圖形神經網絡 (GNN) 徹底改變了圖形結構數據的機器學習。與傳統神經網絡不同,GNN 擅長捕捉圖形中的復雜關系,為從社交網絡到化學領域的應用程序提供動力支持。在節點分類和邊鏈預測等場景中,GNN 可預測圖形節點的標簽,并決定節點之間的邊是否存在。
在單個前向或反向通道中處理大型圖形會非常耗費計算資源和內存。
大規模 GNN 訓練的工作流通常從子圖形采樣開始,以便使用 mini-batch 訓練。這包括收集特征,以便在子圖形中捕捉所需的上下文信息。隨后,提取的特征和子圖形將用于神經網絡訓練。在這一階段,GNN 能夠整合信息并實現節點知識的迭代傳播。
但是,處理大型圖形會帶來挑戰。在社交網絡或個性化推薦等場景中,圖形可能包含大量節點和邊緣,每個節點都攜帶大量特征數據。
節點特征數據每個頂點的大小可能達到幾千字節,因此節點特征數據的總大小可以輕松超過圖形拓撲數據的大小。對于大型工作負載而言,有時需要使用大容量 (key,value) 存儲。
本文介紹了 RAPIDS cuGraph 庫中的新功能 WholeGraph.WholeGraph 是一種類型的圖形存儲,可與 PyG、cuGraph-PyG、DGL、cuGraph-DGL,和 cuGraph-Ops 來加速大規模 GNN 訓練。
為什么選擇 WholeGraph?
WholeGraph 提供由多個內存 (例如固定主機內存和設備內存) 支持的大容量、高性能存儲抽象,這種靈活性使得 WholeGraph 能夠使用適用于特定任務或系統配置的合適內存類型優化性能。
WholeGraph 存儲可跨多個節點的多個 GPU 覆蓋。遠程內存訪問使用 NVIDIA NVLink P2P 內存訪問或使用 NCCL 進行批量傳輸。
此外,借助本地 PyTorch 支持和與 torch DistributedDataParallel 模式的兼容性,WholeGraph 可在多個 GPU 上高效分配訓練流程,從而增強大規模圖形數據集的可擴展性和內存優化。
WholeGraph 的作用
WholeGraph 旨在幫助訓練大規模 GNN.WholeGraph 提供了一種名為 WholeMemory 的底層存儲結構 .WholeMemory 是一種類似于張量的存儲結構 .WholeMemory 可以高效地組織和操作多維數據,類似于深度學習框架中的張量。
此外,它還提供多 GPU 支持,因此非常適合 NVIDIA DGX A100 服務器等 NVLink 系統。通過使用 cuGraph、cuGraph-Ops、cuGraph-DGL、cuGraph-PyG、上游 DGL 和 PyG,您可以輕松構建 GNN 應用。
WholeMemory
WholeMemory 可視為多個 GPU 上顯存的完整 (即整體) 視圖。無論底層數據如何存儲在多個 GPU 上,WholeMemory 都會公開顯存實例的把握。
因為多個 GPU 共享 WholeMemory,因此每個 GPU 都需要訪問 WholeMemory 空間,因此必須進行地址映射 .WholeMemory 提供三種地址映射模式:連續、分塊和分布式。
連續模式:每個 GPU 的所有顯存都會映射到每個 GPU 的單一連續顯存地址空間中。GPU 可以使用單個指針和偏移來直接訪問顯存,就像使用常規設備顯存一樣。軟件無法區分這種模式。硬件將處理 P2P 顯存訪問所需的通信。
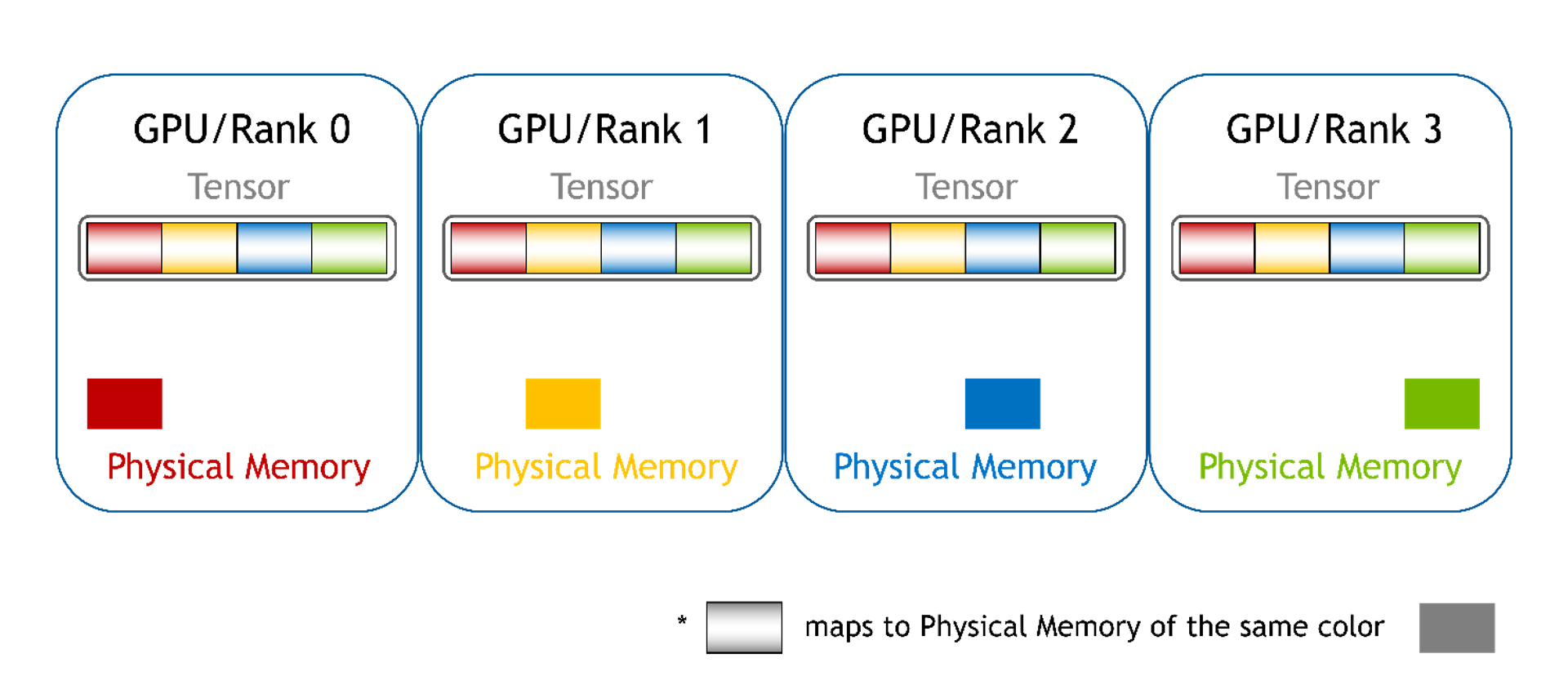
分塊:每個 GPU 的顯存都映射到不同的顯存塊中,每個 GPU 都有一個塊。對于 PyTorch,這可以是一個張量列表。在此,我們仍然可以使用指針和偏移來訪問數組元素,但是有多個指針 (每個塊有一個指針)。用戶必須根據全局偏移來選擇正確的指針,并且必須為選擇的顯存塊計算新的本地偏移值。
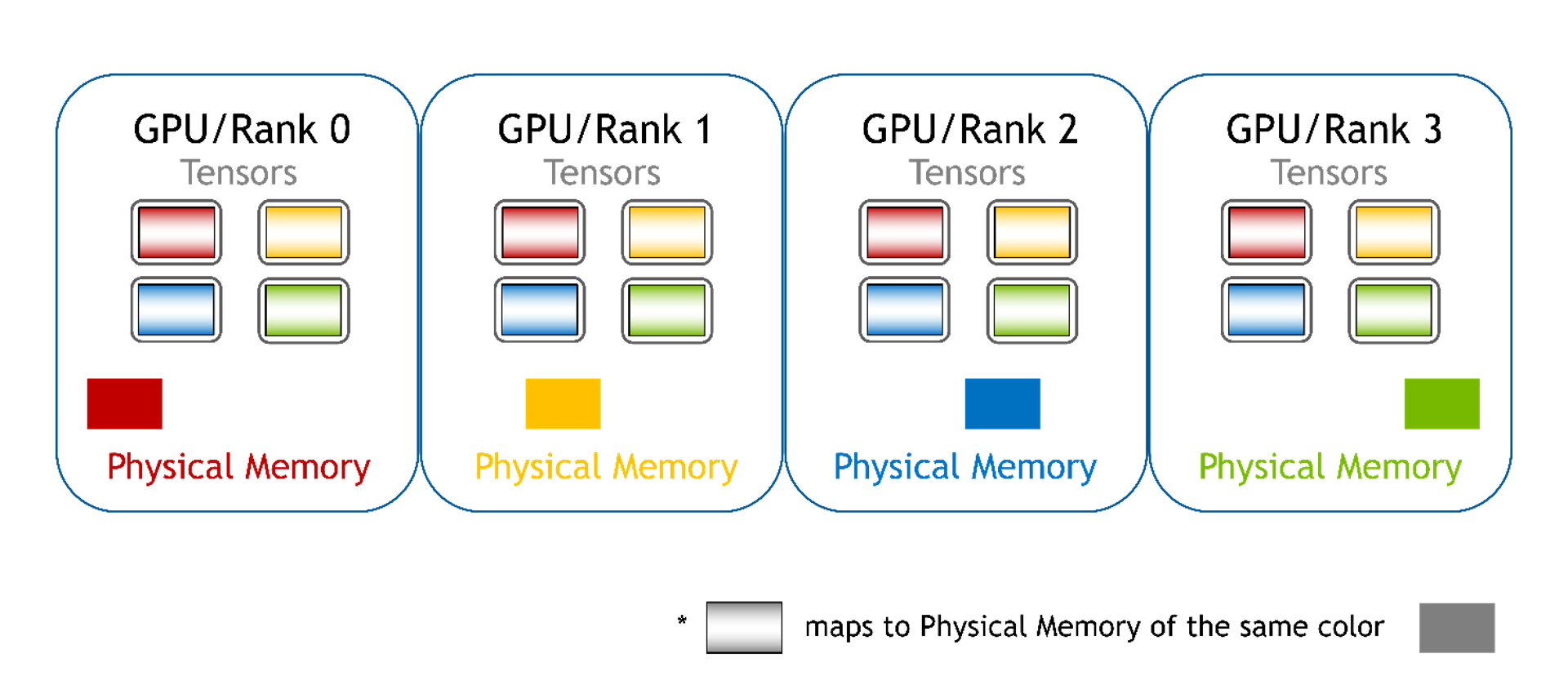
分布式:其他 GPU 的內存未映射到當前 GPU,也不支持直接訪問。在此模式下,用戶無法再使用指針訪問數組元素,必須使用 WholeMemory 提供的函數訪問數組元素。此類 WholeMemory 模式可用于創建多節點存儲。
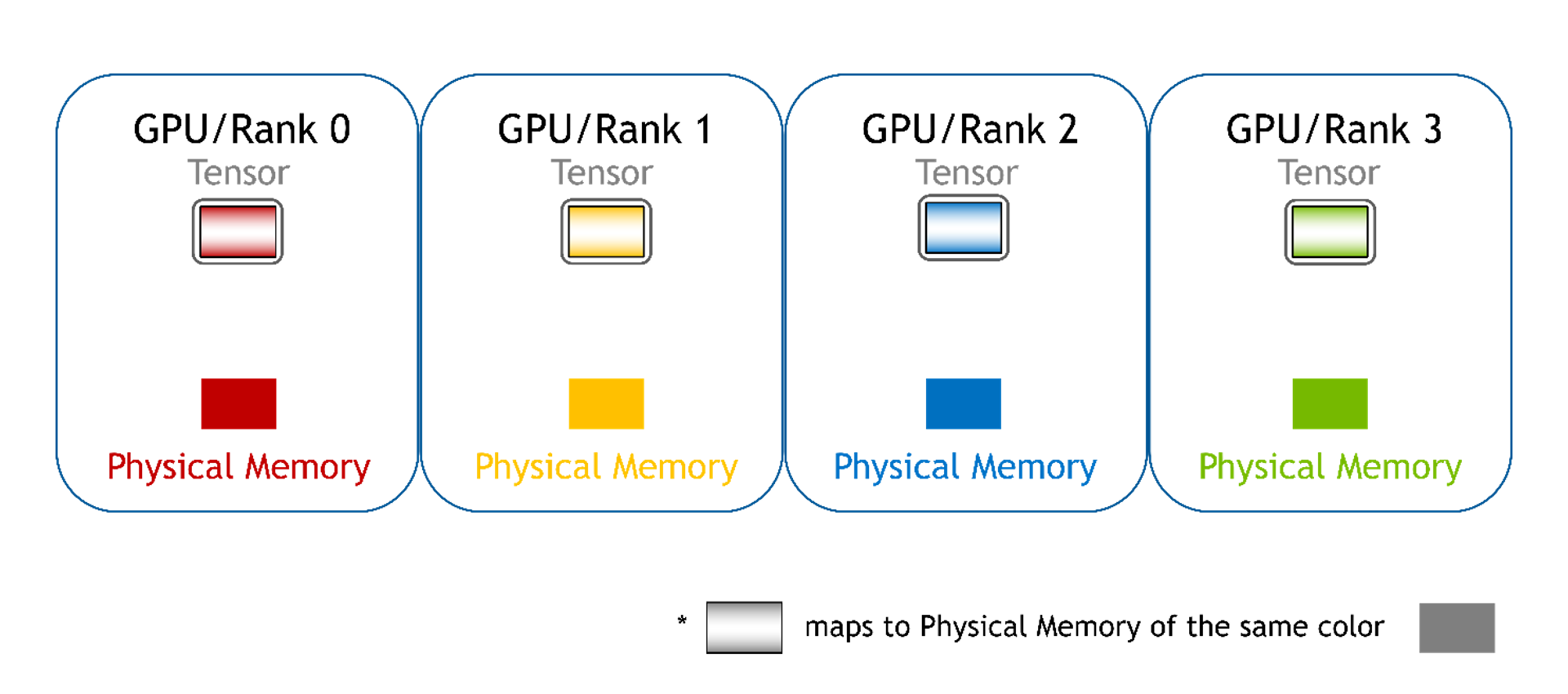
總而言之,連續模式提供簡單的內存訪問,塊模式提供了高效管理內存的方法,而分布式模式允許多節點存儲,但需要額外協調來訪問跨 GPU 的數據。每種模式都有自己的優缺點,具體取決于應用程序和系統配置的特定要求。
除了使用 GPU 顯存,WholeMemory 還支持使用固定主機顯存。主機顯存可以通過兩種方式進行固定:一種是連續固定,允許多個進程共享相同的顯存;另一種是分布式固定,適用于跨多個節點運行的應用。
WholeMemory 嵌入
與大規模 GNN 訓練類似,收集節點特征需要耗費大量時間。此外,在可訓練特征的節點特征 (嵌入) 數據中,需要讀取和寫入訪問。為了幫助加速特征收集或更新可訓練特征,WholeGraph 為特征存儲引入了 WholeMemory 嵌入。
與 WholeMemory Tensor 對象相比,WholeMemory Embedding 具有以下兩個額外特性:
- 首先,WholeMemory Embedding 支持緩存。它可以在多 GPU 或多節點運行中在本地 GPU 或本地節點中存儲常用特征。或者,它可以在設備內存中存儲主機存儲。
- 第二個特性是對可訓練特征的稀疏優化器的支持。借助稀疏優化器,僅會更新受影響的特征,從而加快訓練過程。
WholeMemory 框架集成
盡管幾乎所有功能都以 Python 對象或函數的形式公開,但與深度學習框架無縫集成可為開發者提供便利,因此 WholeMemory 提供了 dlpack capsule,可將 WholeMemory 對象轉換為適用于深度學習框架的張量。支持的轉換方法取決于 WholeMemory 的地址映射模式類型。
- 對于分布式全內存,無法映射至遠程內存。僅可將本地內存轉換為 dlpack capsule,然后轉換為深度學習 (DL) 框架的張量。
- 對于分塊的全內存,可以映射至遠程內存。從所有秩中的內存塊可以轉換為一個 dlpack 容器列表,并導入到 DL 框架中作為一個張量列表。
- Continuous WholeMemory 具有完整的功能,并且將內存映射到單個連續內存地址空間中。這可以轉換為單個 dlpack capsule,并通過 DL 框架作為單個張量導入。張量與 DL 框架中的其他張量幾乎相同,但存儲在多個 GPU 上。張量由多個進程共享,并且可以非常大。
入門指南
首先,您需要安裝 WholeGraph 軟件包,可以使用 conda 進行安裝,也可以從源代碼安裝
安裝
若要使用 conda 進行安裝,只需運行:
> conda install -c rapidsai pylibwholegraph |
要從源代碼構建,首先,從 GitHub 獲取代碼:
> git clone https://github.com/rapidsai/wholegraph.git |
接下來,前往 WholeGraph 目錄并運行 build.sh 腳本。該腳本將從源中構建并安裝在該包中。請務必確保所有要求已安裝為文檔。
> cd wholegraph> bash build.sh |
使用 WholeGraph
在討論使用 WholeGraph 的場景時,我們將以 1.11 億篇論文的 ogbn-papers100M 數據集為例。該數據集由 Microsoft Academic Graph 提供,每個節點都包含了 128 維的特征嵌入。在這個示例中,WholeGraph 用于存儲特征嵌入表。
要使用 WholeGraph,我們必須將數據轉換為 WholeGraph 讀取的二進制格式。假設特征嵌入位于名為 feat_array 的 numpy 數組中,則可以通過以下命令完成:
…with open('feat_data.bin', 'wb') as f: feat_array.tofile(f) |
數據存儲在名為feat_data.bin我們可以使用 WholeGraph 加載該數據集并訓練 GNN 模型 .ogbn-papers100M 數據集的完整預處理腳本可以在 GitHub 中找到。
在使用 WholeGraph 之前,需要初始化 WholeGraph 多進程環境:
import pylibwholegraph.torch as wgthwgth. init_torch_env(world_rank, world_size, local_rank, local_size) |
下一步是創建一個定義創建 WholeMemory 所使用的 GPU 集的通信器。例如,在本地計算機節點上創建一個通信器,包含所有 GPU:
local_comm = get_local_node_communicator() |
初始化 WholeGraph 多進程環境和創建通信器的兩個步驟可以合并為一個調用,從而創建兩個最常用的通信器。一個是本地機器節點上的所有 GPU 通信器,另一個是所有機器節點上的所有 GPU 通信器。
global_comm, local_comm = wgth.init_torch_env_and_create_wm_comm( world_rank, world_size, local_rank, local_size) |
然后,可以創建 WholeMemory 嵌入,以存儲節點特征。以下代碼片段在本地計算機節點的所有 GPU 上創建嵌入表。在本例中,WholeMemory 類型是分塊。我們不需要緩存或稀疏優化器,因此不需要指定相關參數。
