- Welcome
- Getting Started With the NVIDIA DriveWorks SDK
- Modules
- Samples
- Tools
- Tutorials
- SDK Porting Guide
- DriveWorks API
- More



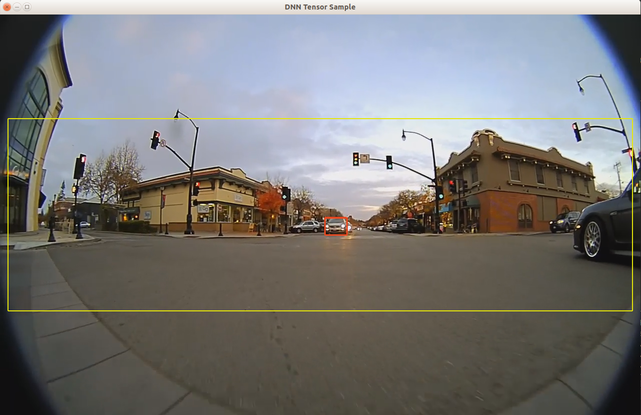
The Basic Object Detector Using DNN Tensor sample demonstrates how the DNN Interface can be used for object detection using dwDNNTensor.
The sample streams a H.264 or RAW video and runs DNN inference on each frame to detect objects using NVIDIA® TensorRT™ model.
The interpretation of the output of a network depends on the network design. In this sample, 2 output blobs (with coverage and bboxes as blob names) are interpreted as coverage and bounding boxes.
For each frame, it detects the object locations, uses dwDNNTensorStreamer to get the output of the inference from GPU to CPU, and finally traverses through the tensor to extract the detections.
The Basic Object Detector Using dwDNNTensor sample, sample_dnn_tensor, accepts the following optional parameters. If none are specified, it performs detections on a supplied pre-recorded video.
./sample_dnn_tensor --input-type=[video|camera]
--video=[path/to/video]
--camera-type=[camera]
--camera-group=[a|b|c|d]
--camera-index=[0|1|2|3]
--tensorRT_model=[path/to/TensorRT/model]
Where:
--input-type=[video|camera]
Defines if the input is from live camera or from a recorded video.
Live camera is supported only on NVIDIA DRIVE platforms.
Default value: video
--video=[path/to/video]
Specifies the absolute or relative path of a raw or h264 recording.
Only applicable if --input-type=video
Default value: path/to/data/samples/sfm/triangulation/video_0.h264.
--camera-type=[camera]
Specifies a supported AR0231 `RCCB` sensor.
Only applicable if --input-type=camera.
Default value: ar0231-rccb-bae-sf3324
--camera-group=[a|b|c|d]
Specifies the group where the camera is connected to.
Only applicable if --input-type=camera.
Default value: a
--camera-index=[0|1|2|3]
Specifies the camera index on the given port.
Default value: 0
--tensorRT_model=[path/to/TensorRT/model]
Specifies the path to the NVIDIA<sup>®</sup> TensorRT<sup>™</sup>
model file.
The loaded network is expected to have a coverage output blob named "coverage" and a bounding box output blob named "bboxes".
Default value: path/to/data/samples/detector/<gpu-architecture>/tensorRT_model.bin, where <gpu-architecture> can be `pascal` or `volta-discrete` or `volta-integrated` or `turing`.
data/samples/detector/pascal/tensorRT_model.bin.json
./sample_dnn_tensor
The video file must be a H.264 or RAW stream. Video containers such as MP4, AVI, MKV, etc. are not supported.
./sample_dnn_tensor --input-type=video --video=<video file.h264/raw> --tensorRT_model=<TensorRT model file>
./sample_dnn_tensor --input-type=camera --camera-type=<rccb_camera_type> --camera-group=<camera group> --camera-index=<camera idx on camera group> --tensorRT_model=<TensorRT model file>
where <rccb_camera_type> is a supported RCCB sensor. See Cameras Supported for the list of supported cameras for each platform.
The sample creates a window, displays the video streams, and overlays detected bounding boxes of the objects.
The color coding of the overlay is:
For more information, see: