在游戲應用程序性能方面,GPU 驅動的渲染能夠提升處理大型虛擬場景的可擴展性。Direct3D 12 (D3D12) 采用工作圖形(work graph)編程范式,允許 GPU 在運行時生成自己的工作。有關工作圖形的介紹,請參閱 在 Direct3D 12 中使用工作圖推進 GPU 驅動的渲染。
本文介紹了一個 Direct3D 12 工作圖形案例研究。我將介紹通過工作圖形的高效著色器代碼選擇和執行,常見延遲著色渲染算法如何從中受益。然后,我將從此案例研究中探索工作圖形的更高級主題、學習內容和建議。
工作圖形選擇性著色器代碼執行
相較于ExecuteIndirectDirect3D 12 (D3D12) API 中的工作圖形具有在微觀級別動態選擇和啟動著色器的獨特功能。例如,考慮將屏幕劃分為小塊。對于每個小塊,必須執行某種操作,具體取決于該小塊的內容。假設每個小塊有 10 種可能性。您可以使用三種不同的方法來完成此操作:
- 使用帶有大型著色器的 Uber 著色器
switch/case塊,其中包含所有可能的代碼。 - 出現全屏問題
Dispatch運行專門針對每種可能性的著色器。著色器首先確定塊是否即將與著色器進行匹配。如果不是,著色器會立即退出。 - 首先,使用一個識別矩形塊并計算每種可能性的矩形塊數量的過程,然后使用
ExecuteIndirect以便讓 GPU 調整每個調度的網格大小。
每種方法都有其缺點。對于第一種方法,超級著色器通常會導致寄存器文件中的浪費,這是因為必須讓變量保持活動狀態,即使它們不用于特定的執行路徑,因此會降低占用率。此外,分支還會產生一些成本。switch/case塊。
第二種方法會浪費大量計算線程,以便涵蓋所有可能性。第三種方法聽起來最有效,但它缺少了前兩種方法中不存在的分類步驟。
工作圖形提供了更精美的解決方案。下面的案例研究將展示如何使用推薦和有用的工具進行調試。
多 BRDF 延遲著色案例研究
延遲著色是在游戲引擎中管理光照和材質交互的一種常見技術。通常,場景中的網格會被光柵化成一個胖 G 緩沖區,該緩沖區存儲每個像素的著色參數 (例如,法線、反射率和粗糙度)。然后,一個跟隨光照過程的光照過程會從 G 緩沖區獲取信息,并將其應用于內容,以產生照亮的像素并將其存儲在 HDR 格式的顏色緩沖區中。
光照過程本身通常附帶一些加速結構,使著色器只考慮影響下方像素的光源,而不是檢查整個場景中的所有光源。
只要場景中的所有材質使用相同的雙向反射分布函數 (BRDF),即可正常工作,但這可能會對藝術造成限制。為了支持多個 BRDF (例如,清漆、眼睛或頭發),可以在 G-buffer 中添加額外參數,以指示每個像素的 BRDF。此外,照明通道必須使用switch/case這個 BRDF 值,因此它知道如何計算材質與光線的相互作用。這聽起來很熟悉嗎?
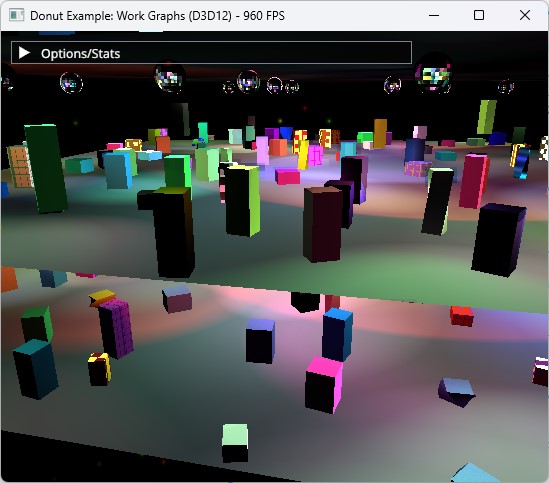
我構建了一個基于此用例的示例,以探索工作圖可以如何幫助。完整文檔的示例代碼實現了多 BRDF 延遲著色渲染器,可通過 NVIDIAGameWorks/donut_examples 獲取。它展示了兩種方法:uber 著色器和工作圖。
此示例使用精簡的 G 緩沖區布局,該布局僅存儲常規和材質 ID,而非所有材質參數。這對于多 BRDF 材質非常合適,因為每種 BRDF 都可以有不同的參數集來表示材質。在著色過程中,使用材質類型來確定材質參數提取和評估的邏輯。
場景由多個舞臺組成,每個舞臺上都有由動畫立方體組成的人群。天花板上充滿了反射球,它們會在每個舞臺上投射移動光線。各種顏色的移動聚光燈也照亮了場景。
此場景完全采用程序化方式生成和動畫。幾個控件管理場景復雜性 (網格數量、光線和材質)。材質可以使用一種幾種類型 (或 BRDF),以某種方式渲染 (例如,Lambert、Phong、Metallic 或 Velvet)。
慢慢調整代碼并嘗試不同的場景參數,以了解這些更改對性能的影響。
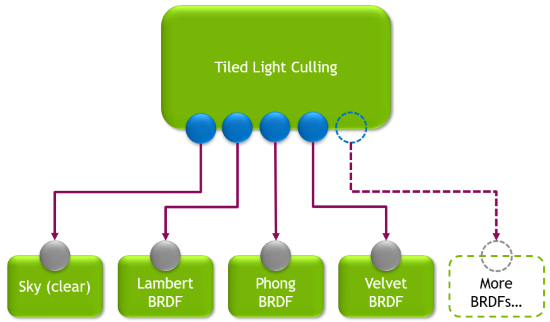
標準延遲著色計算通道使用兩個計算分配:
- 瓷磚光線剔除:屏幕被劃分為每個 8×4 像素的小塊。對于每個小塊,所有影響該小塊的光線都會被收集并存儲在緩沖區中。
- 使用超級著色器進行延遲著色:每塊瓷磚都會再次處理,這次使用瓷磚收集的光線。所有瓷磚中發現的材質都會在超級著色器中進行評估。
最重要的是,此示例使用工作圖實現了相同的延遲著色通道。
工作圖技術完全取代了之前提到的兩個步驟。相反,圖形使用廣播啟動節點來復制同樣的光板剪切概念。圖形的根節點執行于每個屏幕矩形,節點為矩形剪切光線,并將結果存儲在記錄中以發送到圖形的下一步。
根節點可以選擇一個包含多個輸出的數組,每個輸出都專門用于某種 BRDF (或屏幕清除)。剔除光線列表放置在圖形中的正確節點中,該節點可以處理瓷磚中的材質類型。在包含多個不同的 BRDF 的情況下,根節點會生成多個記錄,以便使用所有正確的節點覆蓋相同的瓷磚。
性能
GeForce RTX 4090 GPU 在 0.8 毫秒到 0.95 毫秒之間照亮了 1920 x 1080 的場景,而 Uber 著色器調度技術則需要 0.98 毫秒。下面將詳細介紹這些因素。
- 工作圖形執行不是免費的。管理圖形記錄和調度工作會產生相關成本,這些成本會吃掉工作圖形取得的部分收益。
- 使用工作圖形的光照性能更好地響應屏幕內容。當屏幕中包含大量天幕紋理時,光照通道的完成速度會更快。在這種情況下,屏幕中包含網格的屏幕與屏幕中包含網格的一半的屏幕 (視圖不同) 的性能差異大約為 0.2 毫秒。超級著色器的性能不能很好地響應屏幕內容。它在各種視圖下呈現穩定的時間。
- 工作圖形中的節點著色器專門用于處理每個 BRDF,而超級著色器則必須處理所有可能的 BRDF。因此,節點著色器更有可能通過編譯器優化。
- BRDF 節點著色器可以在根節點分類瓷磚后立即啟動。超級著色器技術涉及資源屏障分離的兩次調度,這意味著第二次調度只能在第一次調度完成后啟動。
這些結果反映了我在使用工作圖形的冒險中學到的一個教訓,即性能提升必須超過工作圖形執行所產生的開銷,以便在性能方面實現盈余。示例展示了延遲著色通道如何受益于工作圖形,盡管這種工作圖形版本僅限于計算著色器。
內容串流游戲引擎
本節將探討使用工作圖形的渲染器如何支持大型游戲世界。考慮一下支持藝術家創作材質著色器的引擎。多 BRDF 概念僅適用于材質本身,每種材質都有自己的著色器,執行其獨特的計算,甚至整個 BRDF。
當玩家在游玩游戲或移動游戲世界的不同部分時,游戲中的其他內容逐漸加載材質時,可能會出現問題。這通常被稱為內容串流從圖形編程的角度來看,它涉及實時加載資源,包括紋理、網格和材質。
在處理整個場景所有材質的單個工作圖形方案中,如何在運行期間根據需要增加圖形來處理更多材質?
