
三個趨勢繼續推動著人工智能推理市場的訓練和推理:不斷增長的數據集,日益復雜和多樣化的網絡,以及實時人工智能服務。 MLPerf 推斷 0 . 7 是行業標準 AI 基準測試的最新版本,它解決了這三個趨勢,為開發人員和組織提供了有用的數據,以便為數據中心和邊緣的平臺選擇提供信息。
基準測試擴展了推薦系統、語音識別和醫學成像系統。它已經升級了自然語言處理( NLP )的工作負載,以進一步挑戰測試中的系統。下表顯示了當前的一組測試。有關這些工作負載的更多信息,請參閱 MLPerf 公司。 GitHub repo 。
| Application | Network Name |
| Recommendation* | DLRM (99% and 99.9% accuracy targets) |
| NLP* | BERT (99% and 99.9% accuracy targets) |
| Speech Recognition* | RNN-T |
| Medical Imaging* | 3D U-Net (99% and 99.9% accuracy targets) |
| Image Classification | ResNet-50 v1.5 |
| Object Detection | Single-Shot Detector with MobileNet-v1 |
| Objection Detection | Single-Shot Detector with ResNet-34 |
*新工作量
此外,針對數據中心和邊緣的多個場景進行了基準測試:
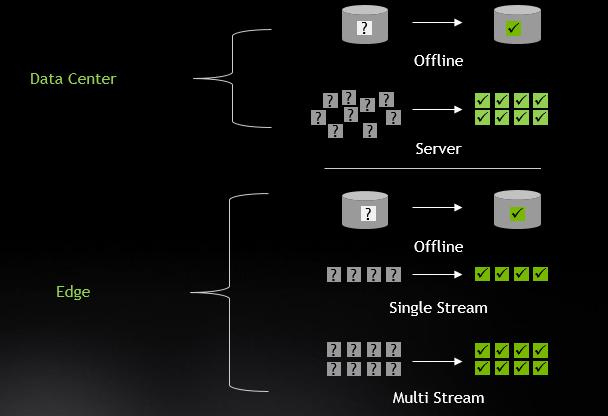
NVIDIA 輕松贏得了數據中心和邊緣類別的所有測試和場景。雖然這種出色的性能大部分可以追溯到我們的 GPU 體系結構,但更多的是與我們的工程師所做的出色的優化工作有關,現在開發人員社區可以使用這些工作。
在這篇文章中,我深入研究了導致這些優秀結果的因素,包括軟件優化以提高執行效率,多實例 GPU ( MIG )使一個 A100GPU 最多可以作為七個獨立的 GPUs 運行,以及 Triton 推斷服務器 支持在數據中心規模輕松部署推理應用程序。
檢查的優化
NVIDIA GPUs 支持 int8 和 FP16 的高吞吐量精確推斷,因此您可以在默認情況下獲得出色的推斷性能,而無需任何量化工作。然而,在保持精度的同時將網絡量化到 int8 精度是最高的性能選項,可以使數學吞吐量提高 2 倍。
在本次提交的資料中,我們發現 FP16 需要滿足 BERT 的最高精度目標。對于這個工作負載,我們使用了我們的 FP16 張量核心。在其他工作負載中,我們使用 int8 精度達到了最高精度目標( DLRM 和 3D Unet 的 FP32 的 99 . 9% 以上)。此外, int8 提交的性能得益于 TensorRT 7 . 2 軟件版本中的全面加速。
許多推斷工作負載需要大量的預處理工作。 NVIDIA 開源 DALI 庫旨在加速對 GPU 的預處理并避免 CPU 瓶頸。在本文中,我們使用 DALI 實現了 RNN-T 基準的 wav 到 mel 的轉換。
NLP 推斷對具有特定序列長度(輸入中的單詞數)的輸入文本進行操作。對于批處理推理,一種方法是將所有輸入填充到相同的序列長度。但是,這會增加計算開銷。 TensorRT 7 . 2 增加了三個插件來支持 NLP 的可變序列長度處理。我們提交的 BERT 使用這些插件獲得了超過 35% 的端到端性能。
加速稀疏矩陣處理是 A100 中引入的一種新功能。稀疏化網絡確實需要重新訓練和重新校準權值才能正常工作,因此稀疏性在封閉類別中不是可用的優化,但在開放類別中是允許的。我們的開放類別 BERT 提交使用稀疏性實現了 21% 的吞吐量提高,同時保持了與封閉提交相同的準確性。
了解 MLPerf 中的 MIG
MIG 內存。 MIG 允許您選擇是將 A100 作為單個大的 GPU 操作,還是將多個較小的 GPU 作為一個單獨的大型 GPU 來運行,每個小的 GPU 可以在它們之間隔離的情況下為不同的工作負載提供服務。圖 2 顯示了將此技術用于測試的 MLPerf 結果。
