
為了在 2 年內對 100 個大腦進行全人腦細胞級成像以及后續的分析和映射,我們需要加速超級計算和計算工具。NVIDIA 的技術很好地滿足了這一需求,包括硬件、計算系統、高帶寬互連、特定領域的庫、加速工具箱、精心策劃的深度學習模型和容器運行時。NVIDIA 的加速計算涵蓋了 IIT Madras 大腦中心 的解決方案構建、推出、優化、管理和擴展的技術之旅。
如今,對于像蒼蠅這樣的小型昆蟲大腦,以及老鼠和小猴子的大腦,獲取、轉換、處理、分析和解釋的過程已經相當復雜。然而,對于整個人類大腦來說,這些活動規模更大、更復雜,更需要技能和時間。
IITM Brain Centre 的成像管線的關鍵大數據特征是體積 和速度。每個掃描儀的掃描速率為 250 GB/小時,當多個掃描儀同時運行時,該中心每小時能生成 2 TB 的高分辨率未壓縮圖像。所有圖像都必須進行處理,以繪制每個成像單元的地圖。對于計算機視覺物體檢測模型,同等的發生率約為每秒 1 萬個物體。
處理此類大規模的初級神經解剖學數據需要采用數學和計算方法,以揭示在多個時空尺度下控制大腦結構、組織和發展演變的復雜生物學原理。
這項重要且具有挑戰性的科學研究涉及分析精心獲取的細胞分辨率大腦圖像,以對以下內容進行量化描述:
- 空間布局
- 細胞結構
- 神經元路徑
- 分割式組織
- 全腦架構
它擴展到研究所有這些級別的大腦間相似性和關系。
IIT Madras 的新大腦中心已經接受了這一挑戰,正在推動一項大規模的多學科工作,在細胞層面繪制 100 多個人類大腦的地圖。該中心利用其專有技術平臺,對不同類型和年齡的人的死后大腦進行成像。
他們的目標是創建前所未有的細胞分辨率,并對多種類型的人類大腦進行統一研究的數字采集,這些大腦可以從細胞級別到全腦級別進行查詢。這需要每個大腦能夠枚舉 1000 億個神經元,需要超過 100 個大腦,并且能夠連接不同的大腦區域。
滿足細胞分辨率腦成像的計算需求
該中心開發了一個出色的計算平臺,可通過 Web 瀏覽器界面存儲、處理、訪問、處理和可視化此類超過 100 PB 的高分辨率數字人腦數據。
這項工作可能與繪制多個完整行星的地圖有關,通過通過地球體積的高分辨率橫截面成像數據統一研究模式、趨勢和差異。地球表面的衛星圖像將達到 TB,在當今的計算機和 Web 瀏覽器中可以管理大小。這些地理空間渲染技術為 Google 地圖和其他地圖提供支持。
然而,在細胞分辨率下,全腦的容積成像可為每個大腦生成 PB 級的數字數據,這對通過 Web 界面進行可視化、處理、分析和查詢構成了挑戰。
幕后的計算挑戰同樣巨大:
- 人類在環大型圖像數據管道
- 通過索引來自多個并發成像系統的數據實現自動化
- 將圖像傳輸到統一的中央并行文件存儲集群
- 以便于隨機訪問的任意規模的格式進行編碼
- 機器學習模型,適用于檢測組織輪廓等多項自動化任務
- 成像質量控制
- 用于大型圖像歸一化的深度學習任務
- 蜂窩級物體檢測、分類和區域劃分
- 先進的數學模型,用于跨模式和分辨率對圖像進行幾何對齊,然后使用計算幾何來推導量化信息學
