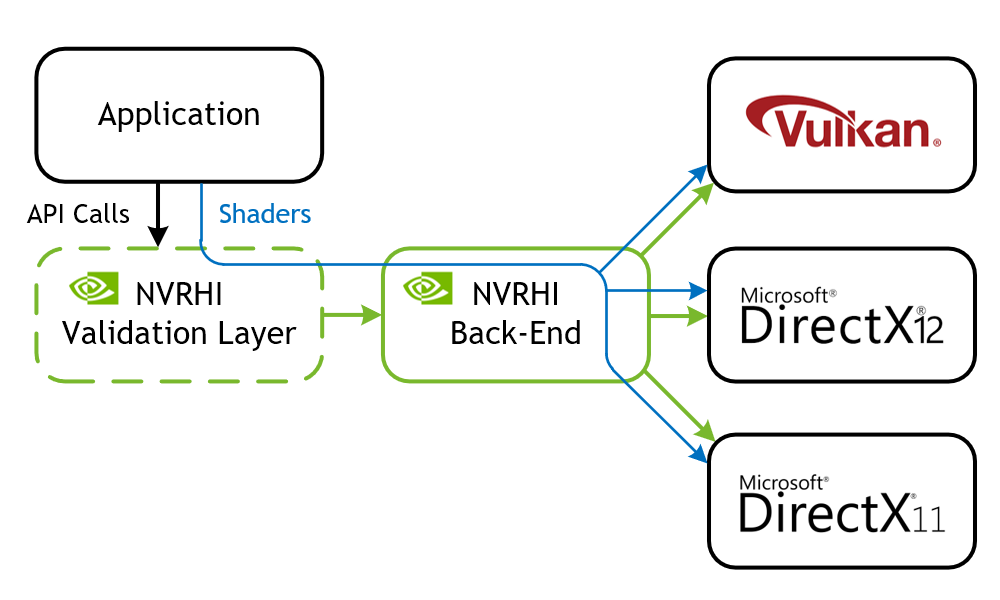
現代圖形 API ,如 Direct3D 12 和 Vulkan ,旨在提供對 GPU 的較低級別訪問,并消除與 API 轉換相關的 GPU 驅動程序開銷。此低級接口允許應用程序對系統進行更多控制,并提供以最適合每個應用程序的方式管理管道、著色器編譯、內存分配和資源描述符的能力。
另一方面,這更接近于對 GPU 的硬件訪問,這意味著應用程序必須自己管理這些東西,而不是依賴 GPU 驅動程序。使用這些 API 繪制單個三角形的基本“ hello world ”程序可以擴展到 1000 行或更多代碼。在復雜的渲染器中,如果不系統地管理 GPU 內存、描述符等,可能會很快變得難以控制。
如果應用程序或引擎必須使用多個圖形 API ,可以通過兩種方式完成:
- 復制渲染代碼以分別使用每個 API 。這種方法有一個明顯的缺點,就是必須開發和維護多個獨立的實現。
- 在圖形 API 上實現一個抽象層,在公共接口中提供必要的功能。這在開發和維護抽象層方面有一個不同的缺點。大多數主要的游戲引擎都實現了第二種方法。
NVIDIA 渲染硬件接口( NVRHI )是一個處理這些缺點的庫。它定義了一個定制的、更高級的圖形 API ,可以很好地映射到三個受支持的本機圖形 API : Vulkan 、 D3D12 和 D3D11 。它以安全、自動的方式管理資源、管道、描述符和屏障,必要時可以輕松禁用或繞過這些資源,以減少 CPU 開銷。除此之外, NVRHI 還提供了一個驗證層,以確保應用程序正確使用 API ,類似于 Direct3D 調試運行時或 Vulkan 驗證層的功能,但在更高的級別上。
NVRHI 沒有提供一些與便攜性相關的功能。首先,它不會在運行時編譯著色器或讀取著色器反射數據以動態綁定資源。事實上, NVRHI 根本不在運行時處理著色器。該應用程序提供特定于平臺的著色器二進制文件,即 DXBC 、 DXIL 或 SPIR-V blob 。 NVRHI 將其直接傳遞給底層圖形 API 。匹配綁定布局由應用程序決定,并由底層圖形 API 驗證。其次, NVRHI 不創建圖形設備或窗口。這也取決于應用程序或其他庫,如GLFW。
在本文中,我將介紹 NVRHI 的主要功能,并解釋每個功能如何幫助圖形工程師提高工作效率和編寫更安全的代碼。
- 資源生命周期管理
- 綁定布局和綁定集
- 自動資源狀態跟蹤
- 上傳管理
- 與圖形 API 的交互
- 著色器置換
資源生命周期管理
在 Vulkan 和 D3D12 中,應用程序必須注意僅銷毀 GPU 不再使用的設備資源。如果仔細規劃資源使用情況,這可以用很少的開銷完成,但問題在于規劃。
NVRHI 幾乎完全遵循 D3D11 資源生命周期模型。資源(如緩沖區、紋理或管道)具有引用計數。復制資源句柄時,引用計數將遞增。當句柄被銷毀時,引用計數將遞減。當最后一個句柄被銷毀并且引用計數達到零時,資源對象被銷毀,包括底層圖形 API 資源。但 D3D12 也是這么做的,對嗎?不完全是。
NVRHI 還保留對命令列表中使用的資源的內部引用。打開命令列表進行錄制時,將創建命令列表的新實例。該實例保存對其使用的每個資源的引用。當命令列表關閉并提交以供執行時,實例與圍欄或信號量值一起存儲在隊列中,可用于確定實例是否已在 GPU 上完成執行。之后可以立即重新打開相同的命令列表進行錄制,即使之前的實例仍在 GPU 上執行。
應用程序應該偶爾調用nvrhi::IDevice::runGarbageCollection方法,每幀至少調用一次。此方法查看正在運行的命令列表實例隊列,并清除已完成執行的實例。清除實例會自動刪除對實例中使用的資源的內部引用。如果一個資源沒有剩下其他引用,它將在那個時候被銷毀。
此行為可通過以下代碼示例顯示:
{
// Create a buffer in a scope, which starts with reference count of 1
nvrhi::BufferHandle buffer = device->createBuffer(...);
// Creates an internal instance of the command list
commandList->open();
// Adds a buffer reference to the instance, which increases reference count to 2
commandList->clearBufferUInt(buffer, 0);
commandList->close();
// The local reference to the buffer is released here, decrements reference count to 1
}
// Puts the command list instance into the queue
device->executeCommandList(commandList);
// Likely doesn't do anything with the instance
// because it's just been submitted and still executing on the GPU
device->runGarbageCollection();
device->waitForIdle();
// This time, the buffer should be destroyed because
// waitForIdle ensures that all command list instances
// have finished executing, so when the finished instance
// is cleared, the buffer reference count is decremented to zero
// and it can be safely destroyed
device->runGarbageCollection();
與 D3D12 和 Vulkan 不同,在 NVRHI 中,當應用程序創建資源、使用資源并立即釋放資源時,此處顯示的“觸發并忘記”模式非常好。
如果應用程序執行多個draw調用,并且為每個draw調用綁定了大量資源,那么這種類型的資源跟蹤是否會變得昂貴。不是真的。Draw調用和分派不處理單個資源。紋理和緩沖區被分組為不可變的綁定集,這些綁定集被創建,保存對其資源的永久引用,并作為單個對象進行跟蹤。
因此,當在命令列表中使用某個綁定集時,命令列表實例僅存儲對該綁定集的引用。如果綁定集已綁定,則跳過該存儲,以便使用相同綁定重復調用 draw 不會增加跟蹤成本。我將在下一節更詳細地解釋綁定集。
另一個有助于減少資源生存期跟蹤帶來的 CPU 開銷的方法是綁定集和加速結構上的trackLiveness設置。當此參數設置為false時,不會為該特定資源創建內部引用。在這種情況下,應用程序負責保留自己的引用,而不是在資源使用時釋放它。
綁定布局和綁定集
NVRHI 具有獨特的資源綁定模型,旨在實現安全性和運行效率。如前所述,圖形或計算管道使用的各種資源被分組到綁定集中。
簡言之,綁定集是綁定到管道中特定插槽的資源視圖數組。例如,綁定集可能包含綁定到插槽t1的結構化緩沖區 SRV 、綁定到插槽u0的單個紋理 mip 級別的 UAV 以及綁定到插槽b2的常量緩沖區。集合中的所有綁定共享相同的可見性遮罩(著色器階段將看到該綁定)和寄存器空間,兩者都由綁定布局指定。
綁定布局是 D3D12 根簽名和 Vulkan 描述符集布局的 NVRHI 版本。綁定布局類似于綁定集的模板。它聲明哪些資源類型綁定到哪些插槽,但不說明使用了哪些特定資源。
與根簽名和描述符集布局一樣, NVHRI 綁定布局用于創建管道。可以使用多個綁定布局創建單個管道。根據資源的修改頻率將資源分為不同的組,或者將不同的資源集綁定到不同的管道階段,這些都很有用。