一種簡單的方法是完全重構圖形中的 HLSL 代碼,并將新材質的著色器代碼注入其中。這不僅會導致大量極其緩慢的字符操作,而且編譯成本可能過高,從而導致游戲中出現明顯的卡頓現象。請勿采用這種方法。
一種更為成熟的方法是完全重新創建圖形,并為新材質添加預編譯的 DXIL 庫。
理想的方法是使用 AddToStateObject API,該 API 用于在光線追蹤應用程序中支持流式傳輸場景。Working Graphics 使得通過稀疏節點輸出數組可以輕松擴展任何特定生產者的目標節點。
在這種情況下,負責材質分類的節點可以將目標輸出聲明為稀疏輸出數組。數組的每個輸出都映射到一個表示特定材質著色器的節點,而這些節點可以通過動態選擇的整數值索引。有關詳細信息,請參閱 DirectX 規格 以了解如何使用此功能。
推薦內容
在使用工作圖之后,我收集了一些學習和建議,這些學習和建議應該有助于讓流程更有趣,并減少不愉快的驚喜。
- 在設計或調整現有算法以處理圖形時,了解從上到下傳輸的數據的心智模型,從而推動可能擴展的工作。
- 工作圖形擅長根據不同的條件執行不同的著色器。避免使用超級著色器節點。相反,將著色器分解為單個更簡單的特殊節點著色器,這些特殊節點著色器可以受益于減少的寄存器壓力和更少的執行偏差。
- 致力于節點著色器,而不是小型操作集合。否則,工作圖形的成本將主要受到執行開銷的影響。
- 盡可能避免在圖形中對相同資源進行 UAV 讀取和寫入。這些資源需要
globallycoherent以保證正確性,但這個指針也會對此類資源的訪問速度產生很大影響。使用記錄在節點之間傳輸工作數據。 - 對于直播啟動節點,如果可以靜態確定調度大小,則使用
NodeDispatchGrid指定尺寸,而不是將網格尺寸作為SV_DispatchGrid輸入記錄中的值。請記住,可以覆蓋NodeDispatchGrid并根據屏幕分辨率和其他質量設置等某些運行時條件進行調整。 - 盡可能保持屬性中指定的數字,例如
NodeMaxDispatchGrid和MaxRecords盡可能緊密。了解工作圖形的各個節點的廣播/聚合性質,并使用這種了解來確定工作大小估算的合適值。這應該有助于減少圖形所需的背景內存大小。 - 考慮將節點輸出標記為
MaxRecordsSharedWith屬性。一個顯而易見且常見的例子是,如果生產節點線程將一個輸出記錄寫入其中一個子節點中。 - 盡早在著色器中輸出節點記錄,并使用
OutputComplete以標記完成。這有助于改善占用率。 - 首先簡單地驗證每個步驟是否正確,然后再添加代碼以啟動下一個節點。很容易出錯,尤其是在請求輸出記錄時。由于工作圖形是一項新功能,因此調試工具尚未達到最佳狀態。
分析和調試工具
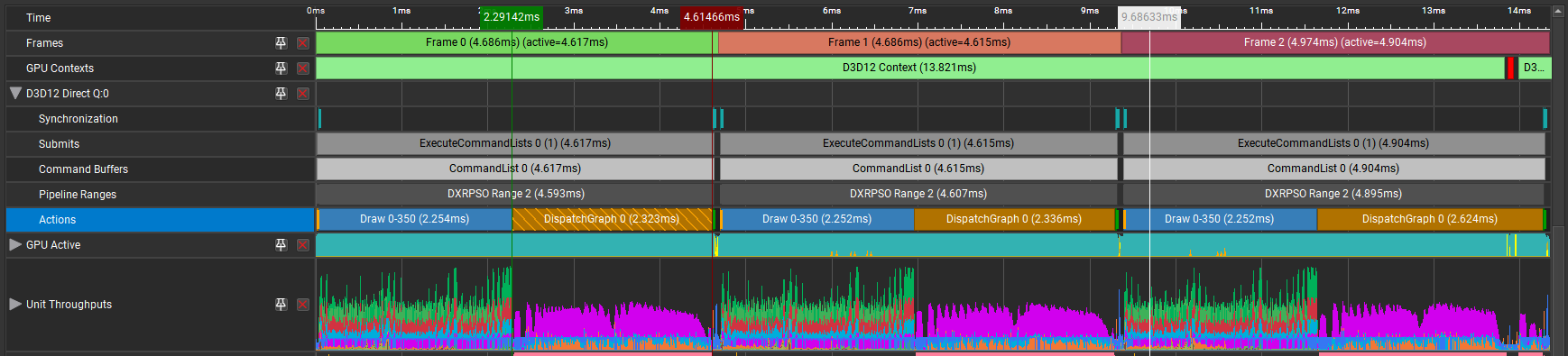