- 格式化為大容量快速可檢索的元數據和信息學數據存儲,將令人望而卻步的操作變為可能:按需執行單單元到全腦查詢,并及時回復基于 Web 的交互
要設想這項挑戰的規模,只需查看其中一項任務,這是一項看似合理的物體檢測任務。眾所周知,現代深度學習卷積神經網絡在這項任務中表現出色,在識別和標記物體方面達到了甚至在某些情況下超過了人類水平的能力。
但是,這些模型經過訓練,可以處理包含數十個物體的百萬像素圖像。單單元分辨率的圖像是千兆像素,可以包含數百萬個不同的物體。處理此類大型數據需要專業的計算工作負載。
這就是 Brain Centre 向 NVIDIA 尋求幫助的原因。NVIDIA 是基于 GPU 的行業領導者,已經實施了 HPC 和 DGX A100 系統集群,以完成 10 到 20 個大腦的完整處理。隨著中心擴展到 100 個大腦等,他們希望 DGX SuperPOD 能夠提供可擴展的性能,以及行業領先的計算、存儲、網絡和基礎設施管理。
在 NVIDIA DGX 上的 8 個 NVIDIA A100 Tensor Core GPU,將每個 DGX 節點上檢測細胞的相同數據所需的時間從至少 1 小時減少到不到 10 分鐘。這使得在一個月的時間內進行全腦分析,并擴展到 100 個大腦變得切實可行。
IIT Madras 的杰出校友兼 Infosys 的聯合創始人 Kris Gopalakrishan 說:“我很高興看到 IITM Brain Centre 與 NVIDIA 合作,共同應對分析我們生成的龐大而復雜的細胞級人腦數據的挑戰。他在建立和支持 IITM Brain Centre 方面發揮了關鍵作用。通過與 NVIDIA 這樣的行業領導者合作,我們期待在該領域取得突破,從而產生全球影響。”
解決計算挑戰
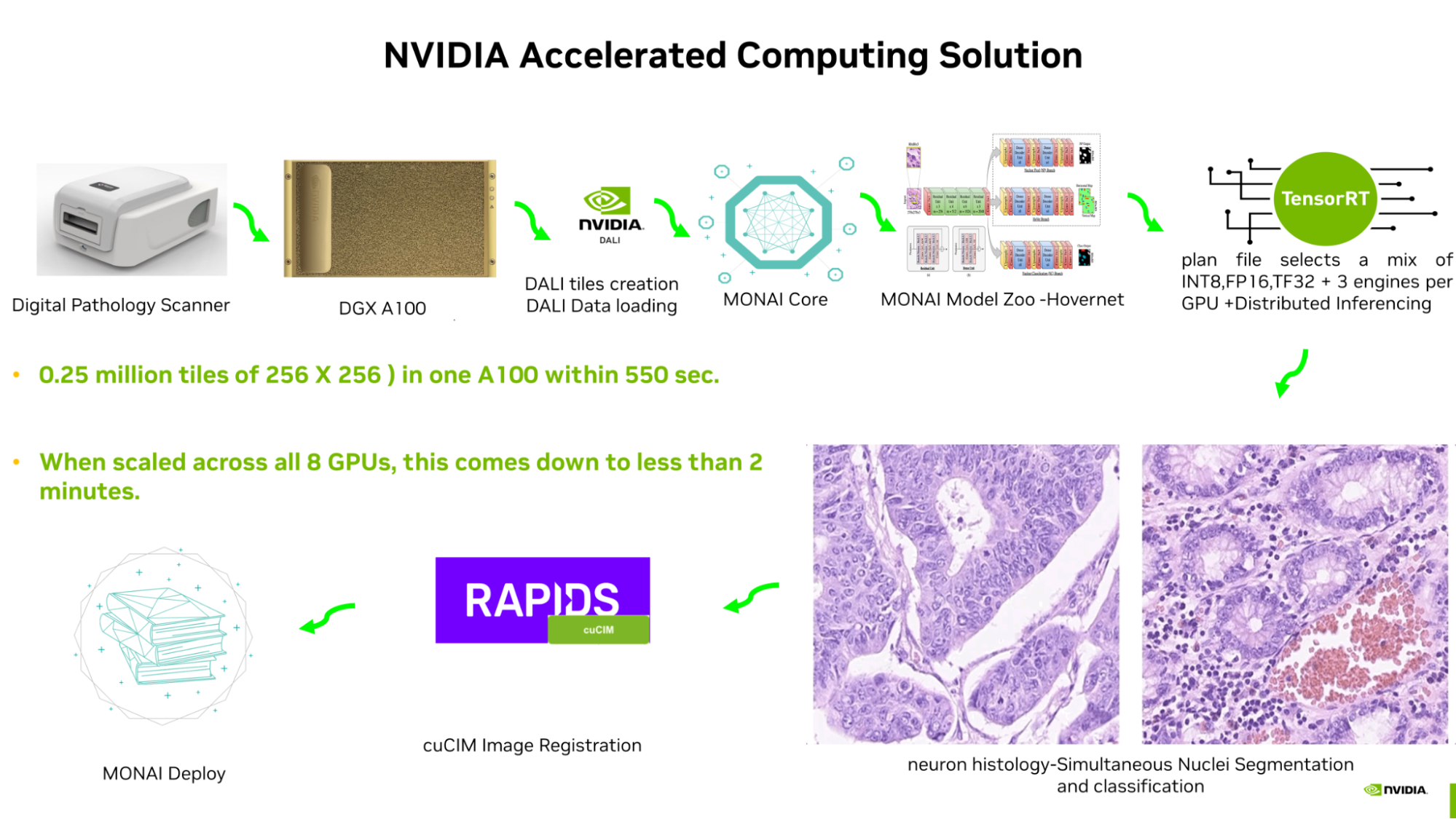
一張包含 25 萬張 256 X 256 圖像的千兆像素全幻燈片圖像在 A100 GPU 上進行推理只需 420 秒。通過使用 NVIDIA 庫和應用程序框架進行端到端流程優化,即可實現:
- 使用 NVIDIA DALI 執行加速的圖塊創建和批處理。
- MONAI Core 模型通過 TensorRT 進行優化。
- TensorRT 計劃文件在網絡的不同部分混合選擇 INT8、FP16 和 TF32,并生成引擎。
- 一個 A100 GPU 中包含三個引擎,用于分布式推理。
- NVIDIA 加速圖像處理庫 cuCIM 用于加速圖像配準。
- NVIDIA IndeX 用于各種縮放級別的多 GPU 立體可視化。不久,MONAI Label 的 AI 輔助注釋以及 NVIDIA 聯合學習 SDK-Flare 將用于進一步優化其他各種 MONAI 核心模型,并將使用 MONAI Deploy 部署流程。
NVIDIA 南亞地區總經理 Vishal Dhupar 表示:“ NVIDIA 技術堆棧使 IIT Madras Brain Centre 的先驅者能夠有效地滿足細胞層面對高分辨率腦成像的計算需求,從而推動國家和全球范圍內的神經科學研究向前發展。
