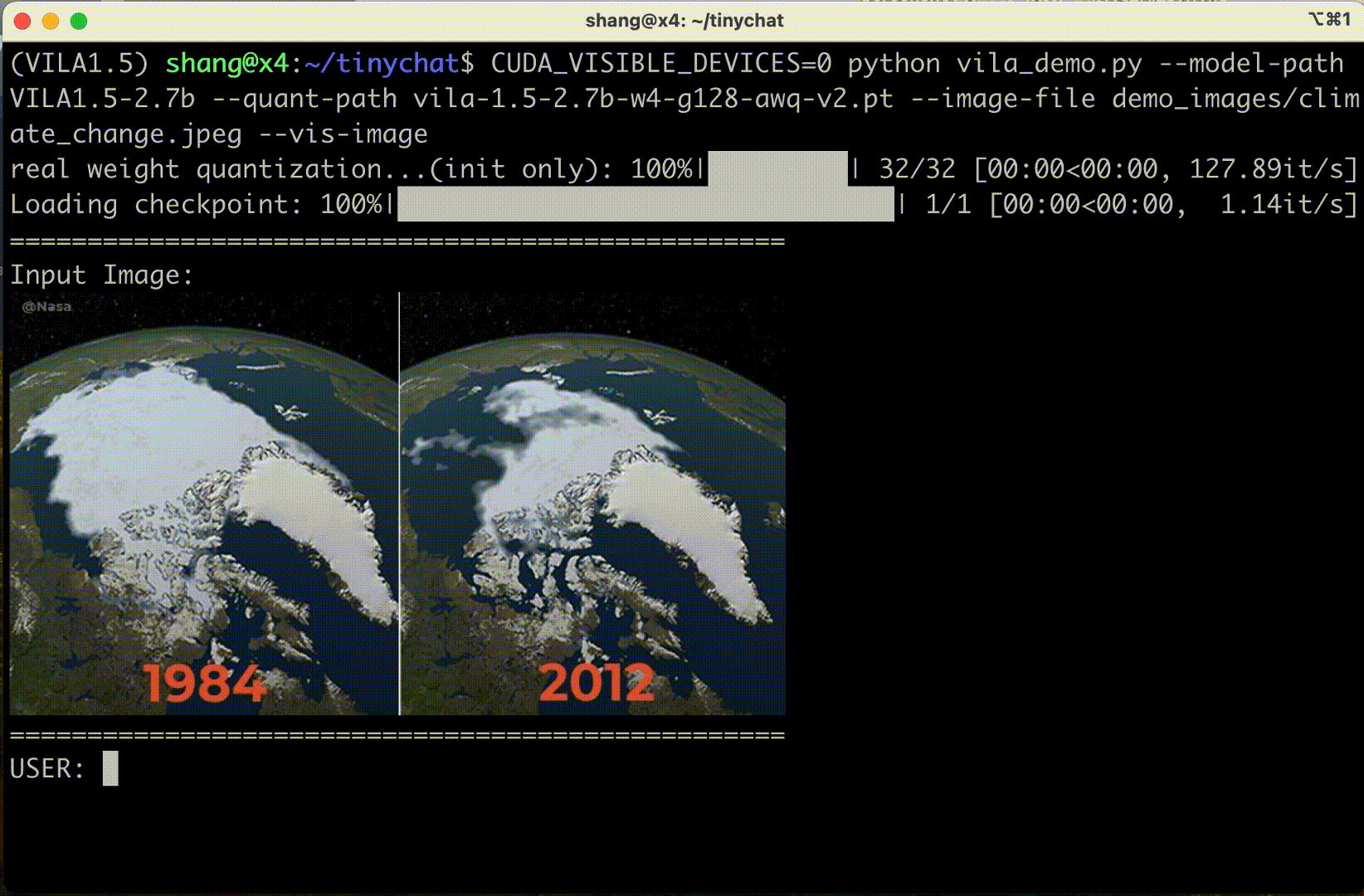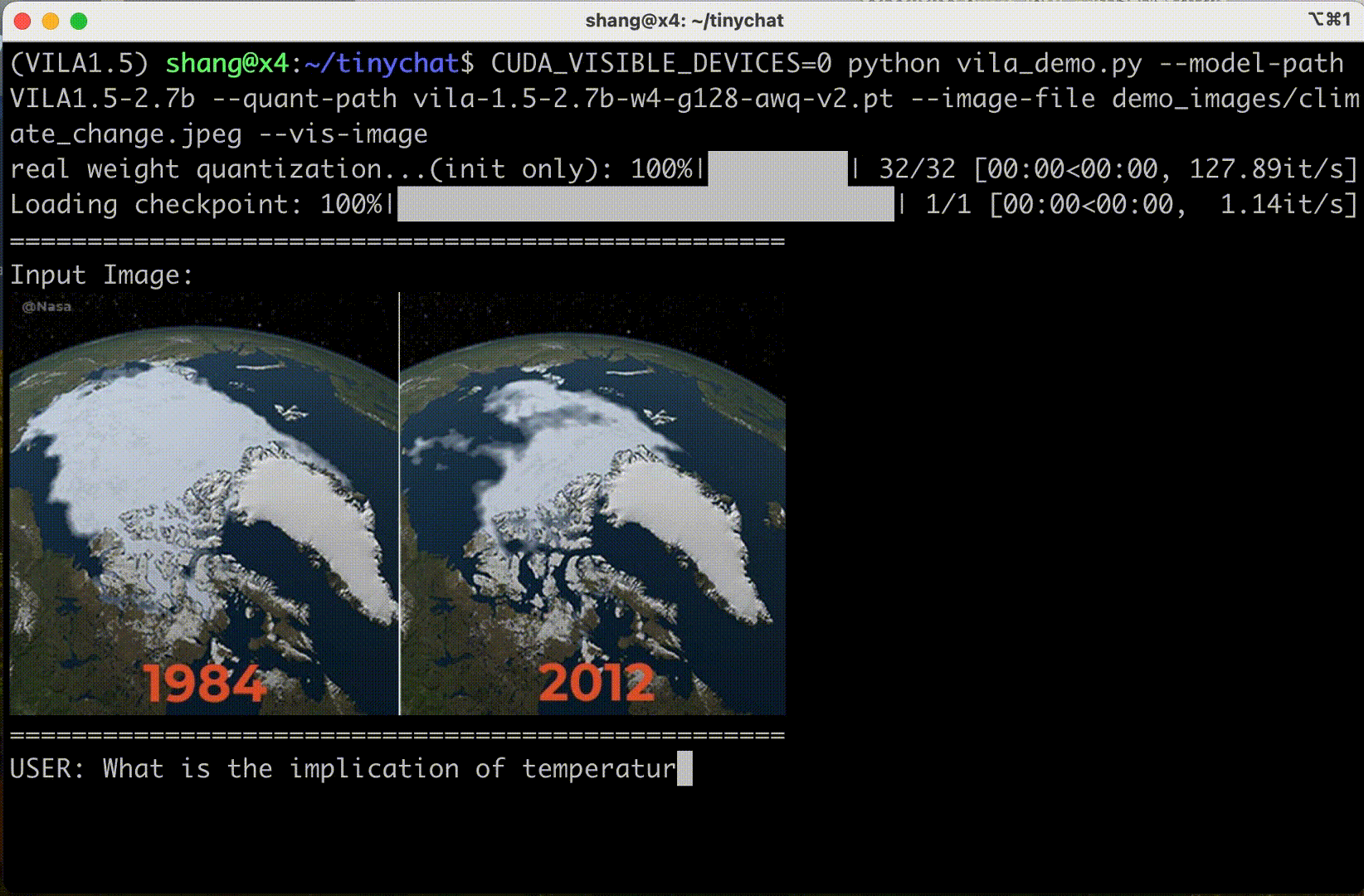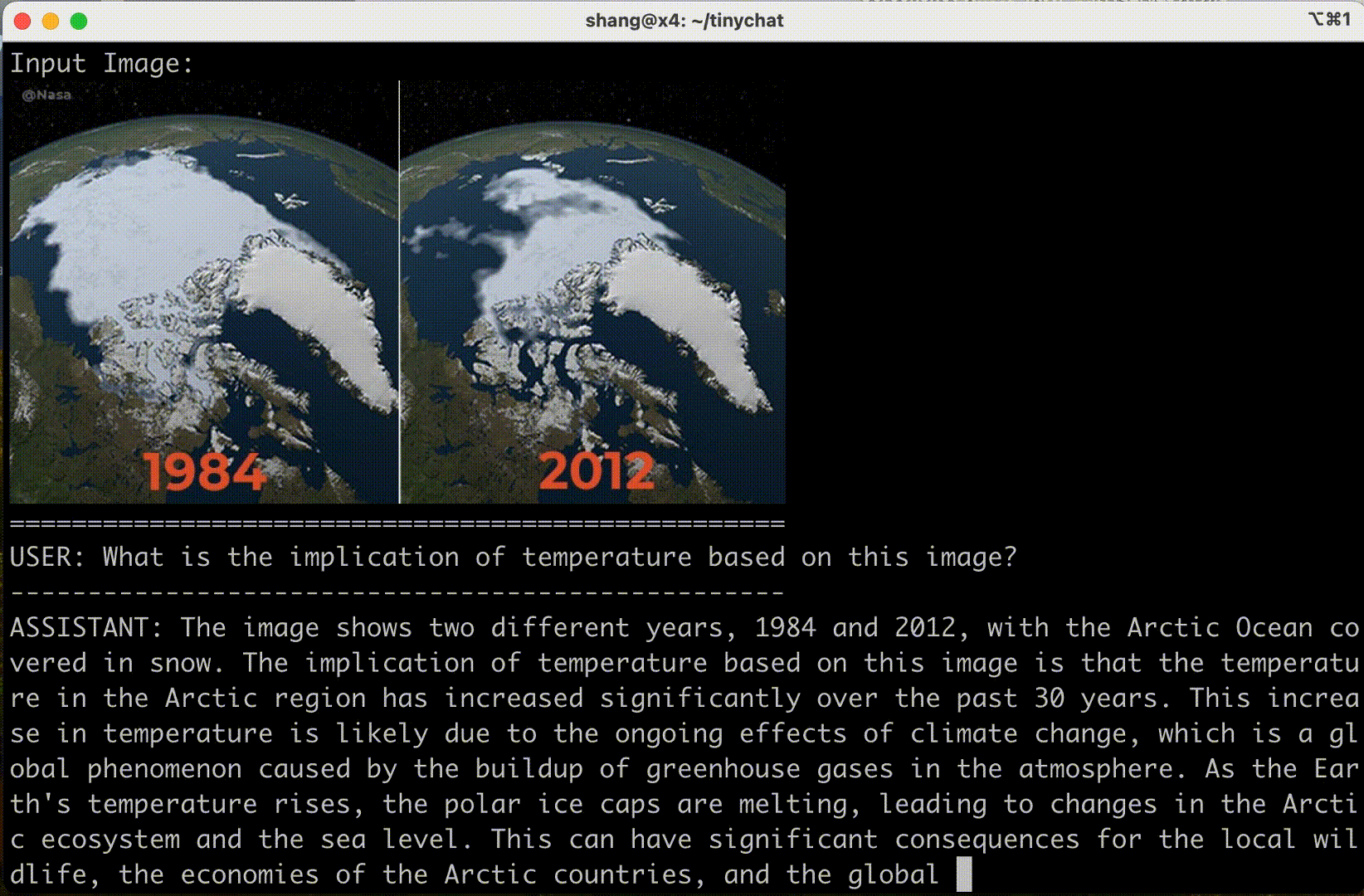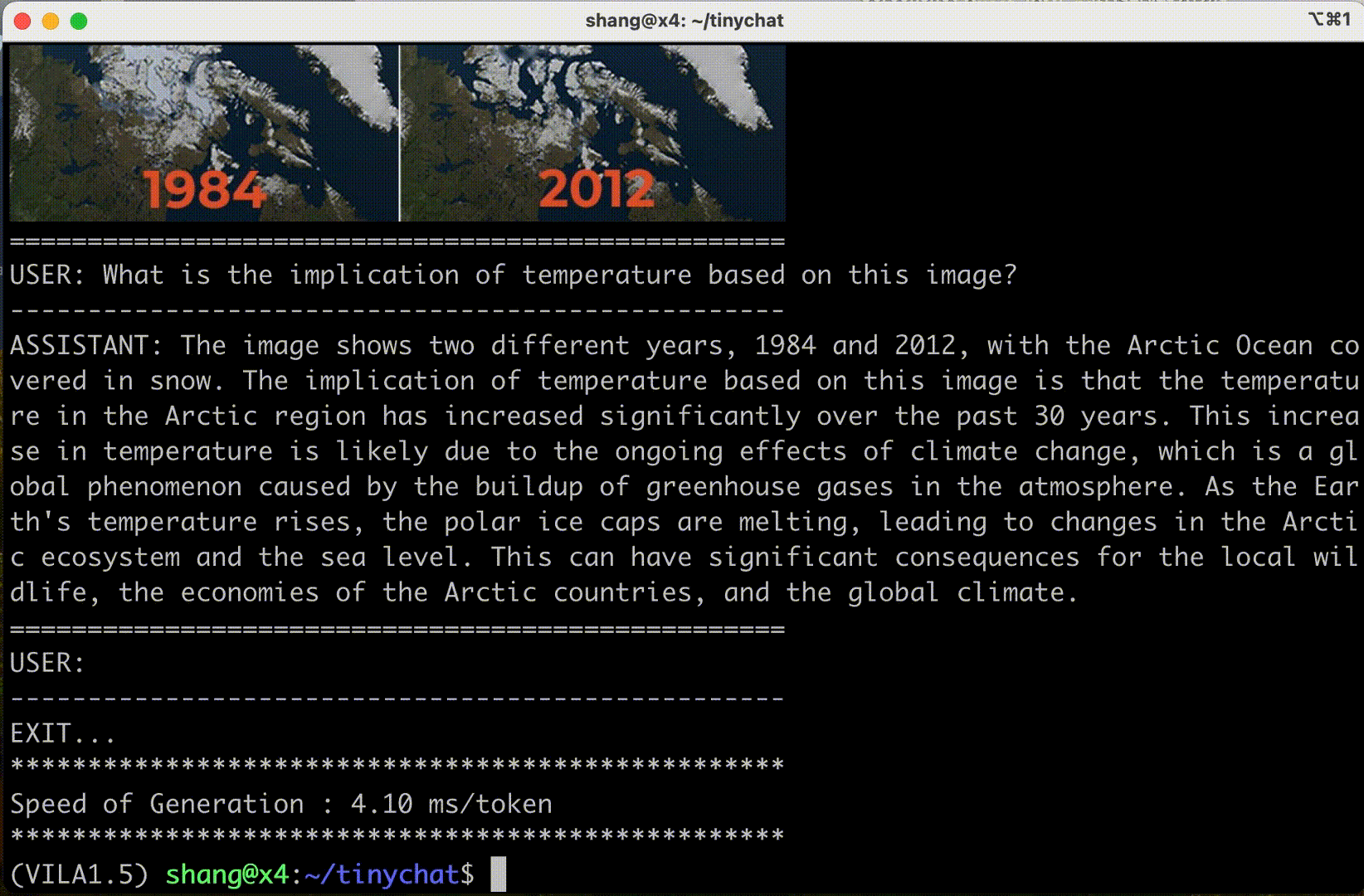
圖 6 顯示 VILA 可以理解圖像序列的內容和順序,為創造性應用開辟了新的途徑。
情境學習?
VILA 還表現出非凡的情境學習能力。在不需要明確的系統提示的情況下,VILA 可以從以前的圖像-文本對無縫地推斷模式,以生成新圖像輸入的相關文本。
在圖 7 中,VILA 成功識別了 NVIDIA 徽標,并與前面示例的樣式相呼應,輸出 NVIDIA 最著名的產品。

開始使用 VILA
我們計劃繼續在 VILA 上進行創新,包括延長上下文長度、提高分辨率,以及為視覺和語言對齊策劃更好的數據集。
有關此模型族的詳細信息,請參見以下資源。
- 要開始使用 VILA,請參閱 GitHub 回購 /Efficient-Large-Model/VILA 。
- 要了解多模式 web UI 的更多信息,您可以使用 Jetson Orin 上運行的 ASR/TTS 與 VILA 對話,請參閱 LlamaSpeak?的指導。
- 有關相機或視頻源上的流式 VILA,請參閱 Live Llava 代理商 tutorial。
欲了解更多關于邊緣生成人工智能的想法,請參閱 Jetson 人工智能實驗室,尤其是以下視頻。
?