以下代碼示例顯示了如何使用一個綁定布局創建基本計算管道:
auto layoutDesc = nvrhi::BindingLayoutDesc()
.setVisibility(nvrhi::ShaderType::All)
.addItem(nvrhi::BindingLayoutItem::Texture_SRV(0)) // texture at t0
.addItem(nvrhi::BindingLayoutItem::ConstantBuffer(2)); // constants at b2
// Create a binding layout.
nvrhi::BindingLayoutHandle bindingLayout = device->createBindingLayout(layoutDesc);
auto pipelineDesc = nvrhi::ComputePipelineDesc()
.setComputeShader(shader)
.addBindingLayout(bindingLayout);
// Use the layout to create a compute pipeline.
nvrhi::ComputePipelineHandle computePipeline = device->createComputePipeline(pipelineDesc);
只能從匹配的綁定布局創建綁定集。匹配意味著布局必須具有相同數量、相同類型、綁定到相同插槽、順序相同的項目。這看起來可能是冗余的, D3D12 和 Vulkan API 在其描述符系統中的冗余更少。這種冗余非常有用:它使代碼更加明顯,并且允許 NVRHI 驗證層捕獲更多的 bug 。
auto bindingSetDesc = nvrhi::BindingSetDesc()
// An SRV for two mip levels of myTexture.
// Subresource specification is optional, default is the entire texture.
.addItem(nvrhi::BindingSetItem::Texture_SRV(0, myTexture, nvrhi::Format::UNKNOWN,
nvrhi::TextureSubresourceSet().setBaseMipLevel(2).setNumMipLevels(2)))
.addItem(nvrhi::BindingSetItem::ConstantBuffer(2, constantBuffer));
// Create a binding set using the layout created in the previous code snippet.
nvrhi::BindingSetHandle bindingSet = device->createBindingSet(bindingSetDesc, bindingLayout);
由于綁定集描述符也包含創建綁定布局所需的幾乎所有信息,因此可以通過一個函數調用同時創建這兩個信息。這在創建僅需要一個綁定集的某些渲染過程時可能很有用。
#include <nvrhi/utils.h>
...
nvrhi::BindingLayoutHandle bindingLayout;
nvrhi::BindingSetHandle bindingSet;
nvrhi::utils::CreateBindingSetAndLayout(device, /* visibility = */ nvrhi::ShaderType::All,
/* registerSpace = */ 0, bindingSetDesc, /* out */ bindingLayout, /* out */ bindingSet);
// Now you can create the pipeline using bindingLayout.