node_feat_wm_embedding = wgth.create_embedding_from_filelist( local_comm, "continuous", "cuda", os.path.join(node_feat_path, "node_feat.bin"), torch.float, 128 |
創建 WholeMemory 嵌入后,我們使用 gather 方法來收集特征。indices和gathered_feature都是 PyTorch 張量。
gathered_feature = node_feat_wm_embedding.gather(indices) |
除了使用 WholeMemory Embedding 對象外,我們還可以通過調用 WholeMemory Embedding 的 get_embedding_tensor 方法獲取 WholeMemory Tensor 對象:
node_feat_wm_tensor = node_feat_wm_embedding. get_embedding_tensor() |
不同類型的 WholeMemory 張量可以映射到 PyTorch 張量或張量。
例如,連續 WholeMemory Tensor 可通過以下方式映射到單個 PyTorch Tensor:
node_feat_pytorch_tensor = node_feat_wm_tensor. get_global_tensor() |
在這里,node_feat_pytorch_tensor是 PyTorch Tensor,任何 PyTorch 運算符都可以直接使用它,而底層存儲可能是多個 GPU 上的內存。
WholeMemory 嵌入表都可以用于 GNN 訓練,GitHub。
總結
WholeGraph 提供了簡單的實施方式,通過更少的代碼更改簡化了多 GPU 或多節點存儲設置。此外,RAPIDS 團隊還在 WholeGraph 中不斷添加新功能并優化性能,歡迎閱讀此博客文章,詳細了解 WholeGraph 的基準測試,用于收集功能和 GNN 端到端訓練任務。
您可以通過以下鏈接訪問WholeGraph GitHub,并可以在該頁面提交問題和問題。
?