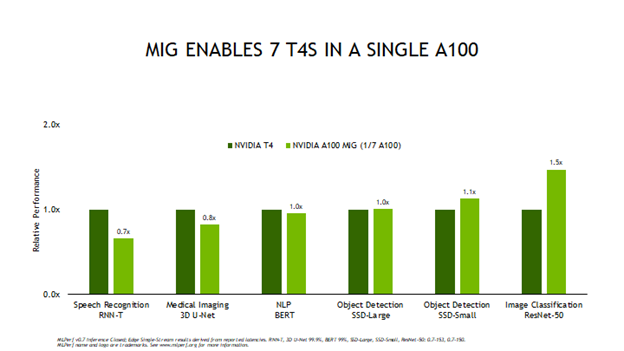
圖 2 比較了單個 MIG 實例與完整的 T4GPU 實例的邊緣脫機性能,因為 A100 最多可支持七個 MIG 實例。您可以看到,超過四個 MIG 測試結果得分高于完整的 T4GPU 。這對應用程序意味著,您可以加載一個包含多個網絡和應用程序的單個 A100 ,并以與 T4 相同或更好的性能運行每個網絡和應用程序。這樣可以減少部署的服務器數量,釋放機架空間,并降低能耗。此外,在單個 A100 上同時運行多個網絡有助于保持 GPU 的高利用率,因此基礎設施管理人員可以優化使用已部署的計算資源。
Triton 推斷服務器
在一個網絡經過訓練和優化之后,它就可以部署了,但這并不像打開交換機那么簡單。在一個以人工智能為動力的服務上線之前,有幾個挑戰需要解決。這包括提供適當數量的服務器來維護 sla ,并確保在 AI 基礎設施上運行的所有服務都有良好的用戶體驗。然而,“正確的數字”可能會隨著時間的推移或由于工作量需求的突然變化而改變。理想的解決方案還可以實現負載平衡,從而使基礎設施得到最佳利用,但不會出現超額訂閱。此外,一些管理者希望在單個 GPUs 上運行多個網絡。 Triton 推斷服務器解決了這些挑戰和其他問題,使基礎設施管理人員更容易部署和維護負責提供人工智能服務的服務器群。
在這一輪中,我們也使用 Triton 推理服務器提交了結果,這簡化了人工智能模型在生產中的大規模部署。這個開源推理服務軟件允許團隊從任何框架( TensorFlow 、 TensorRT 、 PyTorch 、 ONNX 運行時或自定義框架)部署經過訓練的 AI 模型。它們還可以從本地存儲、 Google 云平臺或 Amazon S3 部署在任何基于 GPU – 或 CPU 的基礎設施(云、數據中心或邊緣)上。
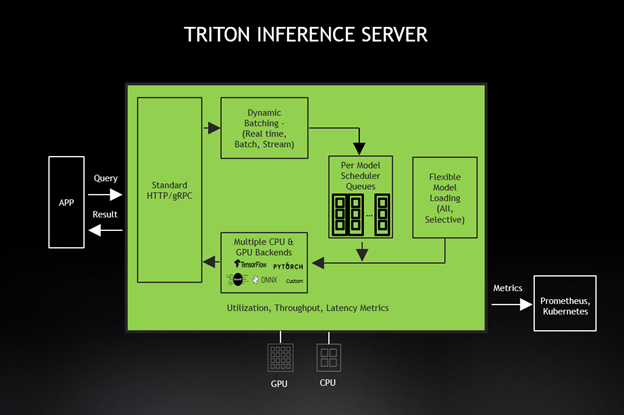
Triton ?聲波風廓線儀也可作為 Docker 容器提供,是為基于微服務的應用而設計的。 Triton ?聲波風廓線儀與 Kubernetes 緊密集成,實現動態負載平衡,保證所有網絡推理操作順利進行。 Triton ?聲波風廓線儀的 GPU 指標幫助 Kubernetes 將推斷工作轉移到可用的 GPU 上,并在需要時擴展到數百個 GPUs 。新的 Triton ?聲波風廓線儀 2 . 3 支持使用 KFServing 的無服務器推斷、 Python 自定義后端、用于會話式人工智能的解耦推理、支持 A100MIG 以及 Azure ML 和 DeepStream 5 . 0 集成。
圖 4 顯示了 Triton ?聲波風廓線儀與運行 A100 定制推理服務解決方案相比的總體效率,這兩種配置都使用 TensorRT 運行。
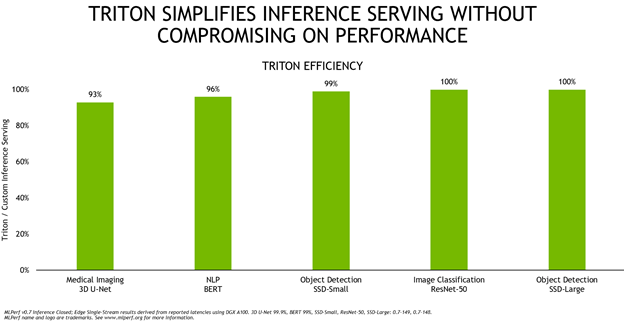
Triton ?聲波風廓線儀的效率很高,在這五個網絡中提供同等或接近它的性能。為了提供這樣的性能,該團隊對 Triton ?聲波風廓線儀進行了許多優化,例如用于與應用程序進行低延遲通信的新的輕量級數據結構、用于改進動態批處理的批處理數據加載以及用于 TensorRT 后端的 CUDA 圖形以獲得更高的推理性能。這些增強功能可作為 20 . 09 Triton ?聲波風廓線儀集裝箱 的一部分提供給每個應用程序。除此之外, Triton ?聲波風廓線儀還簡化了部署,無論是在本地還是在云端。這使得所有網絡推斷都能順利進行,即使在意外的需求高峰來襲時也是如此。
加速推理應用程序
考慮到驅動人工智能推理的持續趨勢, NVIDIA 推理平臺和全棧方法提供了最佳性能、最高通用性和最佳可編程性, MLPerf 推理 0 . 7 測試性能證明了這一點。現在,您和開發人員社區的其他成員都可以使用這些成果,主要是以開源軟件的形式。此外, TensorRT 和 Triton 推理服務器可從 NVIDIA NGC 免費獲得,以及預訓練模型、深度學習框架、行業應用框架和頭盔圖。 A100GPU 已經證明了其充分的推理能力。隨著完整的 NVIDIA 推理平臺, A100GPU 已經準備好迎接最嚴峻的人工智能挑戰。
?