綁定集是不可變的。創建綁定集時, NVRHI 從 D3D12 上的堆中分配描述符,或在 Vulkan 上創建描述符集,并用必要的資源視圖填充它。
稍后,當綁定集用于繪制或分派調用時,綁定操作是輕量級的,并轉換為相應的圖形 API 綁定調用。渲染時不會創建或復制描述符。
自動資源狀態跟蹤
在 D3D12 和 Vulkan API 中,改變資源狀態并在圖形管道中引入依賴關系的顯式屏障都是一個重要部分。它們允許應用程序最小化管道依賴項和氣泡的數量,并優化它們的位置。通過從驅動程序中刪除該邏輯,它們同時減少了 CPU 開銷。這主要與繪制大量幾何體的緊密渲染循環有關。大多數情況下,尤其是在編寫新的渲染代碼時,處理障礙非常煩人且容易出現錯誤。
NVHRI 實現了一個系統,該系統跟蹤每個資源的狀態,以及每個命令列表的子資源(可選)。當命令與資源交互時,資源將轉換為該命令所需的狀態(如果尚未處于該狀態)。例如,writeTexture命令將紋理轉換為CopyDest狀態,隨后從紋理讀取的繪制操作將紋理轉換為ShaderResources狀態。
當兩個連續命令的資源處于UnorderedAccess狀態時,將應用特殊處理:不涉及轉換,但在命令之間插入無人機屏障。如有必要,可以暫時禁用無人機屏障的插入。
我前面說過, NVRHI 會根據每個命令列表跟蹤每個資源的狀態。應用程序可以以任意順序或并行方式記錄多個命令列表,并在每個命令列表中以不同方式使用相同的資源。因此,您無法全局或每個設備跟蹤資源狀態,因為在記錄命令列表時需要導出屏障。執行命令列表時,全局跟蹤可能不會按照與設備命令隊列上實際資源使用情況相同的順序進行。
因此,您可以分別跟蹤每個命令列表中的資源狀態。在某種意義上,這可以看作是一個微分方程。您知道命令列表中的狀態是如何變化的,但不知道邊界條件,也就是說,當您按執行順序進入和退出命令列表時,每個資源都處于哪個狀態。
應用程序必須為每個資源提供邊界條件。有兩種方法可以做到這一點:
- Explicit:打開命令列表后使用
beginTrackingTextureState和beginTrackingBufferState功能,關閉命令列表前使用setTextureState和setBufferState功能。 - Automatic:創建資源時使用
TextureDesc和BufferDesc結構的initialState和keepInitialState字段。然后,使用資源的每個命令列表在進入命令列表時都假定它處于初始狀態,并在離開命令列表之前將其轉換回初始狀態。
在這里,您 MIG 想知道如何避免資源狀態跟蹤的 CPU 開銷,或者手動優化屏障放置。好吧,你可以!命令列表具有setEnableAutomaticBarriers功能,可完全禁用自動安全柵。在此模式下,在需要屏障的位置使用setTextureState和setBufferState功能。它仍然使用相同的狀態跟蹤邏輯,但頻率可能更低。
上傳管理
NVRHI 自動化了現代圖形 API 的另一個方面,這一點通常很煩人。這就是 GPU 對上傳緩沖區的管理和對其使用情況的跟蹤。
通常,當必須從 CPU 對每幀或每幀多次更新某些紋理或緩沖區時,會分配一個分級緩沖區,其大小比資源內存需求大數倍。這將在 GPU 上啟用多個正在運行的幀。或者,大型暫存緩沖區的部分在運行時進行子分配。使用 NVRHI 實現相同的策略是可能的,但是有一個內置的實現可以很好地適用于大多數用例。
每個 NVRHI 命令列表都有自己的上載管理器。調用writeBuffer或writeTexture時,上載管理器會嘗試查找 GPU 不再使用的現有緩沖區,該緩沖區可以容納必要的數據。如果沒有可用的緩沖區,將創建一個新的緩沖區并將其添加到上載管理器的池中。將提供的數據復制到該緩沖區中,然后將復制命令添加到命令列表中。 GPU 使用的緩沖區的跟蹤是自動執行的。
ConstantBufferStruct myConstants; myConstants.member = value; // This is all that's necessary to fill the constant buffer with data and have it ready for rendering. commandList->writeBuffer(constantBuffer, myConstants, sizeof(myConstants));