NVIDIA Nsight Graphics 為分析和調試圖形應用程序提供全面支持。它公開渲染管線并可視化工作負載,幫助您識別和解決優化需求。
您可以在 Nsight Graphics 幀調試器中檢查 D3D12 工作圖,該調試器可以逐幀檢查 GPU 進程。通過捕獲和重放工作圖,幀調試器可以顯示 API 參數、資源綁定和內存緩沖區的內容。
函數 DispatchGraph 將工作圖形推送到 GPU,并協調圖形結構中任務的執行方式,從而實現高效并行性和任務依賴性管理。此功能在 Nsight Graphics GPU Trace 中以時間軸事件的形式顯示,因此您可以查看 GPU 的性能指標。
未來方向
許多算法都涉及大量獨立數據通過一系列步驟流動,并在各個步驟進行擴展。處理層次數據的算法是實現工作圖的理想候選者。例如,從虛擬場景到可見區域,再到處理和轉換網格,最后到三角形光柵化,這一過程可以在單個工作圖中很好地實現。
盡管目前工作圖形僅限于計算著色器,但可以在計算中甚至使用 內聯光線追蹤。隨著工作圖形添加向光柵化器提交三角形的支持,這應該不再成為問題。
工作圖形邁出了邁向完全由 GPU 驅動的幀處理的巨大步驟。但是,一個工作圖不可能表達整個幀的工作 (例如,剔除、光柵化 G 緩沖區、照明和后期處理)。雖然一個工作圖可以表示多個幀的渲染步驟,但仍有一些操作無法在單個工作圖中高效完成。操作時出現的問題包括:
- 在圖形執行期間如何管理資源狀態?
- 如何將三角形提交至硬件光柵化器?三角形光柵化后的工作圖形是否可以繼續運行?
- 如何表示多通道算法 (例如后處理鏈)?
直到這些問題得到解決,CPU 將繼續在幀序列中發揮主導作用。現在,我們可以將更多的數據依賴性步驟完全移至 GPU,從而使 CPU 得以釋放用于管理場景剔除和推送命令的所有可見對象的任務。因此,我們尚未達到 CPU 只提交一個調用DispatchGraph來繪制整個幀,但這個版本的工作圖形有助于將更多部分的幀轉換為 GPU 驅動,從而減少 CPU 會成為應用程序性能瓶頸的情況。
總結
本帖子探討了一個具體的使用案例,該案例可以利用 Direct3D 12 中工作圖形的功能來調整現有渲染算法。此外,我還討論了關于工作圖形的一些高級主題,包括性能注意事項和流式傳輸游戲引擎的操作。我還介紹了 NVIDIA Nsight Graphics 的最新版本中對工作圖形的支持。如需了解構建和運行工作圖形所需的所有詳細信息,請訪問 NVIDIAGameWorks/donut_examples 項目在 GitHub 上提供。
致謝
感謝 NVIDIA Nsight Graphics 團隊的 Avinash Baliga 和 Robert Jensen 對本文的貢獻。