MONAI 和 TensorRT 可用于 NVIDIA AI Enterprise,后者包含在 NVIDIA DGX 基礎架構中。
NVIDIA DGX 系統具有雙 64 核 CPU 和 8 塊 NVIDIA A100 GPU (具有 640GB GPU 顯存),以及 2 TB RAM 和 30 TB 閃存存儲,其計算能力代表了單個 4U 機箱中可用的最高級別服務器計算能力。
此外,DGX 具有可擴展性。 NVIDIA 提供了一個軟件和網絡生態系統,可互連多個 DGX 系統,并滿足 IITM 大腦中心的規模和性能需求,用于處理流水線批作業的數據處理以及按需突發計算。
在對大腦中心數據進行基準測試時,用于 CNN 推理的單個 NVIDIA A100 GPU 的有效處理速率為每小時 60 GB (數據單位為 uint8,推理單位為 FP16 精度),或在五臺 DGX 服務器(40 個 A100 GPU)上的有效處理速率為每小時 2.4 TB,這與當前的成像速率相匹配。這使得成像和計算流程沒有瓶頸。由于 DGX 計算節點具有可擴展性,還可以通過橫向擴展增長來匹配數據流入速率的任何激增。
A100 GPU 主要面向大型數據集和大型模型的深度學習訓練,這些數據集和模型可能不適合較小的 GPU vRAM.在 IITM Brain Centre 中,DGX 系統中的 A100 GPU 以每個 A100 GPU 多引擎的方式用于 CNN 推理,數據在多 GPU 和多節點中映射,以便在五個 DGX 服務器上從 1 – 40 倍擴展。
這使得我們能夠處理可變的圖像大小,這與從胎兒到成年人不同年齡階段的人腦物理大小可變性(比例變化 1 – 32 倍)相對應。此外,DGX A100 系統的 CPU 計算能力和存儲類型在 Brain Centre 的計算管線中得到了很好的應用,可用于 CPU 密集型工作負載、數據訪問或移動密集型工作負載以及遠程可視化。
NVIDIA 技術堆棧以容器運行時的統一格式為流程中的每個步驟提供工具和優化庫,以更輕松地促進采用,并確保最佳實踐和自動化操作。
改變醫學成像領域的深度學習格局
過去,深度學習技術專注于設計最佳方法,或在訓練時進行調優,以逐步提升性能。現在,該技術已轉向使用計算機視覺(物體檢測、語義和全景分割、基于 DL 的圖像注冊)和自然語言等領域經過驗證的基礎模型進行推理。這些結果正在實現以前不適合計算自動化的應用程序。
現在的重點是圍繞由深度學習推理提供動力支持的新應用程序實施軟件護欄。集成的硬件系統和軟件堆棧不僅是朝著這個新方向發展的便利,而且是擴展和簡化的工具。 NVIDIA 技術堆棧是實現解決方案構建、部署和擴展的一種飛躍。
如今,每個人都可以訪問詳細的地球地圖,該地圖已成為一個支持新應用程序和新業務的平臺。它現在可以指導和塑造全球的行動方式。IIT Madras Brain Centre 的工作目標是打造一個類似的變革性平臺,該平臺將在腦科學中產生新的成果,塑造和指導腦部手術和治療,并加深我們對醫學最后前沿 — — 人類大腦的了解。
想要了解更多信息,請訪問 HTIC-Medical-Imaging GitHub 存儲庫。
?