上載管理器從不釋放其緩沖區,也不會與其他命令列表共享緩沖區。也許一個應用程序正在進行大量的上傳,例如在場景加載期間,然后切換到上傳強度較小的操作模式。在這種情況下,最好為上傳活動創建一個單獨的命令列表,并在上傳完成后釋放它。這將釋放與命令列表關聯的上載緩沖區。
無需等待 GPU 完成從上載緩沖區復制數據。在復制完成之前,前面描述的資源生存期跟蹤系統不會釋放上載緩沖區。
與圖形 API 的交互
有時,有必要避開抽象層,直接使用底層圖形 API 進行操作。也許您必須使用 NVRHI 不支持的某些功能,在示例應用程序中演示一些 API 用法,或者使可移植呈現代碼與來自其他地方的本機資源一起工作。 NVRHI 使做這些事情相對容易。
每個 NVRHI 對象都有一個getNativeObject函數,該函數返回所需類型的底層 API 資源。預期的類型被傳遞給該函數,如果該類型可用,它只返回非 NULL 值,以提供某種類型安全性。
支持的類型包括ID3D11Device或ID3D12Resource等接口和vk::Image等句柄。此外, NVRHI 紋理對象具有getNativeView功能,可以創建和返回紋理視圖,如 SRV 或 UAV 。
例如,為了在 NVRHI 命令列表的中間發布一些本地的 D3D12 渲染命令,您 MIG HT 使用代碼,如下面的示例:
ID3D12GraphicsCommandList* d3dCmdList = nvrhiCommandList->getNativeObject(
nvrhi::ObjectTypes::D3D12_GraphicsCommandList);
D3D12_CPU_DESCRIPTOR_HANDLE d3dTextureRTV = nvrhiTexture->getNativeView(
nvrhi::ObjectTypes::D3D12_RenderTargetViewDescriptor);
const float clearColor[4] = { 0.f, 0.f, 0.f, 0.f };
d3dCmdList->ClearRenderTargetView(d3dTextureRTV, clearColor, 0, nullptr);
著色器置換
這里要提到的最后一個生產力特性是 NVRHI 附帶的批處理著色器編譯器。這是一項可選功能,沒有它, NVRHI 完全可以正常工作。 NVRHI 接受通過其他方式編譯的著色器。盡管如此,它還是一個有用的工具。
通常需要使用多個預處理器定義組合編譯同一著色器。但是,例如, VisualStudio 為著色器編譯提供的本機工具根本無法輕松完成此任務。
NVRHI 著色器編譯器正好解決了這個問題。由列出著色器源文件和編譯選項的文本文件驅動,它生成選項排列并調用底層編譯器( DXC 或 FXC )生成二進制文件。然后,同一著色器的不同版本的二進制文件被打包成一個自定義塊格式的文件,該文件可以使用<nvrhi/common/shader-blob.h>中聲明的函數進行處理。
應用程序可以加載包含所有著色器排列的文件,并將其連同預處理器定義及其值的列表一起傳遞給nvrhi::utils::createShaderPermutation或nvrhi::utils::createShaderLibraryPermutation。如果文件中存在請求的置換,則會創建相應的著色器對象。如果沒有,將生成一條錯誤消息。
除了置換處理之外,著色器編譯器還有其他很好的功能。首先,它掃描源文件以構建包含在每個文件中的標題樹。它檢測是否修改了任何標題,以及是否必須重建特定著色器。其次,它可以使用所有可用的 CPU 內核并行構建所有過時的著色器。
結論
在這篇文章中,我介紹了 NVRHI 的一些最重要的功能,在我看來,使用這些功能是一種樂趣。有關 NVHRI 的更多信息,請參閱NVIDIAGameWorks/nvrhi GitHub repo ,其中包括教程和更詳細的編程指南。GitHub 上的甜甜圈示例存儲庫有幾個用 NVRHI 編寫的完整應用程序。
如果您對 NVRHI 有任何疑問,請在 GitHub 上發布問題或在 Twitter 上向我發送消息(@more_fps)。
?